 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Chain Decoders Overcome the Heavy-Tail Limitations of Lipschitz Generative Models
May 18, 2026Heavy-tailed distributions are prevalent in performance evaluation, network traffic, and risk modeling. This behavior poses a fundamental challenge for modern deep generative models. Standard Variational Autoencoders (VAEs) employ Gaussian decoder likelihoods and Lipschitz-constrained neural networks, a combination that is structurally incapable of producing heavy-tailed outputs: the Gaussian tail decays exponentially, and Lipschitz continuity prevents the decoder from amplifying rare events from the latent space input to sufficiently overcome this decay. We provide both a theoretical characterization of this limitation and a controlled empirical demonstration using synthetic Pareto data across a grid of tail indices $α$ $\in$ {2, 3, 5, 30} and dimensions d $\in$ {1, 5, 10}. As a solution, we replace the Gaussian decoder with a Phase-Type (PH) distribution based on Markov chains, while keeping the encoder, latent space, and training procedure identical. PH distributions allow for arbitrarily precise approximations of any positive-valued distributions, including heavy-tailed families. Experiments showed that the PH-based model reduces tail Kolmogorov-Smirnov distance by up to x6 and extreme quantile error by up to x10 compared to the Gaussian baseline for heavy-tailed data. These results demonstrate that integrating Markov chain-based distributions into the decoder of a generative model institutes a principled and practically effective solution to the heavy-tail generation problem.
Targeted Adversarial Attacks on Generalizable Neural Radiance Fields
Oct 05, 2023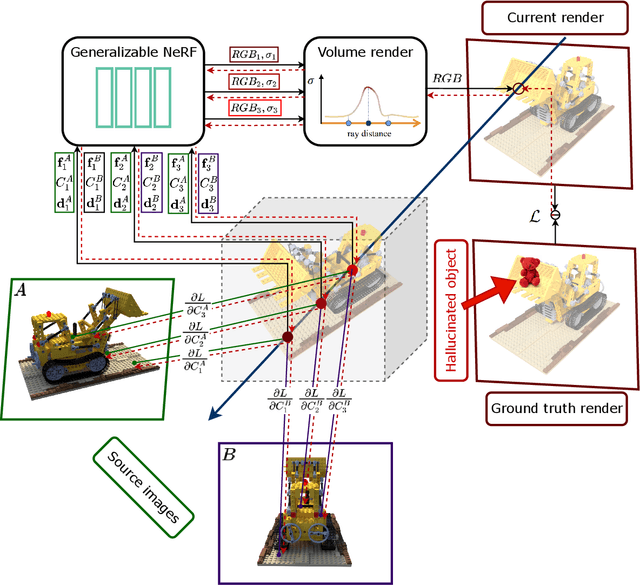
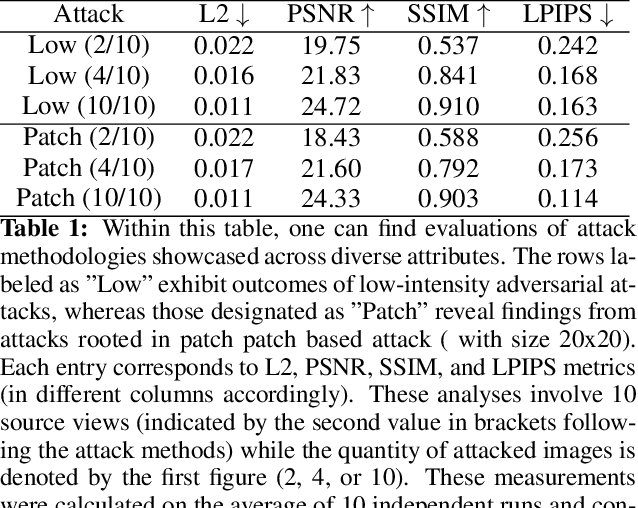


Neural Radiance Fields (NeRFs) have recently emerged as a powerful tool for 3D scene representation and rendering. These data-driven models can learn to synthesize high-quality images from sparse 2D observations, enabling realistic and interactive scene reconstructions. However, the growing usage of NeRFs in critical applications such as augmented reality, robotics, and virtual environments could be threatened by adversarial attacks. In this paper we present how generalizable NeRFs can be attacked by both low-intensity adversarial attacks and adversarial patches, where the later could be robust enough to be used in real world applications. We also demonstrate targeted attacks, where a specific, predefined output scene is generated by these attack with success.
On the Feasibility and Generality of Patch-based Adversarial Attacks on Semantic Segmentation Problems
May 21, 2022
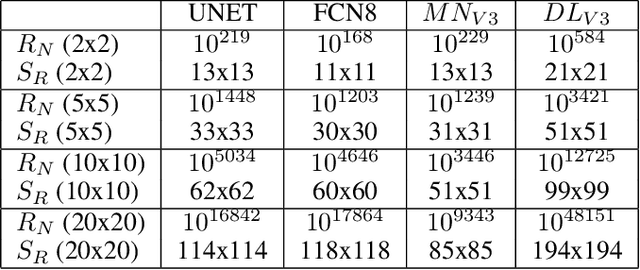


Deep neural networks were applied with success in a myriad of applications, but in safety critical use cases adversarial attacks still pose a significant threat. These attacks were demonstrated on various classification and detection tasks and are usually considered general in a sense that arbitrary network outputs can be generated by them. In this paper we will demonstrate through simple case studies both in simulation and in real-life, that patch based attacks can be utilised to alter the output of segmentation networks. Through a few examples and the investigation of network complexity, we will also demonstrate that the number of possible output maps which can be generated via patch-based attacks of a given size is typically smaller than the area they effect or areas which should be attacked in case of practical applications. We will prove that based on these results most patch-based attacks cannot be general in practice, namely they can not generate arbitrary output maps or if they could, they are spatially limited and this limit is significantly smaller than the receptive field of the patches.
Mitigating the Bias of Centered Objects in Common Datasets
Dec 16, 2021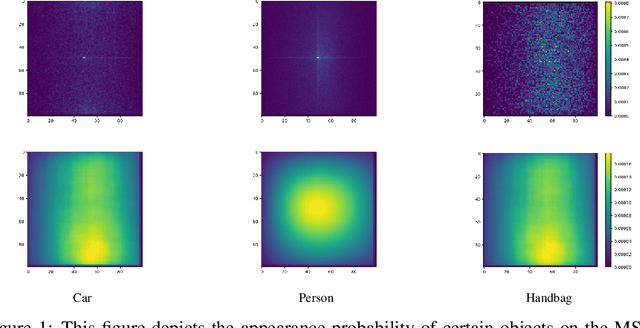
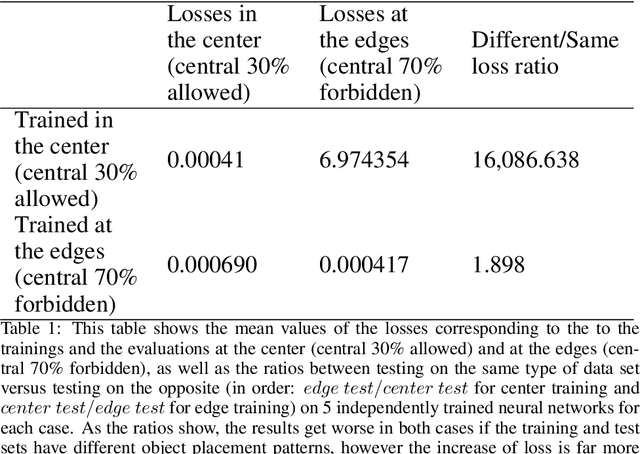

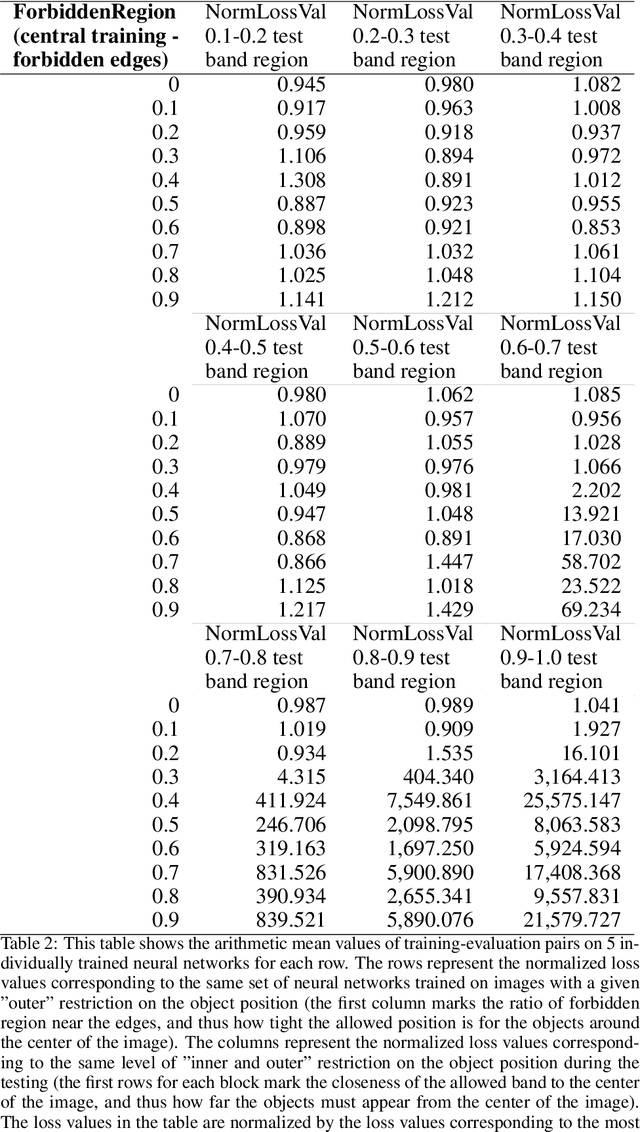
Convolutional networks are considered shift invariant, but it was demonstrated that their response may vary according to the exact location of the objects. In this paper we will demonstrate that most commonly investigated datasets have a bias, where objects are over-represented at the center of the image during training. This bias and the boundary condition of these networks can have a significant effect on the performance of these architectures and their accuracy drops significantly as an object approaches the boundary. We will also demonstrate how this effect can be mitigated with data augmentation techniques.
Filtered Batch Normalization
Oct 16, 2020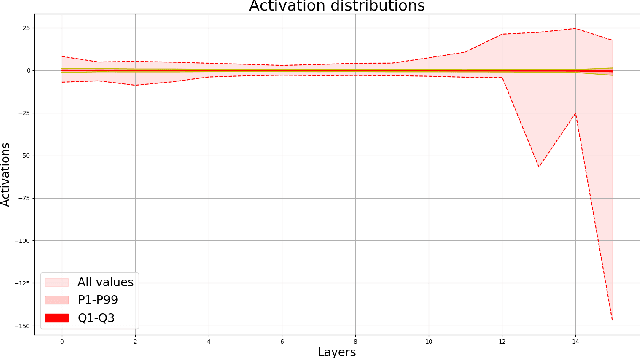

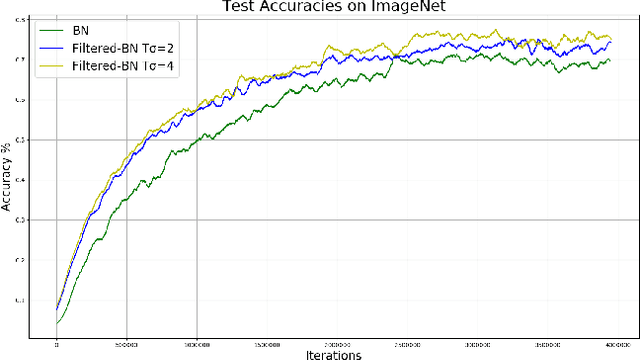

It is a common assumption that the activation of different layers in neural networks follow Gaussian distribution. This distribution can be transformed using normalization techniques, such as batch-normalization, increasing convergence speed and improving accuracy. In this paper we would like to demonstrate, that activations do not necessarily follow Gaussian distribution in all layers. Neurons in deeper layers are more selective and specific which can result extremely large, out-of-distribution activations. We will demonstrate that one can create more consistent mean and variance values for batch normalization during training by filtering out these activations which can further improve convergence speed and yield higher validation accuracy.
Application-level Studies of Cellular Neural Network-based Hardware Accelerators
Feb 28, 2019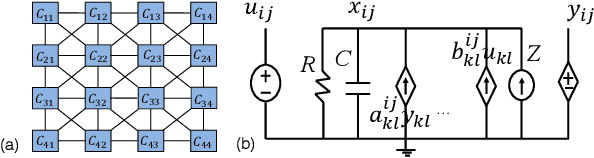
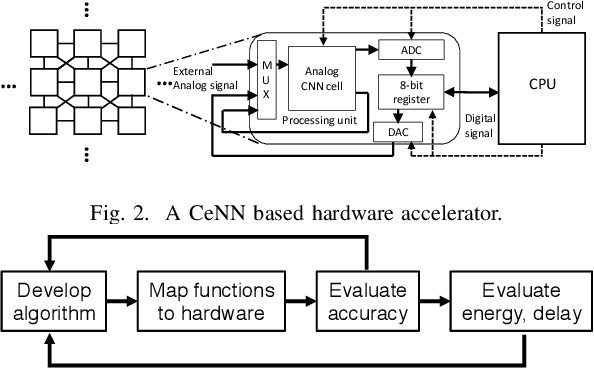
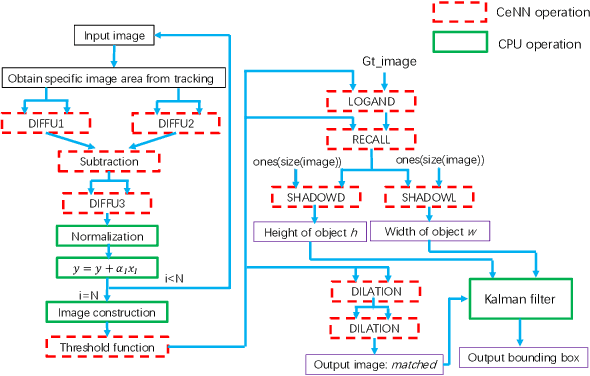
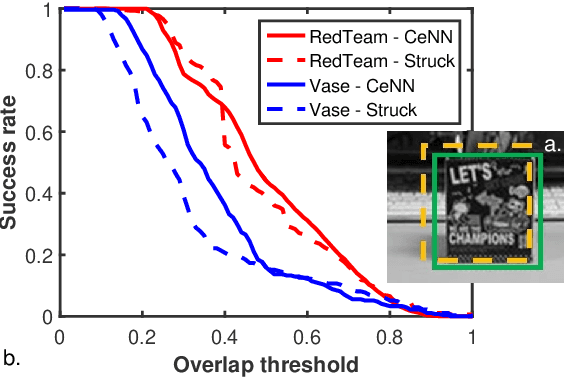
As cost and performance benefits associated with Moore's Law scaling slow, researchers are studying alternative architectures (e.g., based on analog and/or spiking circuits) and/or computational models (e.g., convolutional and recurrent neural networks) to perform application-level tasks faster, more energy efficiently, and/or more accurately. We investigate cellular neural network (CeNN)-based co-processors at the application-level for these metrics. While it is well-known that CeNNs can be well-suited for spatio-temporal information processing, few (if any) studies have quantified the energy/delay/accuracy of a CeNN-friendly algorithm and compared the CeNN-based approach to the best von Neumann algorithm at the application level. We present an evaluation framework for such studies. As a case study, a CeNN-friendly target-tracking algorithm was developed and mapped to an array architecture developed in conjunction with the algorithm. We compare the energy, delay, and accuracy of our architecture/algorithm (assuming all overheads) to the most accurate von Neumann algorithm (Struck). Von Neumann CPU data is measured on an Intel i5 chip. The CeNN approach is capable of matching the accuracy of Struck, and can offer approximately 1000x improvements in energy-delay product.