 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse-View 3D Reconstruction: Recent Advances and Open Challenges
Jul 22, 2025Sparse-view 3D reconstruction is essential for applications in which dense image acquisition is impractical, such as robotics, augmented/virtual reality (AR/VR), and autonomous systems. In these settings, minimal image overlap prevents reliable correspondence matching, causing traditional methods, such as structure-from-motion (SfM) and multiview stereo (MVS), to fail. This survey reviews the latest advances in neural implicit models (e.g., NeRF and its regularized versions), explicit point-cloud-based approaches (e.g., 3D Gaussian Splatting), and hybrid frameworks that leverage priors from diffusion and vision foundation models (VFMs).We analyze how geometric regularization, explicit shape modeling, and generative inference are used to mitigate artifacts such as floaters and pose ambiguities in sparse-view settings. Comparative results on standard benchmarks reveal key trade-offs between the reconstruction accuracy, efficiency, and generalization. Unlike previous reviews, our survey provides a unified perspective on geometry-based, neural implicit, and generative (diffusion-based) methods. We highlight the persistent challenges in domain generalization and pose-free reconstruction and outline future directions for developing 3D-native generative priors and achieving real-time, unconstrained sparse-view reconstruction.
SARNet: Semantic Augmented Registration of Large-Scale Urban Point Clouds
Jun 27, 2022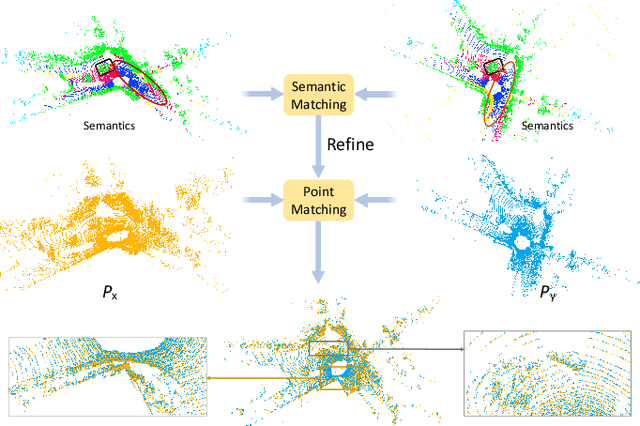
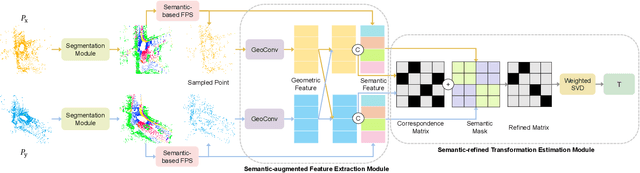
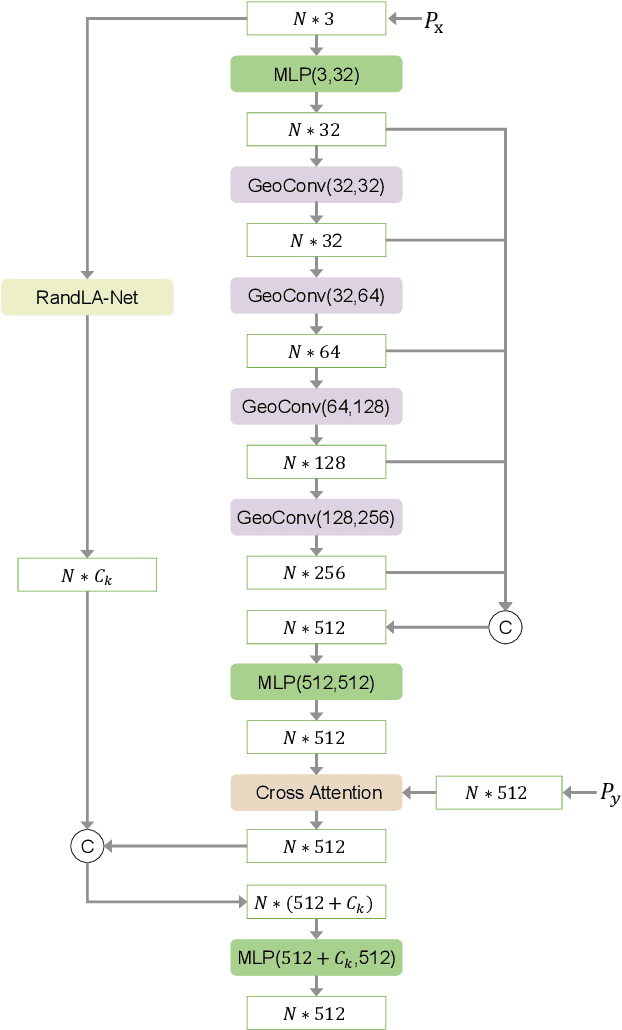
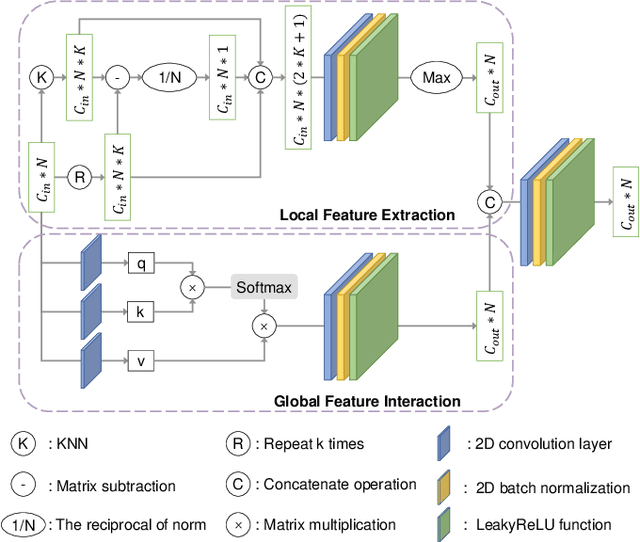
Registering urban point clouds is a quite challenging task due to the large-scale, noise and data incompleteness of LiDAR scanning data. In this paper, we propose SARNet, a novel semantic augmented registration network aimed at achieving efficient registration of urban point clouds at city scale. Different from previous methods that construct correspondences only in the point-level space, our approach fully exploits semantic features as assistance to improve registration accuracy. Specifically, we extract per-point semantic labels with advanced semantic segmentation networks and build a prior semantic part-to-part correspondence. Then we incorporate the semantic information into a learning-based registration pipeline, consisting of three core modules: a semantic-based farthest point sampling module to efficiently filter out outliers and dynamic objects; a semantic-augmented feature extraction module for learning more discriminative point descriptors; a semantic-refined transformation estimation module that utilizes prior semantic matching as a mask to refine point correspondences by reducing false matching for better convergence. We evaluate the proposed SARNet extensively by using real-world data from large regions of urban scenes and comparing it with alternative methods. The code is available at https://github.com/WinterCodeForEverything/SARNet.
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021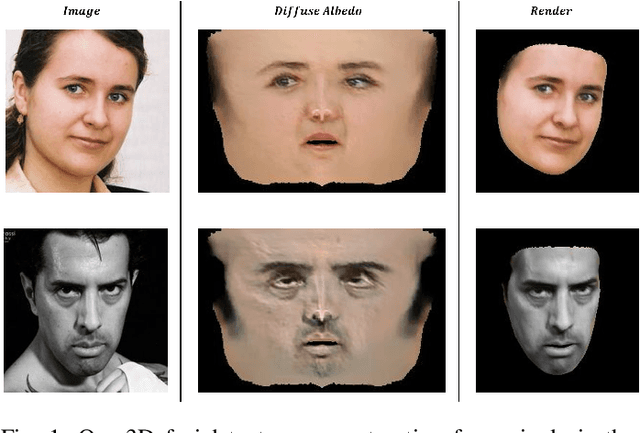

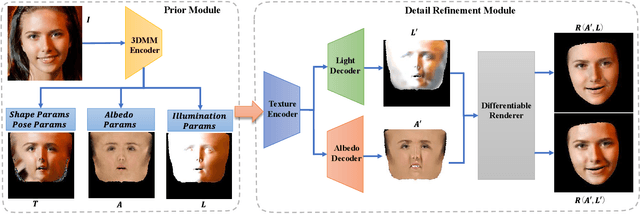

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.
SR-Net: Cooperative Image Segmentation and Restoration in Adverse Environmental Conditions
Nov 24, 2019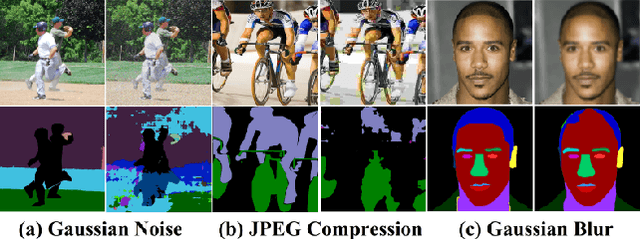
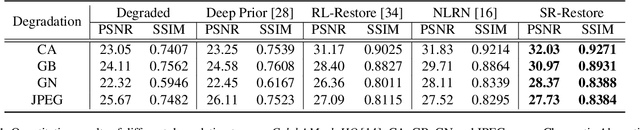
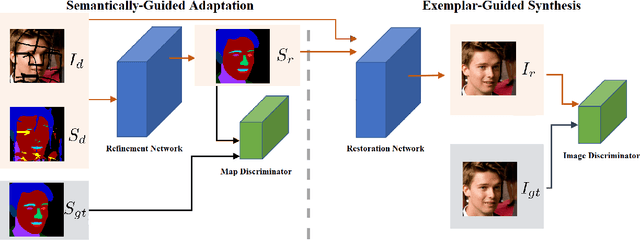
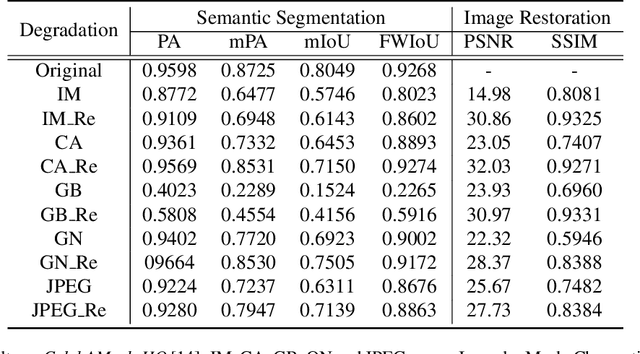
Most state-of-the-art semantic segmentation or scene parsing approaches only achieve high accuracy rates in good environmental conditions. The performance decrease enormously if images with unknown disturbances occur, which is less discussed but appears more in real applications. Most existing research works cast the handling of the challenging adverse conditions as a post-processing step of signal restoration or enhancement after sensing, then feed the restored images for visual understanding. However, the performance will largely depend on the quality of restoration or enhancement. Whether restoration-based approaches would actually boost the semantic segmentation performance remains questionable. In this paper, we propose a novel net framework to tackle semantic Segmentation and image Restoration in adverse environmental conditions (SR-Net). The proposed approach contains two components: Semantically-Guided Adaptation, which exploits and leverages semantic information from degraded images then help to refine the segmentation; and Exemplar-Guided Synthesis, which synthesizes restored or enhanced images from semantic label maps given specific degraded exemplars. SR-Net exploits the possibility of building connections of low-level image processing and high level computer vision tasks, achieving image restoration via segmentation refinement. Extensive experiments on several datasets demonstrate that our approach can not only improve the accuracy of high-level vision tasks with image adaption, but also boosts the perceptual quality and structural similarity of degraded images with image semantic guidance.