 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalMoE: Mixture-of-Experts Enhanced Encrypted Malicious Traffic Detection Under Graph Drift
Feb 10, 2026Encryption has been commonly used in network traffic to secure transmission, but it also brings challenges for malicious traffic detection, due to the invisibility of the packet payload. Graph-based methods are emerging as promising solutions by leveraging multi-host interactions to promote detection accuracy. But most of them face a critical problem: Graph Drift, where the flow statistics or topological information of a graph change over time. To overcome these drawbacks, we propose a graph-assisted encrypted traffic detection system, MalMoE, which applies Mixture of Experts (MoE) to select the best expert model for drift-aware classification. Particularly, we design 1-hop-GNN-like expert models that handle different graph drifts by analyzing graphs with different features. Then, the redesigned gate model conducts expert selection according to the actual drift. MalMoE is trained with a stable two-stage training strategy with data augmentation, which effectively guides the gate on how to perform routing. Experiments on open-source, synthetic, and real-world datasets show that MalMoE can perform precise and real-time detection.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
RomanTex: Decoupling 3D-aware Rotary Positional Embedded Multi-Attention Network for Texture Synthesis
Mar 24, 2025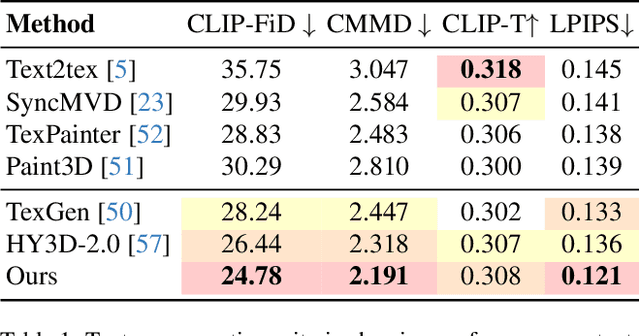

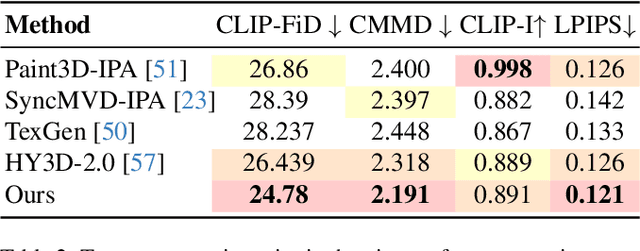

Painting textures for existing geometries is a critical yet labor-intensive process in 3D asset generation. Recent advancements in text-to-image (T2I) models have led to significant progress in texture generation. Most existing research approaches this task by first generating images in 2D spaces using image diffusion models, followed by a texture baking process to achieve UV texture. However, these methods often struggle to produce high-quality textures due to inconsistencies among the generated multi-view images, resulting in seams and ghosting artifacts. In contrast, 3D-based texture synthesis methods aim to address these inconsistencies, but they often neglect 2D diffusion model priors, making them challenging to apply to real-world objects To overcome these limitations, we propose RomanTex, a multiview-based texture generation framework that integrates a multi-attention network with an underlying 3D representation, facilitated by our novel 3D-aware Rotary Positional Embedding. Additionally, we incorporate a decoupling characteristic in the multi-attention block to enhance the model's robustness in image-to-texture task, enabling semantically-correct back-view synthesis. Furthermore, we introduce a geometry-related Classifier-Free Guidance (CFG) mechanism to further improve the alignment with both geometries and images. Quantitative and qualitative evaluations, along with comprehensive user studies, demonstrate that our method achieves state-of-the-art results in texture quality and consistency.
MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
Mar 13, 2025Physically-based rendering (PBR) has become a cornerstone in modern computer graphics, enabling realistic material representation and lighting interactions in 3D scenes. In this paper, we present MaterialMVP, a novel end-to-end model for generating PBR textures from 3D meshes and image prompts, addressing key challenges in multi-view material synthesis. Our approach leverages Reference Attention to extract and encode informative latent from the input reference images, enabling intuitive and controllable texture generation. We also introduce a Consistency-Regularized Training strategy to enforce stability across varying viewpoints and illumination conditions, ensuring illumination-invariant and geometrically consistent results. Additionally, we propose Dual-Channel Material Generation, which separately optimizes albedo and metallic-roughness (MR) textures while maintaining precise spatial alignment with the input images through Multi-Channel Aligned Attention. Learnable material embeddings are further integrated to capture the distinct properties of albedo and MR. Experimental results demonstrate that our model generates PBR textures with realistic behavior across diverse lighting scenarios, outperforming existing methods in both consistency and quality for scalable 3D asset creation.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Jun 11, 2024



Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021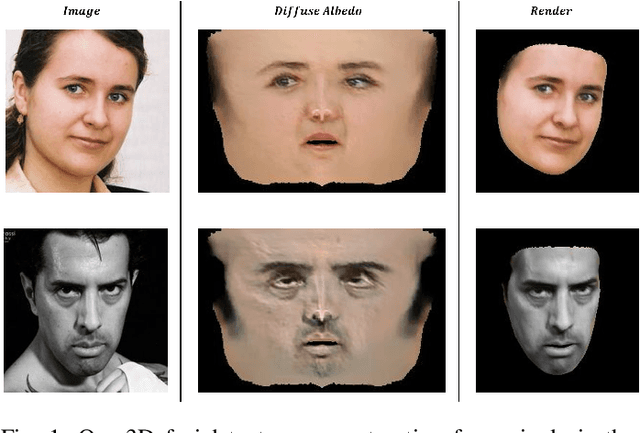

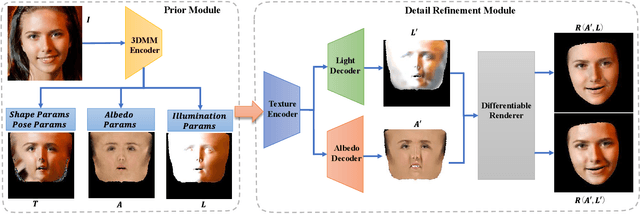

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.