 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the LLM Accessibility Divide? Performance, Fairness, and Cost of Closed versus Open LLMs for Automated Essay Scoring
Mar 14, 2025Closed large language models (LLMs) such as GPT-4 have set state-of-the-art results across a number of NLP tasks and have become central to NLP and machine learning (ML)-driven solutions. Closed LLMs' performance and wide adoption has sparked considerable debate about their accessibility in terms of availability, cost, and transparency. In this study, we perform a rigorous comparative analysis of nine leading LLMs, spanning closed, open, and open-source LLM ecosystems, across text assessment and generation tasks related to automated essay scoring. Our findings reveal that for few-shot learning-based assessment of human generated essays, open LLMs such as Llama 3 and Qwen2.5 perform comparably to GPT-4 in terms of predictive performance, with no significant differences in disparate impact scores when considering age- or race-related fairness. Moreover, Llama 3 offers a substantial cost advantage, being up to 37 times more cost-efficient than GPT-4. For generative tasks, we find that essays generated by top open LLMs are comparable to closed LLMs in terms of their semantic composition/embeddings and ML assessed scores. Our findings challenge the dominance of closed LLMs and highlight the democratizing potential of open LLMs, suggesting they can effectively bridge accessibility divides while maintaining competitive performance and fairness.
Large Language Model-based Role-Playing for Personalized Medical Jargon Extraction
Aug 10, 2024Previous studies reveal that Electronic Health Records (EHR), which have been widely adopted in the U.S. to allow patients to access their personal medical information, do not have high readability to patients due to the prevalence of medical jargon. Tailoring medical notes to individual comprehension by identifying jargon that is difficult for each person will enhance the utility of generative models. We present the first quantitative analysis to measure the impact of role-playing in LLM in medical term extraction. By comparing the results of Mechanical Turk workers over 20 sentences, our study demonstrates that LLM role-playing improves F1 scores in 95% of cases across 14 different socio-demographic backgrounds. Furthermore, applying role-playing with in-context learning outperformed the previous state-of-the-art models. Our research showed that ChatGPT can improve traditional medical term extraction systems by utilizing role-play to deliver personalized patient education, a potential that previous models had not achieved.
A Psychology-based Unified Dynamic Framework for Curriculum Learning
Aug 09, 2024
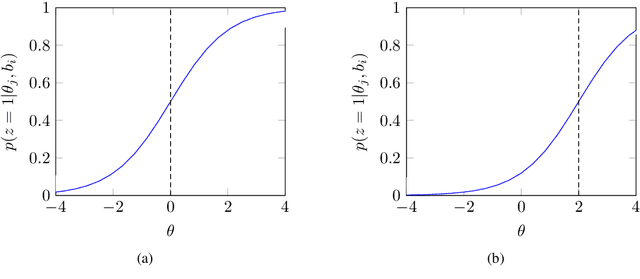
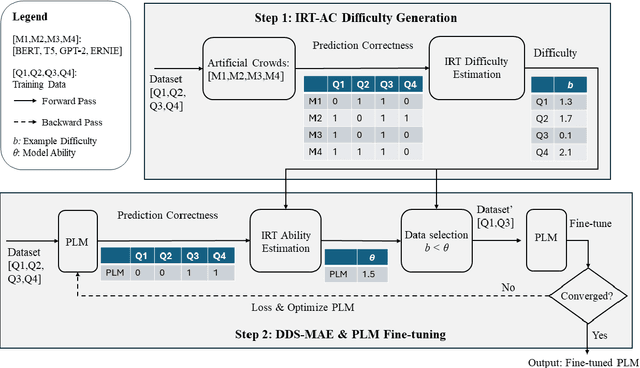

Directly learning from examples of random difficulty levels is often challenging for both humans and machine learning models. A more effective strategy involves exposing learners to examples in a progressive order, from easy to difficult. Curriculum Learning (CL) has been proposed to implement this strategy in machine learning model training. However, two key challenges persist in CL framework design: defining the difficulty of training data and determining the appropriate amount of data to input at each training step. This paper presents a Psychology-based Unified Dynamic Framework for Curriculum Learning (PUDF), drawing inspiration from psychometrics. We quantify the difficulty of training data by applying Item Response Theory (IRT) to responses from Artificial Crowds (AC). This theory-driven IRT-AC approach leads to global (i.e., model-independent) and interpretable difficulty values. Leveraging IRT, we propose a Dynamic Data Selection via Model Ability Estimation (DDS-MAE) strategy to schedule the appropriate amount of data during model training. Since our difficulty labeling and model ability estimation are based on a consistent theory, namely IRT, their values are comparable within the same scope, potentially leading to a faster convergence compared to the other CL methods. Experimental results demonstrate that fine-tuning pre-trained language models with PUDF enhances their performance on the GLUE benchmark. Moreover, PUDF surpasses other state-of-the-art (SOTA) CL methods on the GLUE benchmark. We further explore the components of PUDF, namely the difficulty measurer (IRT-AC) and the training scheduler (DDS-MAE) qualitatively and quantitatively. Lastly, we conduct an ablation study to clarify which components of PUDF contribute to faster convergence and higher accuracy.
H-COAL: Human Correction of AI-Generated Labels for Biomedical Named Entity Recognition
Nov 20, 2023
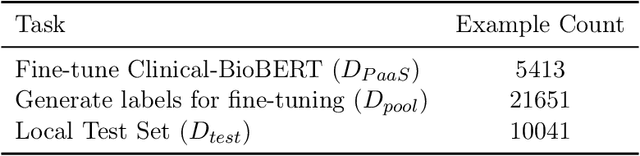
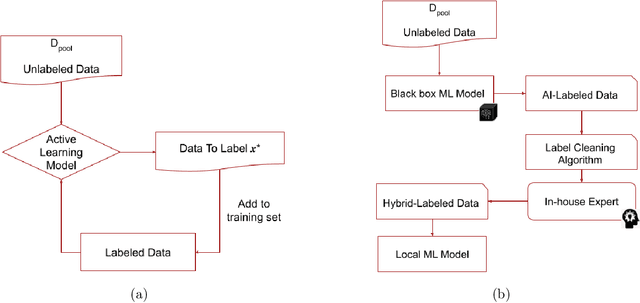
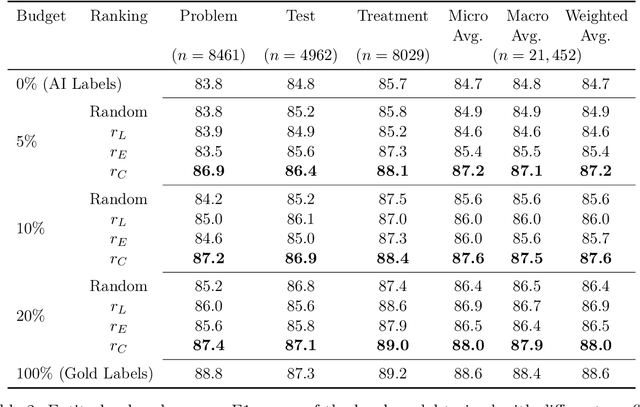
With the rapid advancement of machine learning models for NLP tasks, collecting high-fidelity labels from AI models is a realistic possibility. Firms now make AI available to customers via predictions as a service (PaaS). This includes PaaS products for healthcare. It is unclear whether these labels can be used for training a local model without expensive annotation checking by in-house experts. In this work, we propose a new framework for Human Correction of AI-Generated Labels (H-COAL). By ranking AI-generated outputs, one can selectively correct labels and approach gold standard performance (100% human labeling) with significantly less human effort. We show that correcting 5% of labels can close the AI-human performance gap by up to 64% relative improvement, and correcting 20% of labels can close the performance gap by up to 86% relative improvement.
Bias A-head? Analyzing Bias in Transformer-Based Language Model Attention Heads
Nov 17, 2023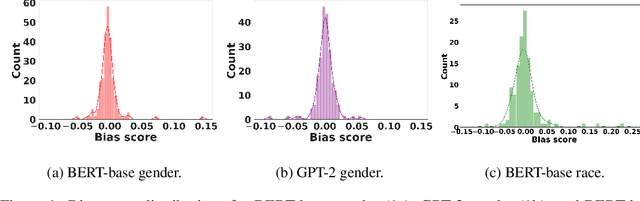
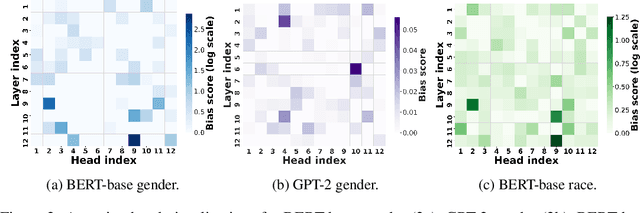
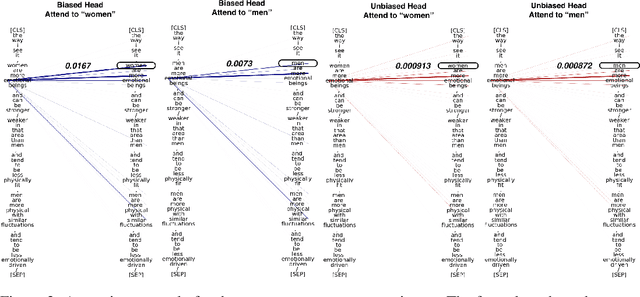
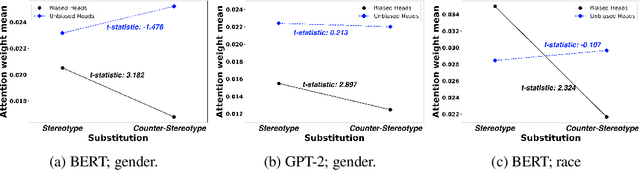
Transformer-based pretrained large language models (PLM) such as BERT and GPT have achieved remarkable success in NLP tasks. However, PLMs are prone to encoding stereotypical biases. Although a burgeoning literature has emerged on stereotypical bias mitigation in PLMs, such as work on debiasing gender and racial stereotyping, how such biases manifest and behave internally within PLMs remains largely unknown. Understanding the internal stereotyping mechanisms may allow better assessment of model fairness and guide the development of effective mitigation strategies. In this work, we focus on attention heads, a major component of the Transformer architecture, and propose a bias analysis framework to explore and identify a small set of biased heads that are found to contribute to a PLM's stereotypical bias. We conduct extensive experiments to validate the existence of these biased heads and to better understand how they behave. We investigate gender and racial bias in the English language in two types of Transformer-based PLMs: the encoder-based BERT model and the decoder-based autoregressive GPT model. Overall, the results shed light on understanding the bias behavior in pretrained language models.
Stars Are All You Need: A Distantly Supervised Pyramid Network for Document-Level End-to-End Sentiment Analysis
May 02, 2023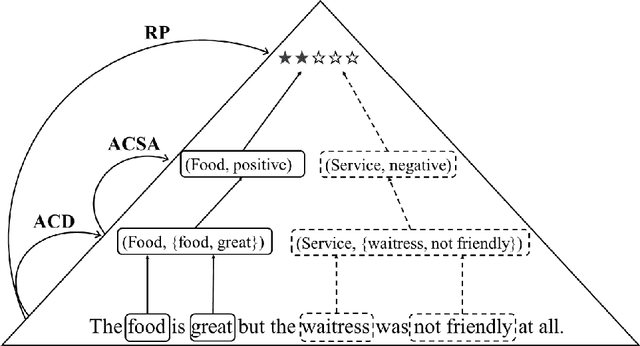
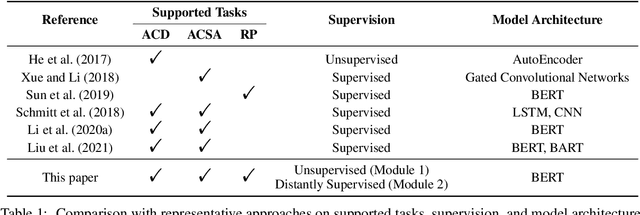

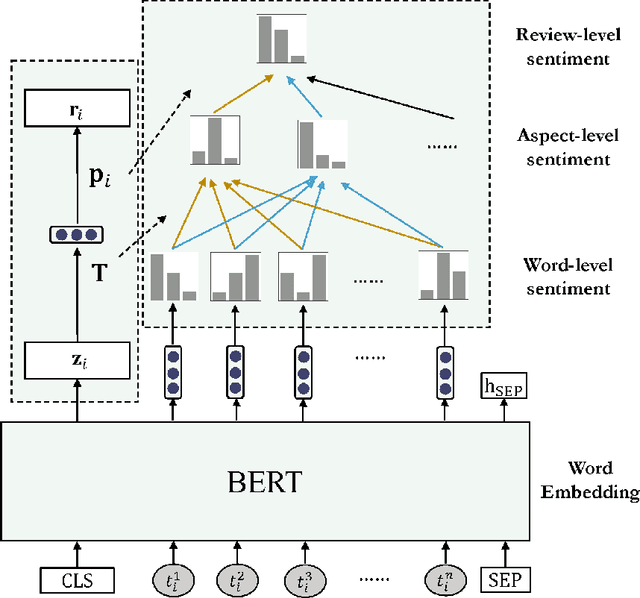
In this paper, we propose document-level end-to-end sentiment analysis to efficiently understand aspect and review sentiment expressed in online reviews in a unified manner. In particular, we assume that star rating labels are a "coarse-grained synthesis" of aspect ratings across in the review. We propose a Distantly Supervised Pyramid Network (DSPN) to efficiently perform Aspect-Category Detection, Aspect-Category Sentiment Analysis, and Rating Prediction using only document star rating labels for training. By performing these three related sentiment subtasks in an end-to-end manner, DSPN can extract aspects mentioned in the review, identify the corresponding sentiments, and predict the star rating labels. We evaluate DSPN on multi-aspect review datasets in English and Chinese and find that with only star rating labels for supervision, DSPN can perform comparably well to a variety of benchmark models. We also demonstrate the interpretability of DSPN's outputs on reviews to show the pyramid structure inherent in document level end-to-end sentiment analysis.
Measuring algorithmic interpretability: A human-learning-based framework and the corresponding cognitive complexity score
May 20, 2022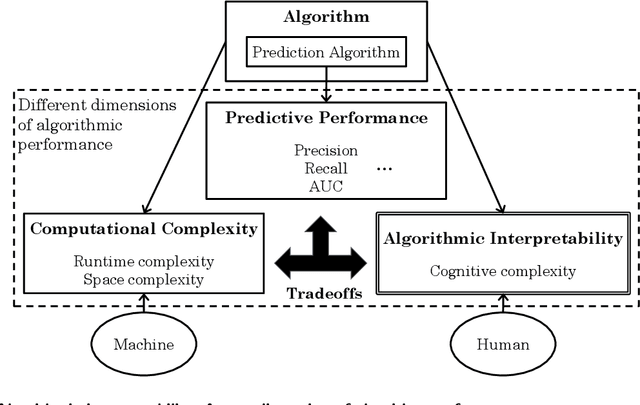
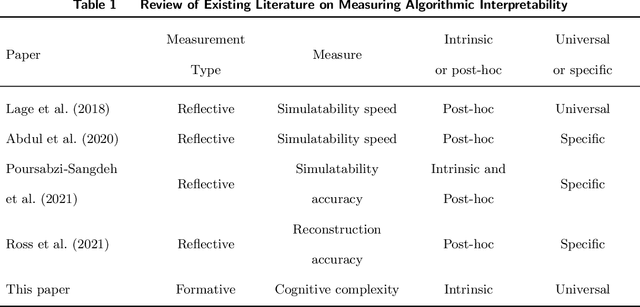


Algorithmic interpretability is necessary to build trust, ensure fairness, and track accountability. However, there is no existing formal measurement method for algorithmic interpretability. In this work, we build upon programming language theory and cognitive load theory to develop a framework for measuring algorithmic interpretability. The proposed measurement framework reflects the process of a human learning an algorithm. We show that the measurement framework and the resulting cognitive complexity score have the following desirable properties - universality, computability, uniqueness, and monotonicity. We illustrate the measurement framework through a toy example, describe the framework and its conceptual underpinnings, and demonstrate the benefits of the framework, in particular for managers considering tradeoffs when selecting algorithms.
py-irt: A Scalable Item Response Theory Library for Python
Mar 13, 2022
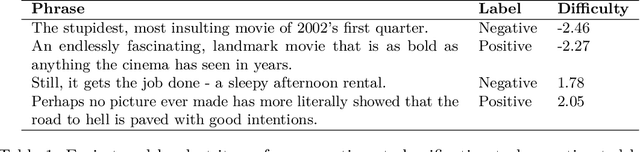

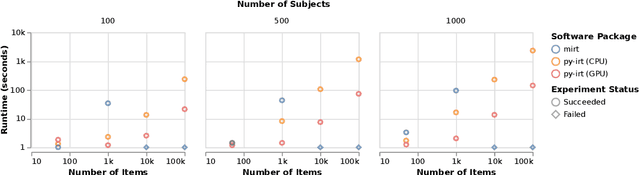
py-irt is a Python library for fitting Bayesian Item Response Theory (IRT) models. py-irt estimates latent traits of subjects and items, making it appropriate for use in IRT tasks as well as ideal-point models. py-irt is built on top of the Pyro and PyTorch frameworks and uses GPU-accelerated training to scale to large data sets. Code, documentation, and examples can be found at https://github.com/nd-ball/py-irt. py-irt can be installed from the GitHub page or the Python Package Index (PyPI).
Dynamic Data Selection for Curriculum Learning via Ability Estimation
Oct 30, 2020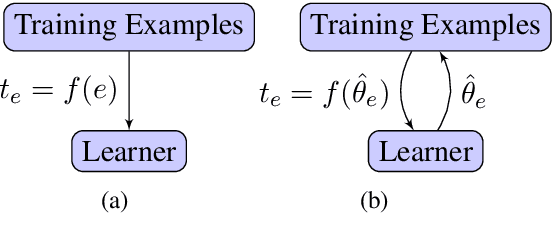



Curriculum learning methods typically rely on heuristics to estimate the difficulty of training examples or the ability of the model. In this work, we propose replacing difficulty heuristics with learned difficulty parameters. We also propose Dynamic Data selection for Curriculum Learning via Ability Estimation (DDaCLAE), a strategy that probes model ability at each training epoch to select the best training examples at that point. We show that models using learned difficulty and/or ability outperform heuristic-based curriculum learning models on the GLUE classification tasks.
Efficient Semi-Supervised Learning for Natural Language Understanding by Optimizing Diversity
Oct 09, 2019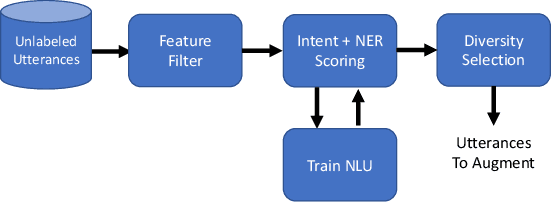
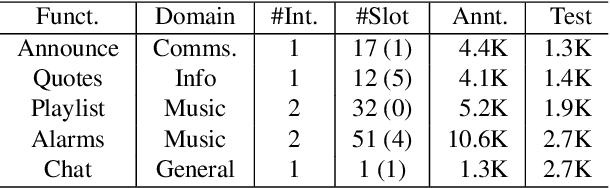
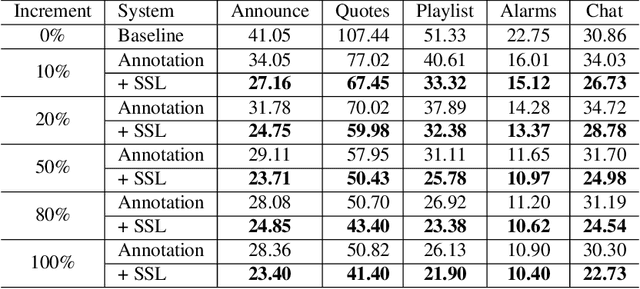
Expanding new functionalities efficiently is an ongoing challenge for single-turn task-oriented dialogue systems. In this work, we explore functionality-specific semi-supervised learning via self-training. We consider methods that augment training data automatically from unlabeled data sets in a functionality-targeted manner. In addition, we examine multiple techniques for efficient selection of augmented utterances to reduce training time and increase diversity. First, we consider paraphrase detection methods that attempt to find utterance variants of labeled training data with good coverage. Second, we explore sub-modular optimization based on n-grams features for utterance selection. Experiments show that functionality-specific self-training is very effective for improving system performance. In addition, methods optimizing diversity can reduce training data in many cases to 50% with little impact on performance.