 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAT-CXR: Uncertainty-Aware Agentic Triage for Chest X-rays
Aug 26, 2025Agentic AI is advancing rapidly, yet truly autonomous medical-imaging triage, where a system decides when to stop, escalate, or defer under real constraints, remains relatively underexplored. To address this gap, we introduce AT-CXR, an uncertainty-aware agent for chest X-rays. The system estimates per-case confidence and distributional fit, then follows a stepwise policy to issue an automated decision or abstain with a suggested label for human intervention. We evaluate two router designs that share the same inputs and actions: a deterministic rule-based router and an LLM-decided router. Across five-fold evaluation on a balanced subset of NIH ChestX-ray14 dataset, both variants outperform strong zero-shot vision-language models and state-of-the-art supervised classifiers, achieving higher full-coverage accuracy and superior selective-prediction performance, evidenced by a lower area under the risk-coverage curve (AURC) and a lower error rate at high coverage, while operating with lower latency that meets practical clinical constraints. The two routers provide complementary operating points, enabling deployments to prioritize maximal throughput or maximal accuracy. Our code is available at https://github.com/XLIAaron/uncertainty-aware-cxr-agent.
Dual-level Fuzzy Learning with Patch Guidance for Image Ordinal Regression
May 09, 2025Ordinal regression bridges regression and classification by assigning objects to ordered classes. While human experts rely on discriminative patch-level features for decisions, current approaches are limited by the availability of only image-level ordinal labels, overlooking fine-grained patch-level characteristics. In this paper, we propose a Dual-level Fuzzy Learning with Patch Guidance framework, named DFPG that learns precise feature-based grading boundaries from ambiguous ordinal labels, with patch-level supervision. Specifically, we propose patch-labeling and filtering strategies to enable the model to focus on patch-level features exclusively with only image-level ordinal labels available. We further design a dual-level fuzzy learning module, which leverages fuzzy logic to quantitatively capture and handle label ambiguity from both patch-wise and channel-wise perspectives. Extensive experiments on various image ordinal regression datasets demonstrate the superiority of our proposed method, further confirming its ability in distinguishing samples from difficult-to-classify categories. The code is available at https://github.com/ZJUMAI/DFPG-ord.
OrderChain: A General Prompting Paradigm to Improve Ordinal Understanding Ability of MLLM
Apr 07, 2025Despite the remarkable progress of multimodal large language models (MLLMs), they continue to face challenges in achieving competitive performance on ordinal regression (OR; a.k.a. ordinal classification). To address this issue, this paper presents OrderChain, a novel and general prompting paradigm that improves the ordinal understanding ability of MLLMs by specificity and commonality modeling. Specifically, our OrderChain consists of a set of task-aware prompts to facilitate the specificity modeling of diverse OR tasks and a new range optimization Chain-of-Thought (RO-CoT), which learns a commonality way of thinking about OR tasks by uniformly decomposing them into multiple small-range optimization subtasks. Further, we propose a category recursive division (CRD) method to generate instruction candidate category prompts to support RO-CoT automatic optimization. Comprehensive experiments show that a Large Language and Vision Assistant (LLaVA) model with our OrderChain improves baseline LLaVA significantly on diverse OR datasets, e.g., from 47.5% to 93.2% accuracy on the Adience dataset for age estimation, and from 30.0% to 85.7% accuracy on the Diabetic Retinopathy dataset. Notably, LLaVA with our OrderChain also remarkably outperforms state-of-the-art methods by 27% on accuracy and 0.24 on MAE on the Adience dataset. To our best knowledge, our OrderChain is the first work that augments MLLMs for OR tasks, and the effectiveness is witnessed across a spectrum of OR datasets.
Style-agnostic evaluation of ASR using multiple reference transcripts
Dec 10, 2024



Word error rate (WER) as a metric has a variety of limitations that have plagued the field of speech recognition. Evaluation datasets suffer from varying style, formality, and inherent ambiguity of the transcription task. In this work, we attempt to mitigate some of these differences by performing style-agnostic evaluation of ASR systems using multiple references transcribed under opposing style parameters. As a result, we find that existing WER reports are likely significantly over-estimating the number of contentful errors made by state-of-the-art ASR systems. In addition, we have found our multireference method to be a useful mechanism for comparing the quality of ASR models that differ in the stylistic makeup of their training data and target task.
Scalable Autoregressive Monocular Depth Estimation
Nov 18, 2024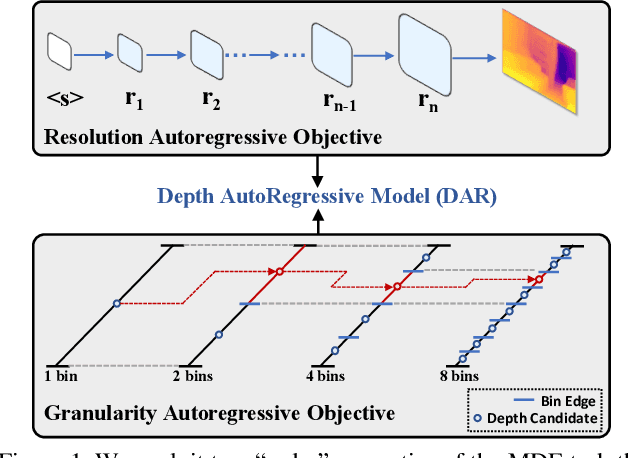
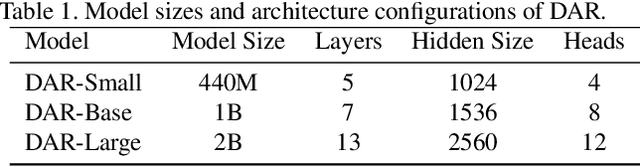
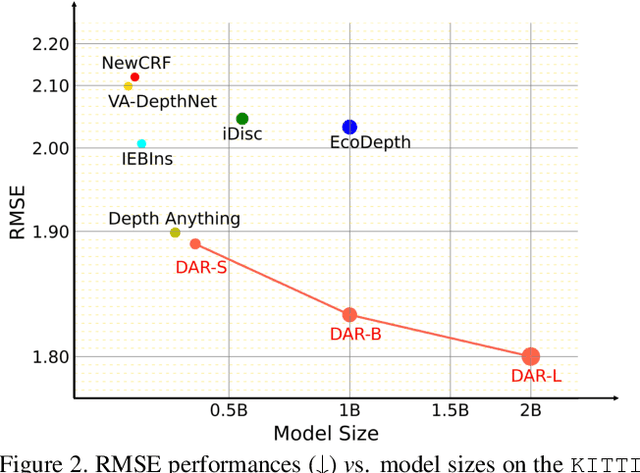
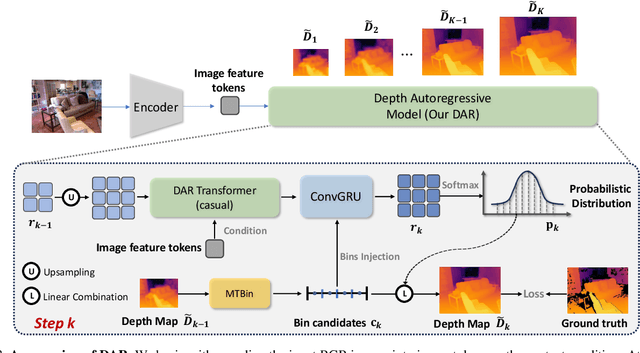
This paper proposes a new autoregressive model as an effective and scalable monocular depth estimator. Our idea is simple: We tackle the monocular depth estimation (MDE) task with an autoregressive prediction paradigm, based on two core designs. First, our depth autoregressive model (DAR) treats the depth map of different resolutions as a set of tokens, and conducts the low-to-high resolution autoregressive objective with a patch-wise casual mask. Second, our DAR recursively discretizes the entire depth range into more compact intervals, and attains the coarse-to-fine granularity autoregressive objective in an ordinal-regression manner. By coupling these two autoregressive objectives, our DAR establishes new state-of-the-art (SOTA) on KITTI and NYU Depth v2 by clear margins. Further, our scalable approach allows us to scale the model up to 2.0B and achieve the best RMSE of 1.799 on the KITTI dataset (5% improvement) compared to 1.896 by the current SOTA (Depth Anything). DAR further showcases zero-shot generalization ability on unseen datasets. These results suggest that DAR yields superior performance with an autoregressive prediction paradigm, providing a promising approach to equip modern autoregressive large models (e.g., GPT-4o) with depth estimation capabilities.
Reverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Group-On: Boosting One-Shot Segmentation with Supportive Query
Apr 18, 2024

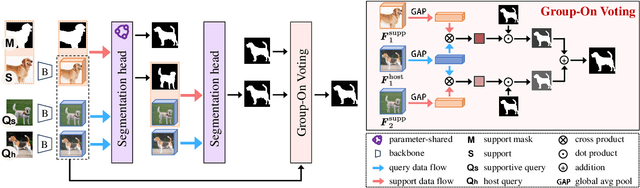

One-shot semantic segmentation aims to segment query images given only ONE annotated support image of the same class. This task is challenging because target objects in the support and query images can be largely different in appearance and pose (i.e., intra-class variation). Prior works suggested that incorporating more annotated support images in few-shot settings boosts performances but increases costs due to additional manual labeling. In this paper, we propose a novel approach for ONE-shot semantic segmentation, called Group-On, which packs multiple query images in batches for the benefit of mutual knowledge support within the same category. Specifically, after coarse segmentation masks of the batch of queries are predicted, query-mask pairs act as pseudo support data to enhance mask predictions mutually, under the guidance of a simple Group-On Voting module. Comprehensive experiments on three standard benchmarks show that, in the ONE-shot setting, our Group-On approach significantly outperforms previous works by considerable margins. For example, on the COCO-20i dataset, we increase mIoU scores by 8.21% and 7.46% on ASNet and HSNet baselines, respectively. With only one support image, Group-On can be even competitive with the counterparts using 5 annotated support images.
Multi-rater Prompting for Ambiguous Medical Image Segmentation
Apr 11, 2024Multi-rater annotations commonly occur when medical images are independently annotated by multiple experts (raters). In this paper, we tackle two challenges arisen in multi-rater annotations for medical image segmentation (called ambiguous medical image segmentation): (1) How to train a deep learning model when a group of raters produces a set of diverse but plausible annotations, and (2) how to fine-tune the model efficiently when computation resources are not available for re-training the entire model on a different dataset domain. We propose a multi-rater prompt-based approach to address these two challenges altogether. Specifically, we introduce a series of rater-aware prompts that can be plugged into the U-Net model for uncertainty estimation to handle multi-annotation cases. During the prompt-based fine-tuning process, only 0.3% of learnable parameters are required to be updated comparing to training the entire model. Further, in order to integrate expert consensus and disagreement, we explore different multi-rater incorporation strategies and design a mix-training strategy for comprehensive insight learning. Extensive experiments verify the effectiveness of our new approach for ambiguous medical image segmentation on two public datasets while alleviating the heavy burden of model re-training.
PoCo: A Self-Supervised Approach via Polar Transformation Based Progressive Contrastive Learning for Ophthalmic Disease Diagnosis
Mar 28, 2024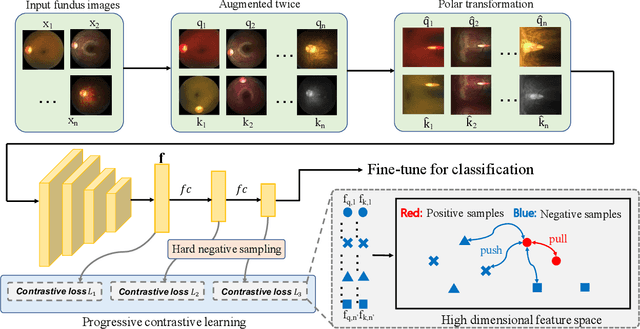
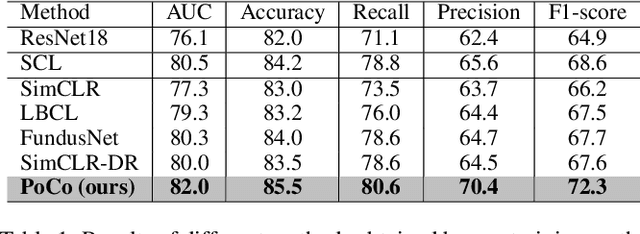


Automatic ophthalmic disease diagnosis on fundus images is important in clinical practice. However, due to complex fundus textures and limited annotated data, developing an effective automatic method for this problem is still challenging. In this paper, we present a self-supervised method via polar transformation based progressive contrastive learning, called PoCo, for ophthalmic disease diagnosis. Specifically, we novelly inject the polar transformation into contrastive learning to 1) promote contrastive learning pre-training to be faster and more stable and 2) naturally capture task-free and rotation-related textures, which provides insights into disease recognition on fundus images. Beneficially, simple normal translation-invariant convolution on transformed images can equivalently replace the complex rotation-invariant and sector convolution on raw images. After that, we develop a progressive contrastive learning method to efficiently utilize large unannotated images and a novel progressive hard negative sampling scheme to gradually reduce the negative sample number for efficient training and performance enhancement. Extensive experiments on three public ophthalmic disease datasets show that our PoCo achieves state-of-the-art performance with good generalization ability, validating that our method can reduce annotation efforts and provide reliable diagnosis. Codes are available at \url{https://github.com/wjh892521292/PoCo}.
Large Window-based Mamba UNet for Medical Image Segmentation: Beyond Convolution and Self-attention
Mar 12, 2024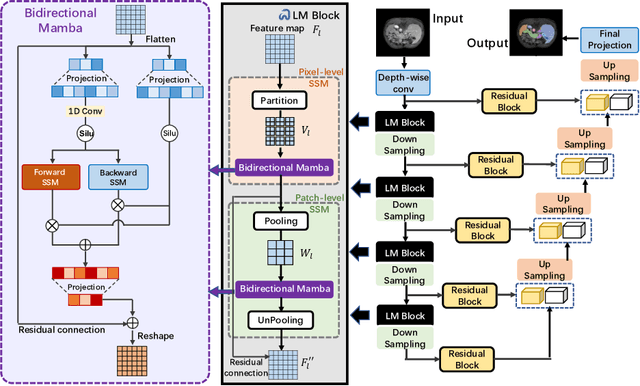
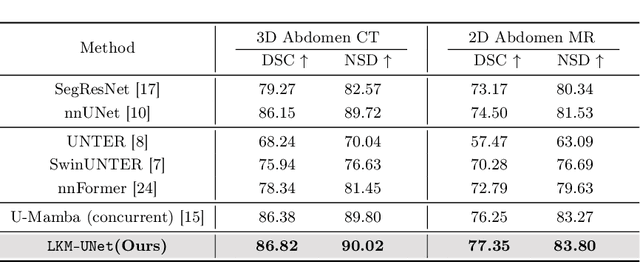


In clinical practice, medical image segmentation provides useful information on the contours and dimensions of target organs or tissues, facilitating improved diagnosis, analysis, and treatment. In the past few years, convolutional neural networks (CNNs) and Transformers have dominated this area, but they still suffer from either limited receptive fields or costly long-range modeling. Mamba, a State Space Sequence Model (SSM), recently emerged as a promising paradigm for long-range dependency modeling with linear complexity. In this paper, we introduce a Large Window-based Mamba U}-shape Network, or LMa-UNet, for 2D and 3D medical image segmentation. A distinguishing feature of our LMa-UNet is its utilization of large windows, excelling in locally spatial modeling compared to small kernel-based CNNs and small window-based Transformers, while maintaining superior efficiency in global modeling compared to self-attention with quadratic complexity. Additionally, we design a novel hierarchical and bidirectional Mamba block to further enhance the global and neighborhood spatial modeling capability of Mamba. Comprehensive experiments demonstrate the effectiveness and efficiency of our method and the feasibility of using large window size to achieve large receptive fields. Codes are available at https://github.com/wjh892521292/LMa-UNet.