 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Post-Training Quantization on Object Detection with Task Loss-Guided Lp Metric
Paper and Code
Apr 25, 2023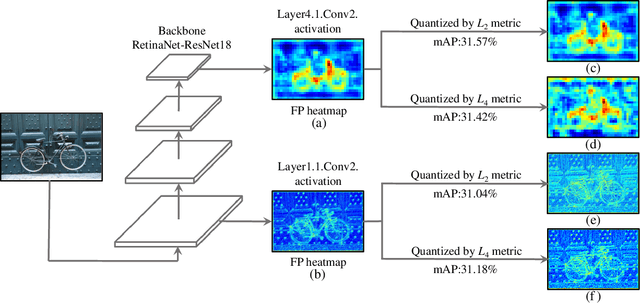

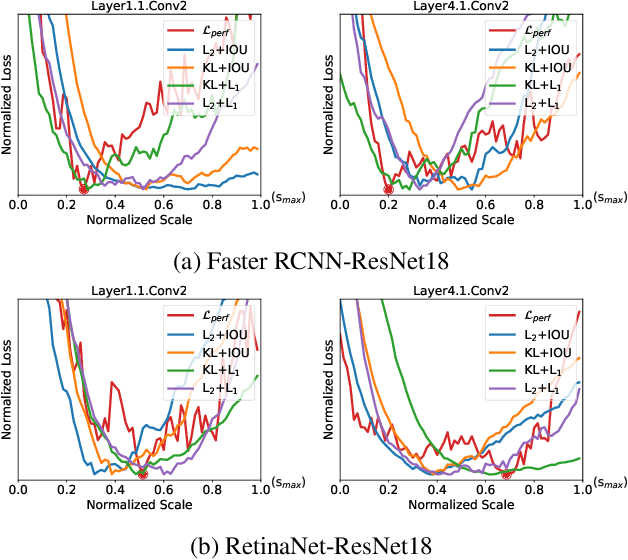

Efficient inference for object detection networks is a major challenge on edge devices. Post-Training Quantization (PTQ), which transforms a full-precision model into low bit-width directly, is an effective and convenient approach to reduce model inference complexity. But it suffers severe accuracy drop when applied to complex tasks such as object detection. PTQ optimizes the quantization parameters by different metrics to minimize the perturbation of quantization. The p-norm distance of feature maps before and after quantization, Lp, is widely used as the metric to evaluate perturbation. For the specialty of object detection network, we observe that the parameter p in Lp metric will significantly influence its quantization performance. We indicate that using a fixed hyper-parameter p does not achieve optimal quantization performance. To mitigate this problem, we propose a framework, DetPTQ, to assign different p values for quantizing different layers using an Object Detection Output Loss (ODOL), which represents the task loss of object detection. DetPTQ employs the ODOL-based adaptive Lp metric to select the optimal quantization parameters. Experiments show that our DetPTQ outperforms the state-of-the-art PTQ methods by a significant margin on both 2D and 3D object detectors. For example, we achieve 31.1/31.7(quantization/full-precision) mAP on RetinaNet-ResNet18 with 4-bit weight and 4-bit activation.