 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-COOT: Comparing Morse-Smale Complexes with Co-Optimal Transport
Jun 06, 2026Understanding and comparing structures in scalar fields is a central challenge in scientific visualization, with applications ranging from feature analysis to temporal and structural comparison. The Morse-Smale (MS) complex provides a natural representation by decomposing a scalar field into regions induced by gradient flow. However, existing approaches typically rely on graph-based representations, capturing relationships between critical points while discarding region-level structure. In this work, we represent the MS complex as a hypergraph, where critical points form nodes and regions define hyperedges. We introduce MS-COOT, a co-optimal transport distance that jointly computes correspondences between critical points and regions. This formulation enables explicit region-to-region matching within a distance-based framework, allowing identification of region-level events such as splitting and merging. We instantiate this framework with domain-specific components, including a hypernetwork function encoding critical point-region relationships, persistence-based probability measures that emphasize topologically significant features, and a sample cost term that incorporates critical point attributes. We evaluate MS-COOT on five datasets spanning 2D simulations, 3D surface meshes, and volumetric data. Our results show that MS-COOT captures region-level structural changes that are not reflected by graph-based distances, while achieving strong performance in downstream tasks such as classification and resolution discrimination.
A Psychology-based Unified Dynamic Framework for Curriculum Learning
Aug 09, 2024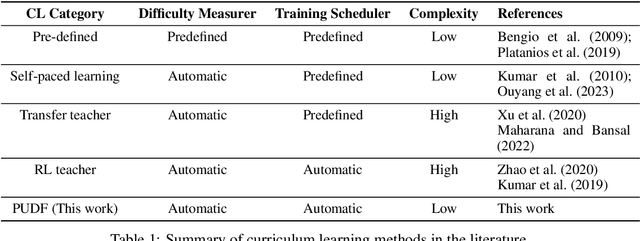
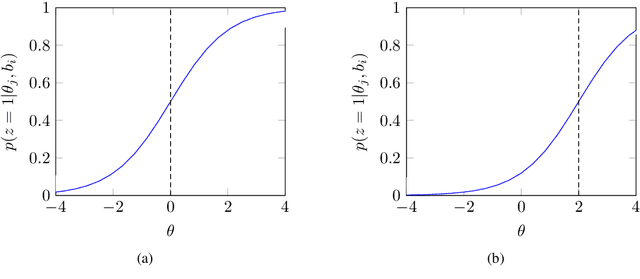
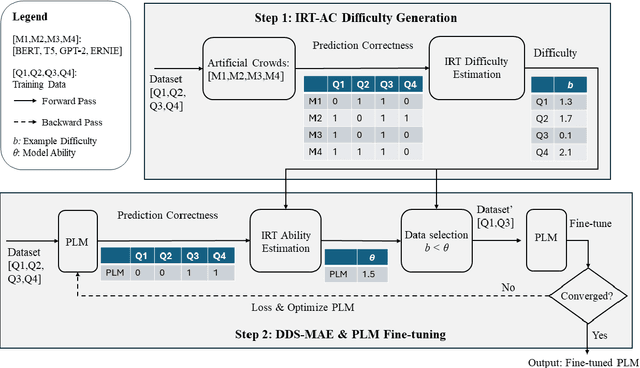

Directly learning from examples of random difficulty levels is often challenging for both humans and machine learning models. A more effective strategy involves exposing learners to examples in a progressive order, from easy to difficult. Curriculum Learning (CL) has been proposed to implement this strategy in machine learning model training. However, two key challenges persist in CL framework design: defining the difficulty of training data and determining the appropriate amount of data to input at each training step. This paper presents a Psychology-based Unified Dynamic Framework for Curriculum Learning (PUDF), drawing inspiration from psychometrics. We quantify the difficulty of training data by applying Item Response Theory (IRT) to responses from Artificial Crowds (AC). This theory-driven IRT-AC approach leads to global (i.e., model-independent) and interpretable difficulty values. Leveraging IRT, we propose a Dynamic Data Selection via Model Ability Estimation (DDS-MAE) strategy to schedule the appropriate amount of data during model training. Since our difficulty labeling and model ability estimation are based on a consistent theory, namely IRT, their values are comparable within the same scope, potentially leading to a faster convergence compared to the other CL methods. Experimental results demonstrate that fine-tuning pre-trained language models with PUDF enhances their performance on the GLUE benchmark. Moreover, PUDF surpasses other state-of-the-art (SOTA) CL methods on the GLUE benchmark. We further explore the components of PUDF, namely the difficulty measurer (IRT-AC) and the training scheduler (DDS-MAE) qualitatively and quantitatively. Lastly, we conduct an ablation study to clarify which components of PUDF contribute to faster convergence and higher accuracy.
Efficient approximation of Earth Mover's Distance Based on Nearest Neighbor Search
Jan 20, 2024



Earth Mover's Distance (EMD) is an important similarity measure between two distributions, used in computer vision and many other application domains. However, its exact calculation is computationally and memory intensive, which hinders its scalability and applicability for large-scale problems. Various approximate EMD algorithms have been proposed to reduce computational costs, but they suffer lower accuracy and may require additional memory usage or manual parameter tuning. In this paper, we present a novel approach, NNS-EMD, to approximate EMD using Nearest Neighbor Search (NNS), in order to achieve high accuracy, low time complexity, and high memory efficiency. The NNS operation reduces the number of data points compared in each NNS iteration and offers opportunities for parallel processing. We further accelerate NNS-EMD via vectorization on GPU, which is especially beneficial for large datasets. We compare NNS-EMD with both the exact EMD and state-of-the-art approximate EMD algorithms on image classification and retrieval tasks. We also apply NNS-EMD to calculate transport mapping and realize color transfer between images. NNS-EMD can be 44x to 135x faster than the exact EMD implementation, and achieves superior accuracy, speedup, and memory efficiency over existing approximate EMD methods.