Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUT VOiCES 2019 System Description
Paper and Code
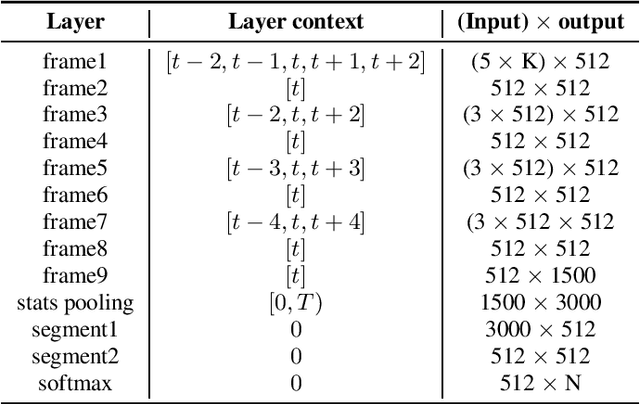
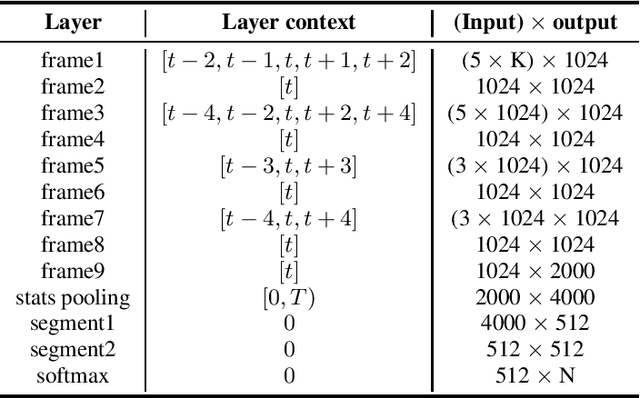
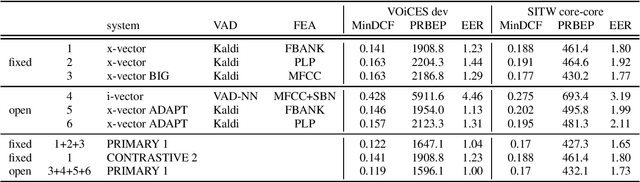
This is a description of our effort in VOiCES 2019 Speaker Recognition challenge. All systems in the fixed condition are based on the x-vector paradigm with different features and DNN topologies. The single best system reaches 1.2% EER and a fusion of 3 systems yields 1.0% EER, which is 15% relative improvement. The open condition allowed us to use external data which we did for the PLDA adaptation and achieved less than ~10% relative improvement. In the submission to open condition, we used 3 x-vector systems and also one i-vector based system.
View paper on