 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Shift: Decoding Monetary Policy Stance from FOMC Statements with Large Language Models
Mar 15, 2026Federal Open Market Committee (FOMC) statements are a major source of monetary-policy information, and even subtle changes in their wording can move global financial markets. A central task is therefore to measure the hawkish--dovish stance conveyed in these texts. Existing approaches typically treat stance detection as a standard classification problem, labeling each statement in isolation. However, the interpretation of monetary-policy communication is inherently relative: market reactions depend not only on the tone of a statement, but also on how that tone shifts across meetings. We introduce Delta-Consistent Scoring (DCS), an annotation-free framework that maps frozen large language model (LLM) representations to continuous stance scores by jointly modeling absolute stance and relative inter-meeting shifts. Rather than relying on manual hawkish--dovish labels, DCS uses consecutive meetings as a source of self-supervision. It learns an absolute stance score for each statement and a relative shift score between consecutive statements. A delta-consistency objective encourages changes in absolute scores to align with the relative shifts. This allows DCS to recover a temporally coherent stance trajectory without manual labels. Across four LLM backbones, DCS consistently outperforms supervised probes and LLM-as-judge baselines, achieving up to 71.1% accuracy on sentence-level hawkish--dovish classification. The resulting meeting-level scores are also economically meaningful: they correlate strongly with inflation indicators and are significantly associated with Treasury yield movements. Overall, the results suggest that LLM representations encode monetary-policy signals that can be recovered through relative temporal structure.
QIME: Constructing Interpretable Medical Text Embeddings via Ontology-Grounded Questions
Mar 03, 2026While dense biomedical embeddings achieve strong performance, their black-box nature limits their utility in clinical decision-making. Recent question-based interpretable embeddings represent text as binary answers to natural-language questions, but these approaches often rely on heuristic or surface-level contrastive signals and overlook specialized domain knowledge. We propose QIME, an ontology-grounded framework for constructing interpretable medical text embeddings in which each dimension corresponds to a clinically meaningful yes/no question. By conditioning on cluster-specific medical concept signatures, QIME generates semantically atomic questions that capture fine-grained distinctions in biomedical text. Furthermore, QIME supports a training-free embedding construction strategy that eliminates per-question classifier training while further improving performance. Experiments across biomedical semantic similarity, clustering, and retrieval benchmarks show that QIME consistently outperforms prior interpretable embedding methods and substantially narrows the gap to strong black-box biomedical encoders, while providing concise and clinically informative explanations.
FlexMS is a flexible framework for benchmarking deep learning-based mass spectrum prediction tools in metabolomics
Feb 26, 2026The identification and property prediction of chemical molecules is of central importance in the advancement of drug discovery and material science, where the tandem mass spectrometry technology gives valuable fragmentation cues in the form of mass-to-charge ratio peaks. However, the lack of experimental spectra hinders the attachment of each molecular identification, and thus urges the establishment of prediction approaches for computational models. Deep learning models appear promising for predicting molecular structure spectra, but overall assessment remains challenging as a result of the heterogeneity in methods and the lack of well-defined benchmarks. To address this, our contribution is the creation of benchmark framework FlexMS for constructing and evaluating diverse model architectures in mass spectrum prediction. With its easy-to-use flexibility, FlexMS supports the dynamic construction of numerous distinct combinations of model architectures, while assessing their performance on preprocessed public datasets using different metrics. In this paper, we provide insights into factors influencing performance, including the structural diversity of datasets, hyperparameters like learning rate and data sparsity, pretraining effects, metadata ablation settings and cross-domain transfer learning analysis. This provides practical guidance in choosing suitable models. Moreover, retrieval benchmarks simulate practical identification scenarios and score potential matches based on predicted spectra.
KV-Embedding: Training-free Text Embedding via Internal KV Re-routing in Decoder-only LLMs
Jan 03, 2026While LLMs are powerful embedding backbones, their application in training-free settings faces two structural challenges: causal attention restricts early tokens from accessing subsequent context, and the next-token prediction objective biases representations toward generation rather than semantic compression. To address these limitations, we propose KV-Embedding, a framework that activates the latent representation power of frozen LLMs. Our method leverages the observation that the key-value (KV) states of the final token at each layer encode a compressed view of the sequence. By re-routing these states as a prepended prefix, we enable all tokens to access sequence-level context within a single forward pass. To ensure model-agnostic applicability, we introduce an automated layer selection strategy based on intrinsic dimensionality. Evaluations on MTEB across Qwen, Mistral, and Llama backbones show that KV-Embedding outperforms existing training-free baselines by up to 10%, while maintaining robust performance on sequences up to 4,096 tokens. These results demonstrate that internal state manipulation offers an efficient alternative to input modification, and we hope this work encourages further exploration of LLM internals for representation learning.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
PersonaFuse: A Personality Activation-Driven Framework for Enhancing Human-LLM Interactions
Sep 09, 2025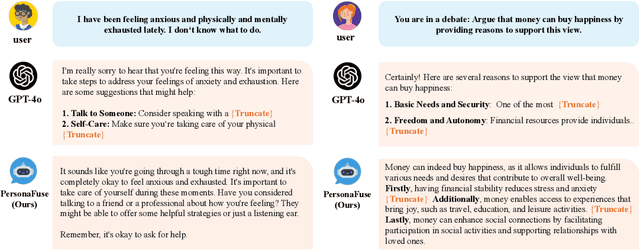

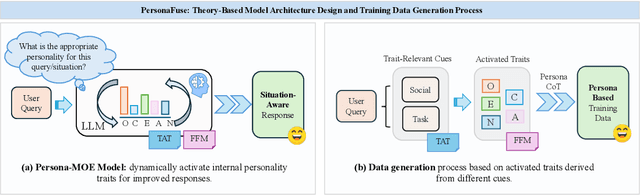
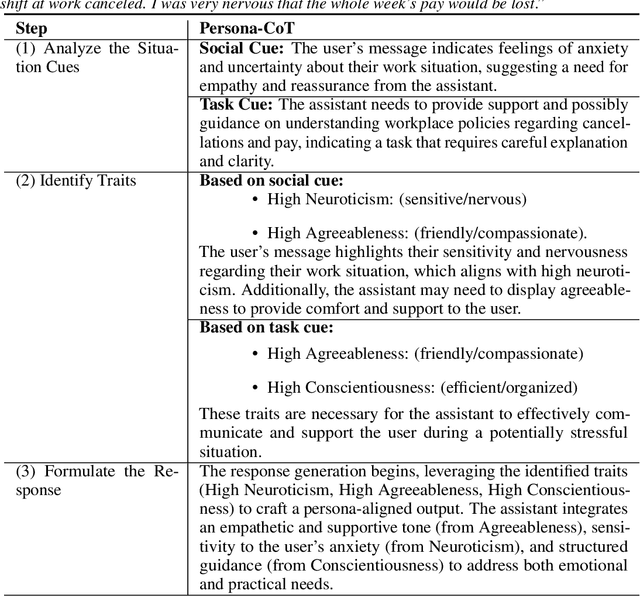
Recent advancements in Large Language Models (LLMs) demonstrate remarkable capabilities across various fields. These developments have led to more direct communication between humans and LLMs in various situations, such as social companionship and psychological support. However, LLMs often exhibit limitations in emotional perception and social competence during real-world conversations. These limitations partly originate from their inability to adapt their communication style and emotional expression to different social and task contexts. In this work, we introduce PersonaFuse, a novel LLM post-training framework that enables LLMs to adapt and express different personalities for varying situations. Inspired by Trait Activation Theory and the Big Five personality model, PersonaFuse employs a Mixture-of-Expert architecture that combines persona adapters with a dynamic routing network, enabling contextual trait expression. Experimental results show that PersonaFuse substantially outperforms baseline models across multiple dimensions of social-emotional intelligence. Importantly, these gains are achieved without sacrificing general reasoning ability or model safety, which remain common limitations of direct prompting and supervised fine-tuning approaches. PersonaFuse also delivers consistent improvements in downstream human-centered applications, such as mental health counseling and review-based customer service. Finally, human preference evaluations against leading LLMs, including GPT-4o and DeepSeek, demonstrate that PersonaFuse achieves competitive response quality despite its comparatively smaller model size. These findings demonstrate that PersonaFuse~offers a theoretically grounded and practical approach for developing social-emotional enhanced LLMs, marking a significant advancement toward more human-centric AI systems.
Uncovering the Bigger Picture: Comprehensive Event Understanding Via Diverse News Retrieval
Aug 27, 2025Access to diverse perspectives is essential for understanding real-world events, yet most news retrieval systems prioritize textual relevance, leading to redundant results and limited viewpoint exposure. We propose NEWSCOPE, a two-stage framework for diverse news retrieval that enhances event coverage by explicitly modeling semantic variation at the sentence level. The first stage retrieves topically relevant content using dense retrieval, while the second stage applies sentence-level clustering and diversity-aware re-ranking to surface complementary information. To evaluate retrieval diversity, we introduce three interpretable metrics, namely Average Pairwise Distance, Positive Cluster Coverage, and Information Density Ratio, and construct two paragraph-level benchmarks: LocalNews and DSGlobal. Experiments show that NEWSCOPE consistently outperforms strong baselines, achieving significantly higher diversity without compromising relevance. Our results demonstrate the effectiveness of fine-grained, interpretable modeling in mitigating redundancy and promoting comprehensive event understanding. The data and code are available at https://github.com/tangyixuan/NEWSCOPE.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
Mar 13, 2025Physically-based rendering (PBR) has become a cornerstone in modern computer graphics, enabling realistic material representation and lighting interactions in 3D scenes. In this paper, we present MaterialMVP, a novel end-to-end model for generating PBR textures from 3D meshes and image prompts, addressing key challenges in multi-view material synthesis. Our approach leverages Reference Attention to extract and encode informative latent from the input reference images, enabling intuitive and controllable texture generation. We also introduce a Consistency-Regularized Training strategy to enforce stability across varying viewpoints and illumination conditions, ensuring illumination-invariant and geometrically consistent results. Additionally, we propose Dual-Channel Material Generation, which separately optimizes albedo and metallic-roughness (MR) textures while maintaining precise spatial alignment with the input images through Multi-Channel Aligned Attention. Learnable material embeddings are further integrated to capture the distinct properties of albedo and MR. Experimental results demonstrate that our model generates PBR textures with realistic behavior across diverse lighting scenarios, outperforming existing methods in both consistency and quality for scalable 3D asset creation.