 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate, fast, cheap: Choose three. Replacing Multi-Head-Attention with Bidirectional Recurrent Attention for Long-Form ASR
Jun 24, 2025Long-form speech recognition is an application area of increasing research focus. ASR models based on multi-head attention (MHA) are ill-suited to long-form ASR because of their quadratic complexity in sequence length. We build on recent work that has investigated linear complexity recurrent attention (RA) layers for ASR. We find that bidirectional RA layers can match the accuracy of MHA for both short- and long-form applications. We present a strong limited-context attention (LCA) baseline, and show that RA layers are just as accurate while being more efficient. We develop a long-form training paradigm which further improves RA performance, leading to better accuracy than LCA with 44% higher throughput. We also present Direction Dropout, a novel regularization method that improves accuracy, provides fine-grained control of the accuracy/throughput trade-off of bidirectional RA, and enables a new alternating directions decoding mode with even higher throughput.
Style-agnostic evaluation of ASR using multiple reference transcripts
Dec 10, 2024



Word error rate (WER) as a metric has a variety of limitations that have plagued the field of speech recognition. Evaluation datasets suffer from varying style, formality, and inherent ambiguity of the transcription task. In this work, we attempt to mitigate some of these differences by performing style-agnostic evaluation of ASR systems using multiple references transcribed under opposing style parameters. As a result, we find that existing WER reports are likely significantly over-estimating the number of contentful errors made by state-of-the-art ASR systems. In addition, we have found our multireference method to be a useful mechanism for comparing the quality of ASR models that differ in the stylistic makeup of their training data and target task.
Reverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Sum-Product Networks for Sequence Labeling
Jul 06, 2018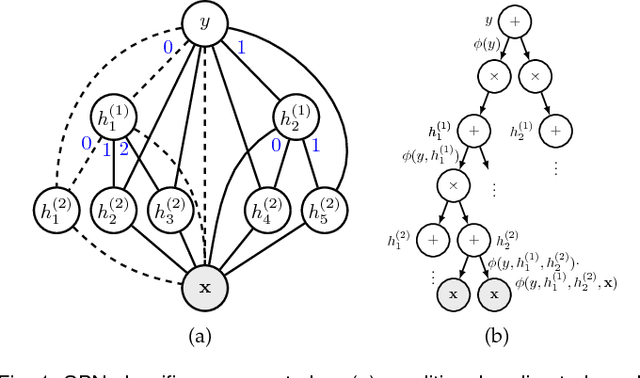
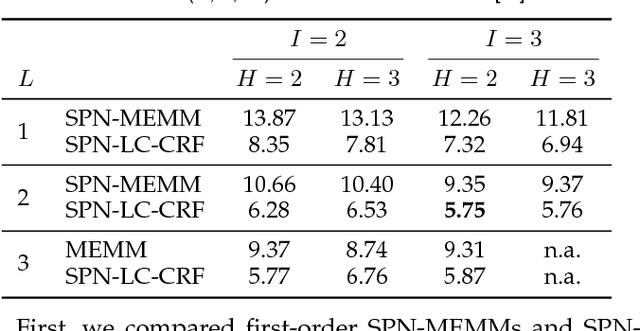
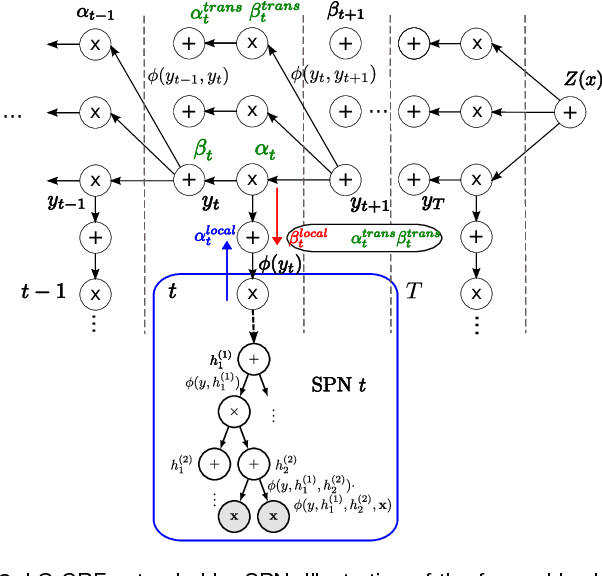

We consider higher-order linear-chain conditional random fields (HO-LC-CRFs) for sequence modelling, and use sum-product networks (SPNs) for representing higher-order input- and output-dependent factors. SPNs are a recently introduced class of deep models for which exact and efficient inference can be performed. By combining HO-LC-CRFs with SPNs, expressive models over both the output labels and the hidden variables are instantiated while still enabling efficient exact inference. Furthermore, the use of higher-order factors allows us to capture relations of multiple input segments and multiple output labels as often present in real-world data. These relations can not be modelled by the commonly used first-order models and higher-order models with local factors including only a single output label. We demonstrate the effectiveness of our proposed models for sequence labeling. In extensive experiments, we outperform other state-of-the-art methods in optical character recognition and achieve competitive results in phone classification.