 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 65 nm Bayesian Neural Network Accelerator with 360 fJ/Sample In-Word GRNG for AI Uncertainty Estimation
Jan 08, 2025



Uncertainty estimation is an indispensable capability for AI-enabled, safety-critical applications, e.g. autonomous vehicles or medical diagnosis. Bayesian neural networks (BNNs) use Bayesian statistics to provide both classification predictions and uncertainty estimation, but they suffer from high computational overhead associated with random number generation and repeated sample iterations. Furthermore, BNNs are not immediately amenable to acceleration through compute-in-memory architectures due to the frequent memory writes necessary after each RNG operation. To address these challenges, we present an ASIC that integrates 360 fJ/Sample Gaussian RNG directly into the SRAM memory words. This integration reduces RNG overhead and enables fully-parallel compute-in-memory operations for BNNs. The prototype chip achieves 5.12 GSa/s RNG throughput and 102 GOp/s neural network throughput while occupying 0.45 mm2, bringing AI uncertainty estimation to edge computation.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024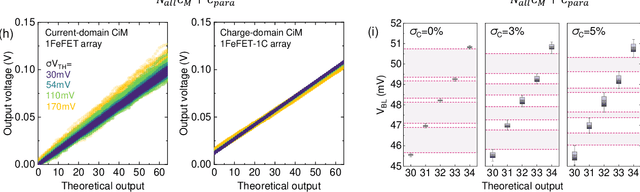
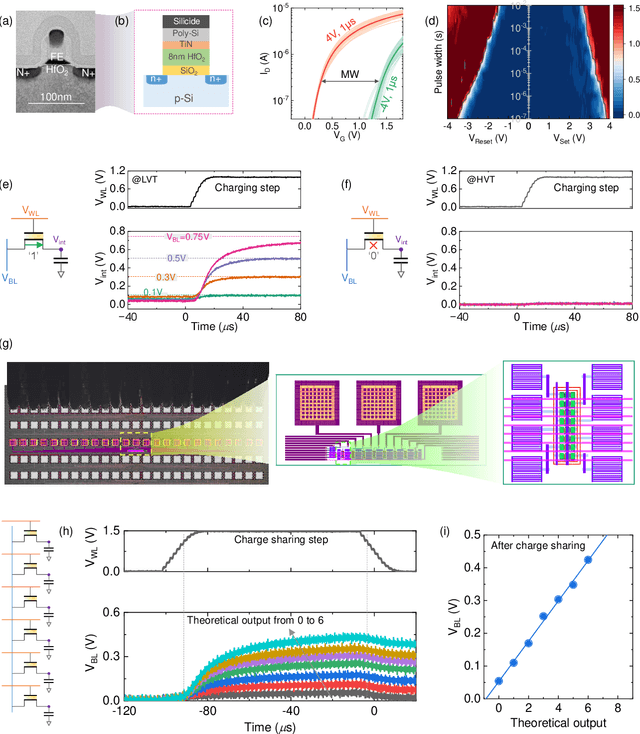
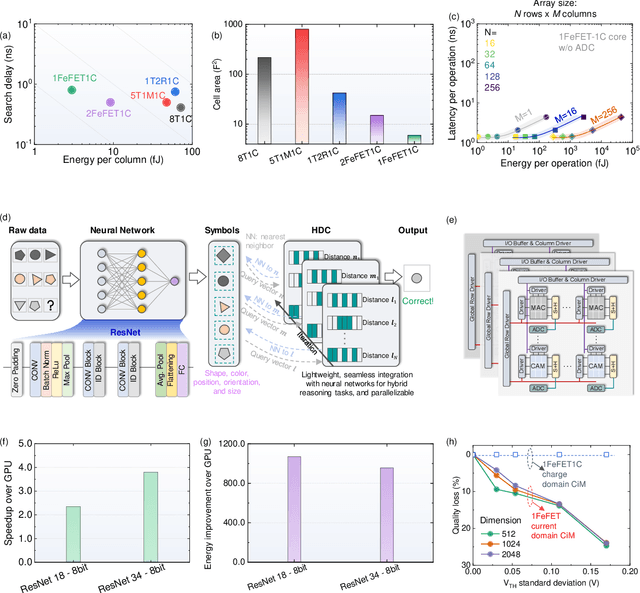
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
Efficient approximation of Earth Mover's Distance Based on Nearest Neighbor Search
Jan 20, 2024



Earth Mover's Distance (EMD) is an important similarity measure between two distributions, used in computer vision and many other application domains. However, its exact calculation is computationally and memory intensive, which hinders its scalability and applicability for large-scale problems. Various approximate EMD algorithms have been proposed to reduce computational costs, but they suffer lower accuracy and may require additional memory usage or manual parameter tuning. In this paper, we present a novel approach, NNS-EMD, to approximate EMD using Nearest Neighbor Search (NNS), in order to achieve high accuracy, low time complexity, and high memory efficiency. The NNS operation reduces the number of data points compared in each NNS iteration and offers opportunities for parallel processing. We further accelerate NNS-EMD via vectorization on GPU, which is especially beneficial for large datasets. We compare NNS-EMD with both the exact EMD and state-of-the-art approximate EMD algorithms on image classification and retrieval tasks. We also apply NNS-EMD to calculate transport mapping and realize color transfer between images. NNS-EMD can be 44x to 135x faster than the exact EMD implementation, and achieves superior accuracy, speedup, and memory efficiency over existing approximate EMD methods.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021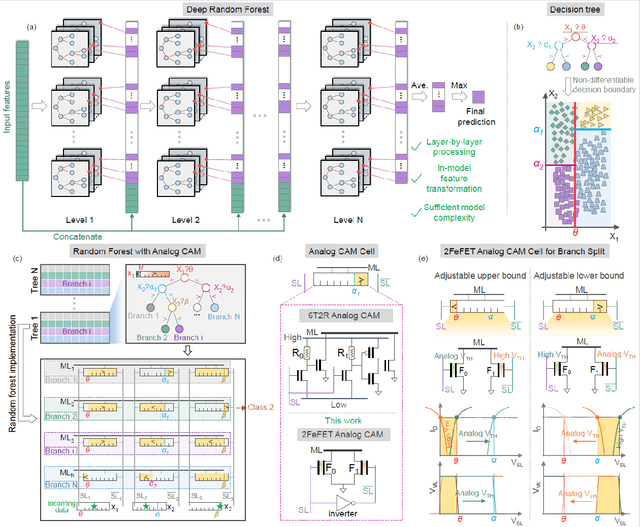
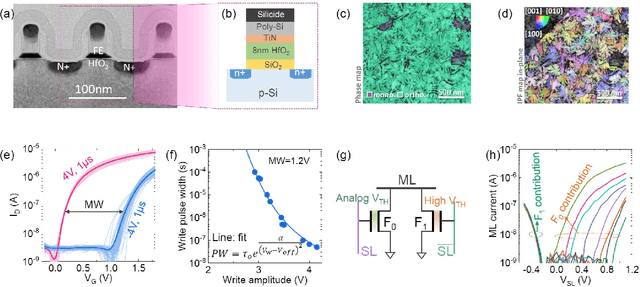
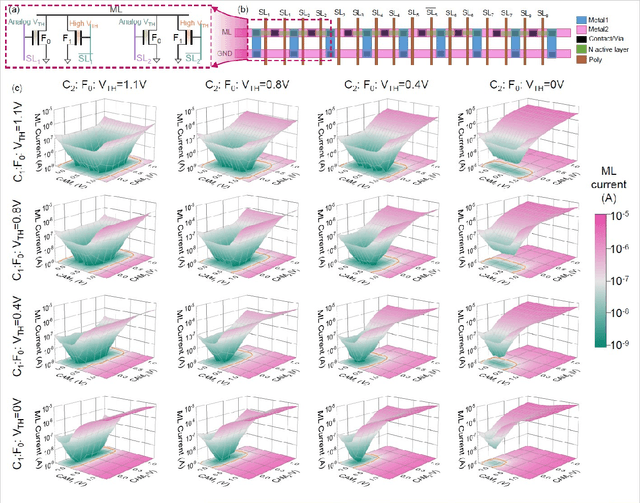
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
In-Memory Nearest Neighbor Search with FeFET Multi-Bit Content-Addressable Memories
Nov 13, 2020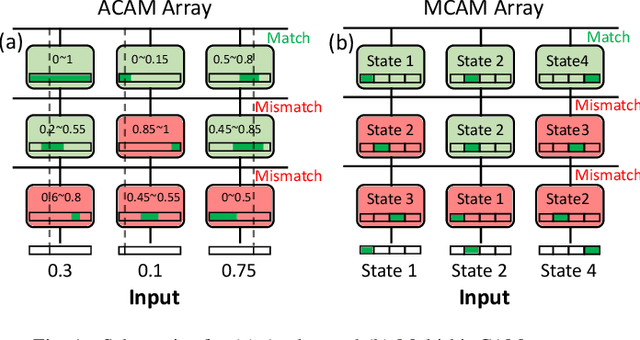
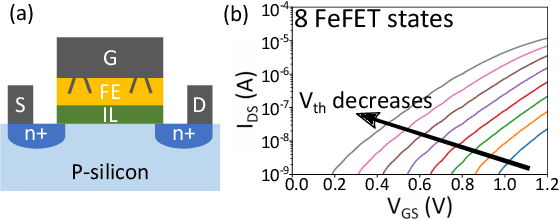
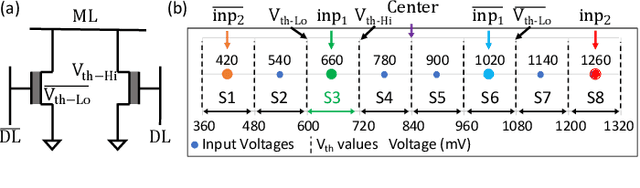
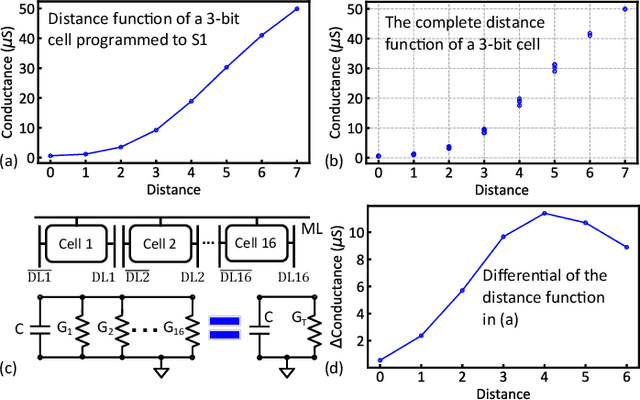
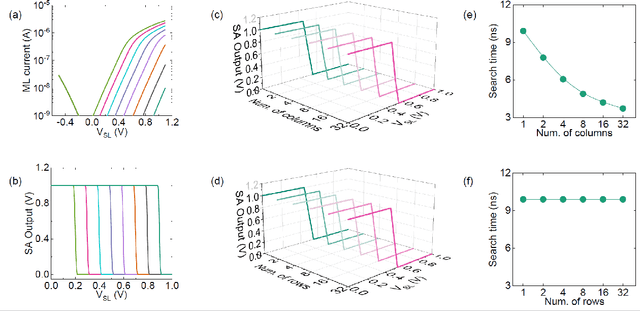
Nearest neighbor (NN) search is an essential operation in many applications, such as one/few-shot learning and image classification. As such, fast and low-energy hardware support for accurate NN search is highly desirable. Ternary content-addressable memories (TCAMs) have been proposed to accelerate NN search for few-shot learning tasks by implementing $L_\infty$ and Hamming distance metrics, but they cannot achieve software-comparable accuracies. This paper proposes a novel distance function that can be natively evaluated with multi-bit content-addressable memories (MCAMs) based on ferroelectric FETs (FeFETs) to perform a single-step, in-memory NN search. Moreover, this approach achieves accuracies comparable to floating-point precision implementations in software for NN classification and one/few-shot learning tasks. As an example, the proposed method achieves a 98.34% accuracy for a 5-way, 5-shot classification task for the Omniglot dataset (only 0.8% lower than software-based implementations) with a 3-bit MCAM. This represents a 13% accuracy improvement over state-of-the-art TCAM-based implementations at iso-energy and iso-delay. The presented distance function is resilient to the effects of FeFET device-to-device variations. Furthermore, this work experimentally demonstrates a 2-bit implementation of FeFET MCAM using AND arrays from GLOBALFOUNDRIES to further validate proof of concept.
Nonvolatile Spintronic Memory Cells for Neural Networks
May 29, 2019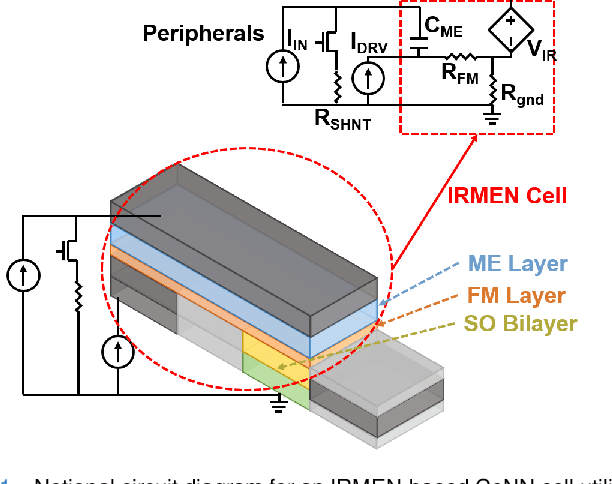
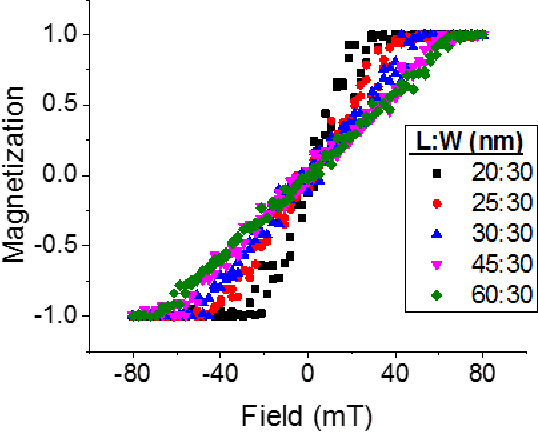
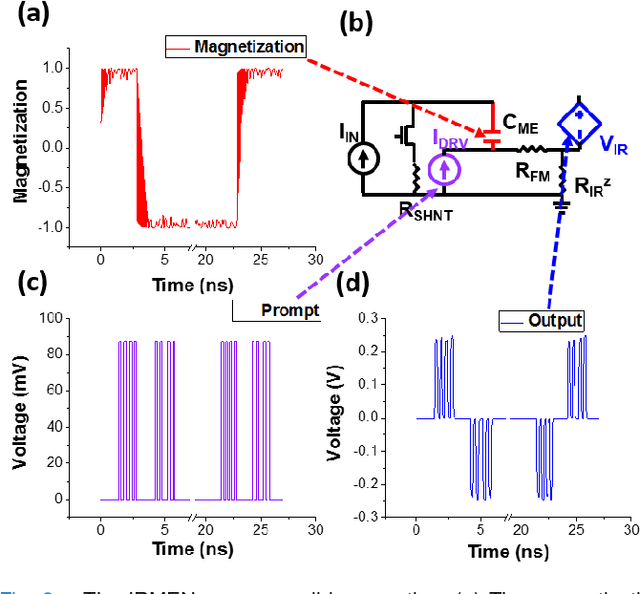
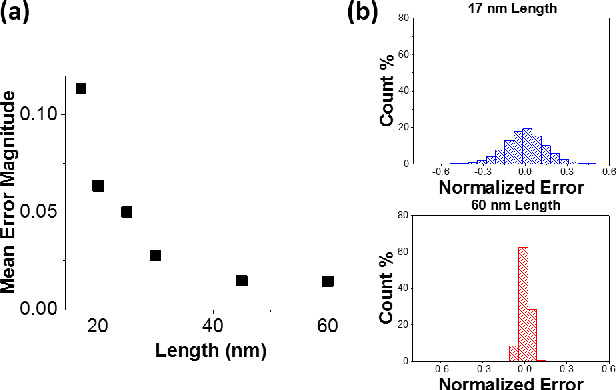
A new spintronic nonvolatile memory cell analogous to 1T DRAM with non-destructive read is proposed. The cells can be used as neural computing units. A dual-circuit neural network architecture is proposed to leverage these devices against the complex operations involved in convolutional networks. Simulations based on HSPICE and Matlab were performed to study the performance of this architecture when classifying images as well as the effect of varying the size and stability of the nanomagnets. The spintronic cells outperform a purely charge-based implementation of the same network, consuming about 100 pJ total per image processed.
Application-level Studies of Cellular Neural Network-based Hardware Accelerators
Feb 28, 2019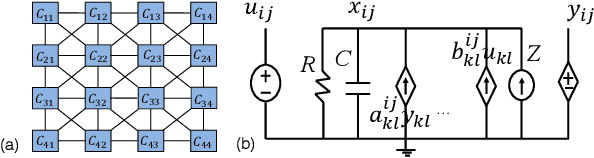
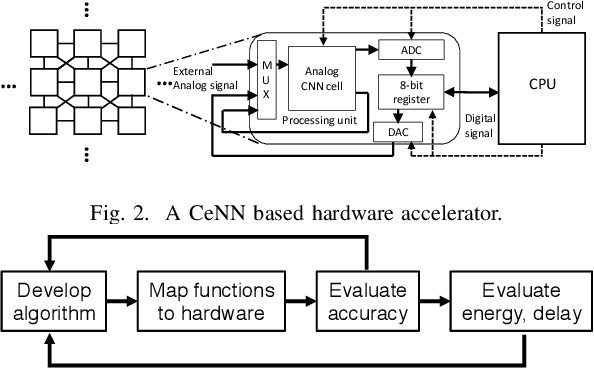
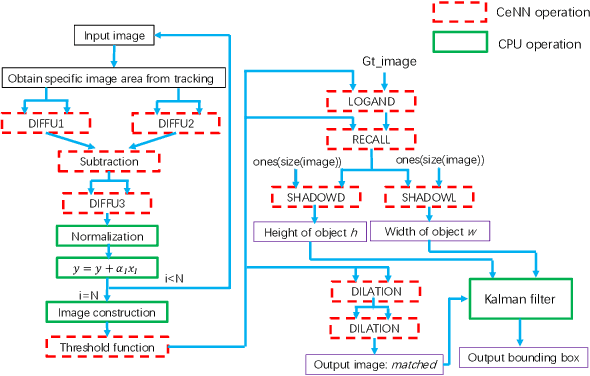
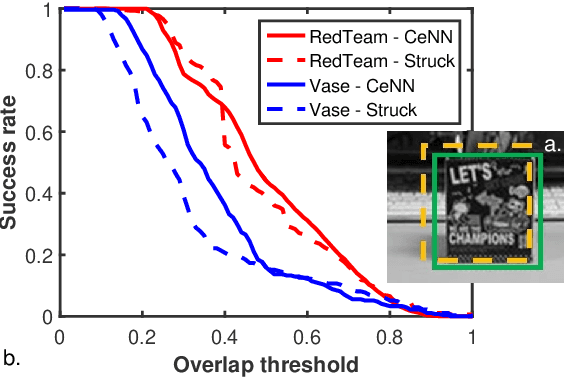
As cost and performance benefits associated with Moore's Law scaling slow, researchers are studying alternative architectures (e.g., based on analog and/or spiking circuits) and/or computational models (e.g., convolutional and recurrent neural networks) to perform application-level tasks faster, more energy efficiently, and/or more accurately. We investigate cellular neural network (CeNN)-based co-processors at the application-level for these metrics. While it is well-known that CeNNs can be well-suited for spatio-temporal information processing, few (if any) studies have quantified the energy/delay/accuracy of a CeNN-friendly algorithm and compared the CeNN-based approach to the best von Neumann algorithm at the application level. We present an evaluation framework for such studies. As a case study, a CeNN-friendly target-tracking algorithm was developed and mapped to an array architecture developed in conjunction with the algorithm. We compare the energy, delay, and accuracy of our architecture/algorithm (assuming all overheads) to the most accurate von Neumann algorithm (Struck). Von Neumann CPU data is measured on an Intel i5 chip. The CeNN approach is capable of matching the accuracy of Struck, and can offer approximately 1000x improvements in energy-delay product.