 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-COAL: Human Correction of AI-Generated Labels for Biomedical Named Entity Recognition
Paper and Code
Nov 20, 2023
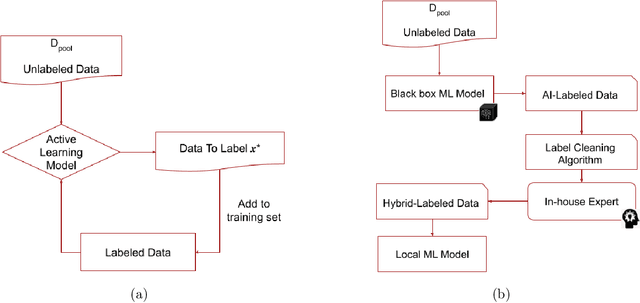
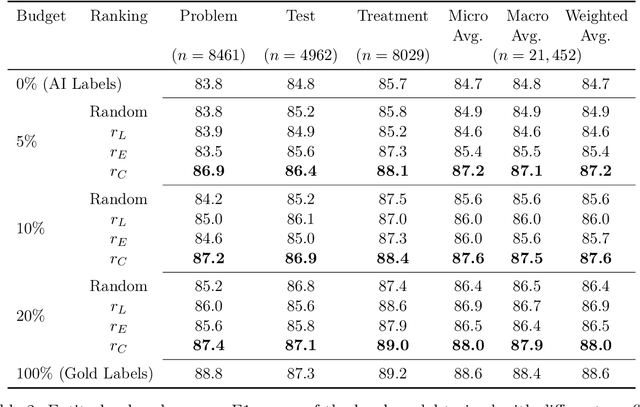
With the rapid advancement of machine learning models for NLP tasks, collecting high-fidelity labels from AI models is a realistic possibility. Firms now make AI available to customers via predictions as a service (PaaS). This includes PaaS products for healthcare. It is unclear whether these labels can be used for training a local model without expensive annotation checking by in-house experts. In this work, we propose a new framework for Human Correction of AI-Generated Labels (H-COAL). By ranking AI-generated outputs, one can selectively correct labels and approach gold standard performance (100% human labeling) with significantly less human effort. We show that correcting 5% of labels can close the AI-human performance gap by up to 64% relative improvement, and correcting 20% of labels can close the performance gap by up to 86% relative improvement.