 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
BUT VOiCES 2019 System Description
Jul 13, 2019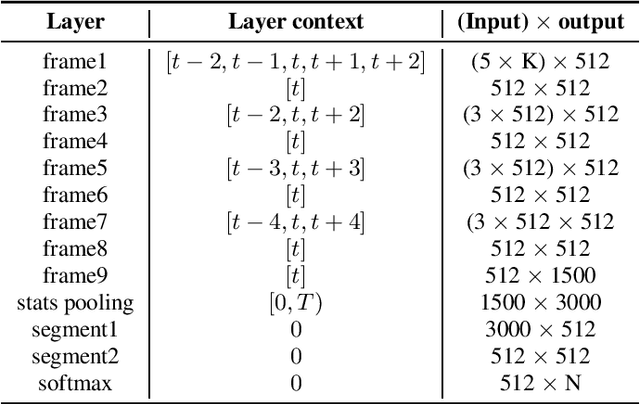
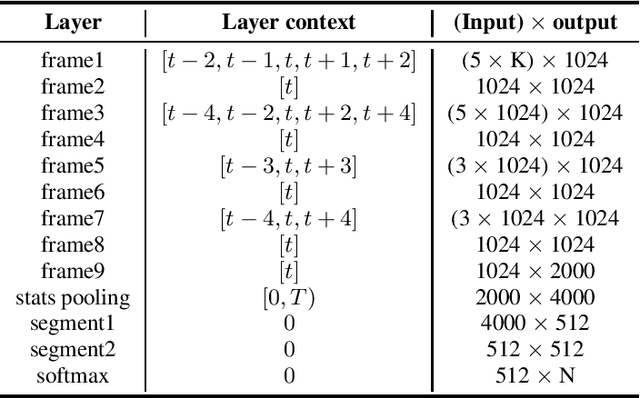
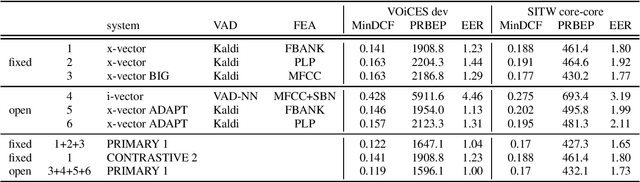
This is a description of our effort in VOiCES 2019 Speaker Recognition challenge. All systems in the fixed condition are based on the x-vector paradigm with different features and DNN topologies. The single best system reaches 1.2% EER and a fusion of 3 systems yields 1.0% EER, which is 15% relative improvement. The open condition allowed us to use external data which we did for the PLDA adaptation and achieved less than ~10% relative improvement. In the submission to open condition, we used 3 x-vector systems and also one i-vector based system.