 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD-Quant: Post-Training Quantization based on Prediction Difference Metric
Paper and Code
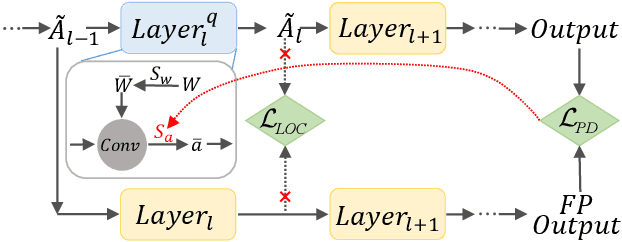
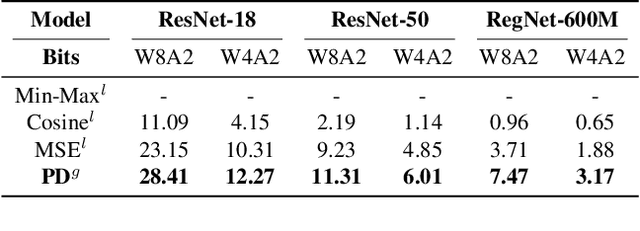

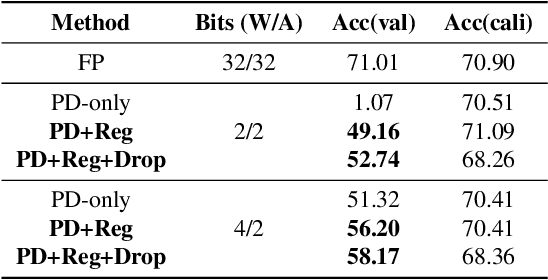
As a neural network compression technique, post-training quantization (PTQ) transforms a pre-trained model into a quantized model using a lower-precision data type. However, the prediction accuracy will decrease because of the quantization noise, especially in extremely low-bit settings. How to determine the appropriate quantization parameters (e.g., scaling factors and rounding of weights) is the main problem facing now. Many existing methods determine the quantization parameters by minimizing the distance between features before and after quantization. Using this distance as the metric to optimize the quantization parameters only considers local information. We analyze the problem of minimizing local metrics and indicate that it would not result in optimal quantization parameters. Furthermore, the quantized model suffers from overfitting due to the small number of calibration samples in PTQ. In this paper, we propose PD-Quant to solve the problems. PD-Quant uses the information of differences between network prediction before and after quantization to determine the quantization parameters. To mitigate the overfitting problem, PD-Quant adjusts the distribution of activations in PTQ. Experiments show that PD-Quant leads to better quantization parameters and improves the prediction accuracy of quantized models, especially in low-bit settings. For example, PD-Quant pushes the accuracy of ResNet-18 up to 53.08% and RegNetX-600MF up to 40.92% in weight 2-bit activation 2-bit. The code will be released at https://github.com/hustvl/PD-Quant.