 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
PersonaFuse: A Personality Activation-Driven Framework for Enhancing Human-LLM Interactions
Sep 09, 2025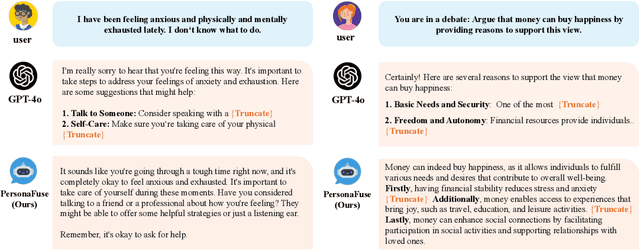

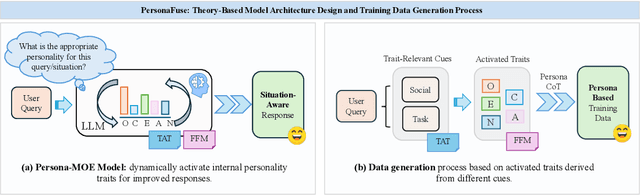
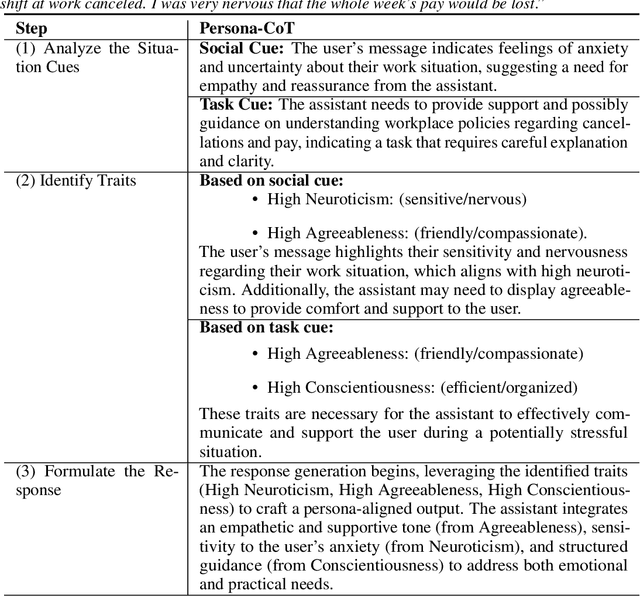
Recent advancements in Large Language Models (LLMs) demonstrate remarkable capabilities across various fields. These developments have led to more direct communication between humans and LLMs in various situations, such as social companionship and psychological support. However, LLMs often exhibit limitations in emotional perception and social competence during real-world conversations. These limitations partly originate from their inability to adapt their communication style and emotional expression to different social and task contexts. In this work, we introduce PersonaFuse, a novel LLM post-training framework that enables LLMs to adapt and express different personalities for varying situations. Inspired by Trait Activation Theory and the Big Five personality model, PersonaFuse employs a Mixture-of-Expert architecture that combines persona adapters with a dynamic routing network, enabling contextual trait expression. Experimental results show that PersonaFuse substantially outperforms baseline models across multiple dimensions of social-emotional intelligence. Importantly, these gains are achieved without sacrificing general reasoning ability or model safety, which remain common limitations of direct prompting and supervised fine-tuning approaches. PersonaFuse also delivers consistent improvements in downstream human-centered applications, such as mental health counseling and review-based customer service. Finally, human preference evaluations against leading LLMs, including GPT-4o and DeepSeek, demonstrate that PersonaFuse achieves competitive response quality despite its comparatively smaller model size. These findings demonstrate that PersonaFuse~offers a theoretically grounded and practical approach for developing social-emotional enhanced LLMs, marking a significant advancement toward more human-centric AI systems.
Ready2Unlearn: A Learning-Time Approach for Preparing Models with Future Unlearning Readiness
May 16, 2025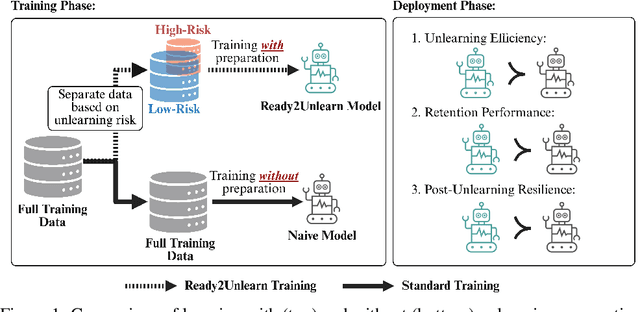


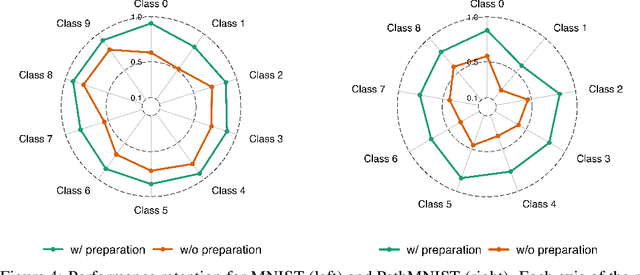
This paper introduces Ready2Unlearn, a learning-time optimization approach designed to facilitate future unlearning processes. Unlike the majority of existing unlearning efforts that focus on designing unlearning algorithms, which are typically implemented reactively when an unlearning request is made during the model deployment phase, Ready2Unlearn shifts the focus to the training phase, adopting a "forward-looking" perspective. Building upon well-established meta-learning principles, Ready2Unlearn proactively trains machine learning models with unlearning readiness, such that they are well prepared and can handle future unlearning requests in a more efficient and principled manner. Ready2Unlearn is model-agnostic and compatible with any gradient ascent-based machine unlearning algorithms. We evaluate the method on both vision and language tasks under various unlearning settings, including class-wise unlearning and random data unlearning. Experimental results show that by incorporating such preparedness at training time, Ready2Unlearn produces an unlearning-ready model state, which offers several key advantages when future unlearning is required, including reduced unlearning time, improved retention of overall model capability, and enhanced resistance to the inadvertent recovery of forgotten data. We hope this work could inspire future efforts to explore more proactive strategies for equipping machine learning models with built-in readiness towards more reliable and principled machine unlearning.
Bridging the LLM Accessibility Divide? Performance, Fairness, and Cost of Closed versus Open LLMs for Automated Essay Scoring
Mar 14, 2025Closed large language models (LLMs) such as GPT-4 have set state-of-the-art results across a number of NLP tasks and have become central to NLP and machine learning (ML)-driven solutions. Closed LLMs' performance and wide adoption has sparked considerable debate about their accessibility in terms of availability, cost, and transparency. In this study, we perform a rigorous comparative analysis of nine leading LLMs, spanning closed, open, and open-source LLM ecosystems, across text assessment and generation tasks related to automated essay scoring. Our findings reveal that for few-shot learning-based assessment of human generated essays, open LLMs such as Llama 3 and Qwen2.5 perform comparably to GPT-4 in terms of predictive performance, with no significant differences in disparate impact scores when considering age- or race-related fairness. Moreover, Llama 3 offers a substantial cost advantage, being up to 37 times more cost-efficient than GPT-4. For generative tasks, we find that essays generated by top open LLMs are comparable to closed LLMs in terms of their semantic composition/embeddings and ML assessed scores. Our findings challenge the dominance of closed LLMs and highlight the democratizing potential of open LLMs, suggesting they can effectively bridge accessibility divides while maintaining competitive performance and fairness.
Predicting Practically? Domain Generalization for Predictive Analytics in Real-world Environments
Mar 05, 2025Predictive machine learning models are widely used in customer relationship management (CRM) to forecast customer behaviors and support decision-making. However, the dynamic nature of customer behaviors often results in significant distribution shifts between training data and serving data, leading to performance degradation in predictive models. Domain generalization, which aims to train models that can generalize to unseen environments without prior knowledge of their distributions, has become a critical area of research. In this work, we propose a novel domain generalization method tailored to handle complex distribution shifts, encompassing both covariate and concept shifts. Our method builds upon the Distributionally Robust Optimization framework, optimizing model performance over a set of hypothetical worst-case distributions rather than relying solely on the training data. Through simulation experiments, we demonstrate the working mechanism of the proposed method. We also conduct experiments on a real-world customer churn dataset, and validate its effectiveness in both temporal and spatial generalization settings. Finally, we discuss the broader implications of our method for advancing Information Systems (IS) design research, particularly in building robust predictive models for dynamic managerial environments.
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Jun 06, 2024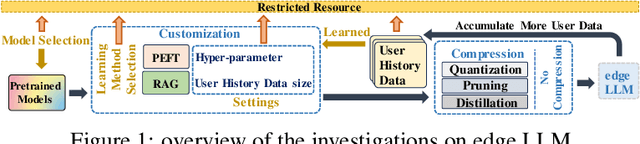
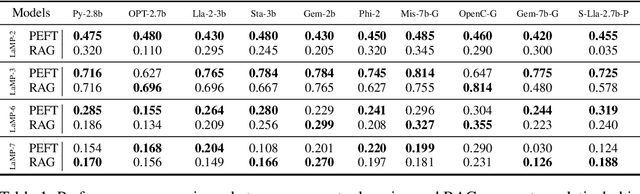
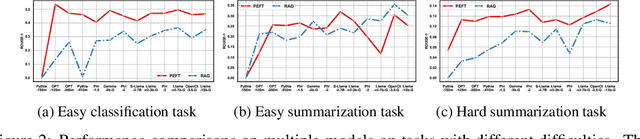

The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
FL-NAS: Towards Fairness of NAS for Resource Constrained Devices via Large Language Models
Feb 09, 2024Neural Architecture Search (NAS) has become the de fecto tools in the industry in automating the design of deep neural networks for various applications, especially those driven by mobile and edge devices with limited computing resources. The emerging large language models (LLMs), due to their prowess, have also been incorporated into NAS recently and show some promising results. This paper conducts further exploration in this direction by considering three important design metrics simultaneously, i.e., model accuracy, fairness, and hardware deployment efficiency. We propose a novel LLM-based NAS framework, FL-NAS, in this paper, and show experimentally that FL-NAS can indeed find high-performing DNNs, beating state-of-the-art DNN models by orders-of-magnitude across almost all design considerations.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
Bias A-head? Analyzing Bias in Transformer-Based Language Model Attention Heads
Nov 17, 2023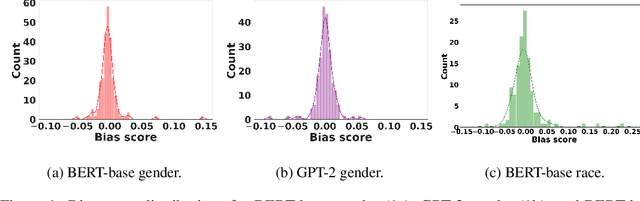
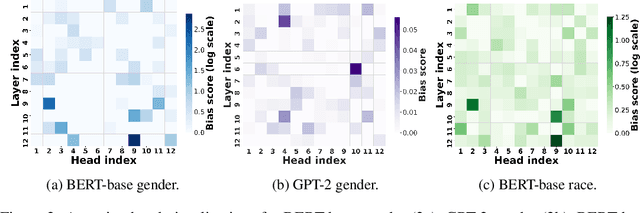
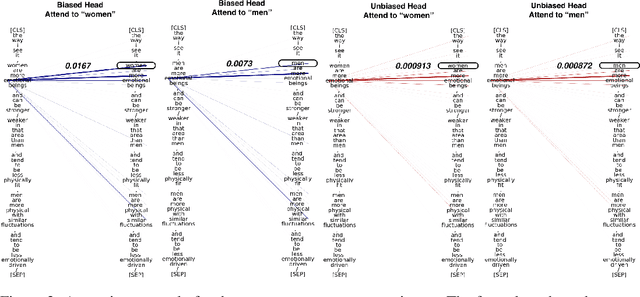
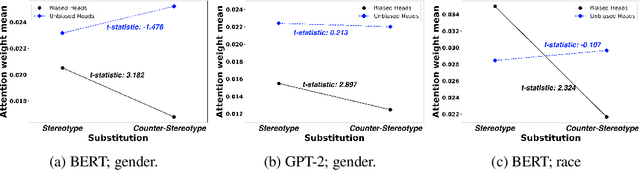
Transformer-based pretrained large language models (PLM) such as BERT and GPT have achieved remarkable success in NLP tasks. However, PLMs are prone to encoding stereotypical biases. Although a burgeoning literature has emerged on stereotypical bias mitigation in PLMs, such as work on debiasing gender and racial stereotyping, how such biases manifest and behave internally within PLMs remains largely unknown. Understanding the internal stereotyping mechanisms may allow better assessment of model fairness and guide the development of effective mitigation strategies. In this work, we focus on attention heads, a major component of the Transformer architecture, and propose a bias analysis framework to explore and identify a small set of biased heads that are found to contribute to a PLM's stereotypical bias. We conduct extensive experiments to validate the existence of these biased heads and to better understand how they behave. We investigate gender and racial bias in the English language in two types of Transformer-based PLMs: the encoder-based BERT model and the decoder-based autoregressive GPT model. Overall, the results shed light on understanding the bias behavior in pretrained language models.
Exploring the Relationship between In-Context Learning and Instruction Tuning
Nov 17, 2023In-Context Learning (ICL) and Instruction Tuning (IT) are two primary paradigms of adopting Large Language Models (LLMs) to downstream applications. However, they are significantly different. In ICL, a set of demonstrations are provided at inference time but the LLM's parameters are not updated. In IT, a set of demonstrations are used to tune LLM's parameters in training time but no demonstrations are used at inference time. Although a growing body of literature has explored ICL and IT, studies on these topics have largely been conducted in isolation, leading to a disconnect between these two paradigms. In this work, we explore the relationship between ICL and IT by examining how the hidden states of LLMs change in these two paradigms. Through carefully designed experiments conducted with LLaMA-2 (7B and 13B), we find that ICL is implicit IT. In other words, ICL changes an LLM's hidden states as if the demonstrations were used to instructionally tune the model. Furthermore, the convergence between ICL and IT is largely contingent upon several factors related to the provided demonstrations. Overall, this work offers a unique perspective to explore the connection between ICL and IT and sheds light on understanding the behaviors of LLM.