 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Paper and Code
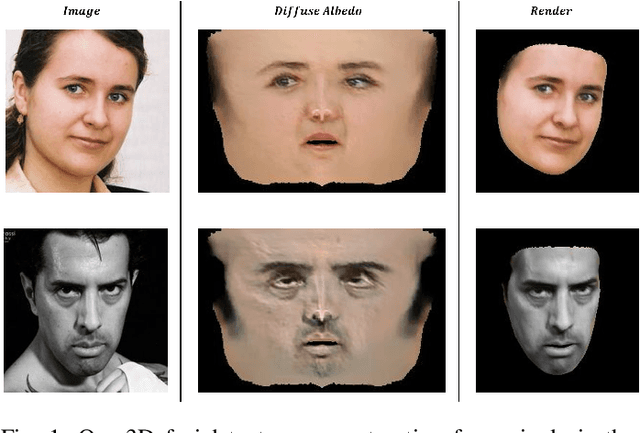

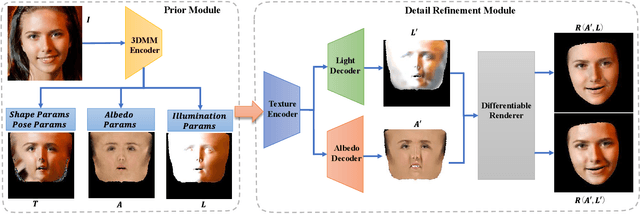

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.