 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate, fast, cheap: Choose three. Replacing Multi-Head-Attention with Bidirectional Recurrent Attention for Long-Form ASR
Jun 24, 2025Long-form speech recognition is an application area of increasing research focus. ASR models based on multi-head attention (MHA) are ill-suited to long-form ASR because of their quadratic complexity in sequence length. We build on recent work that has investigated linear complexity recurrent attention (RA) layers for ASR. We find that bidirectional RA layers can match the accuracy of MHA for both short- and long-form applications. We present a strong limited-context attention (LCA) baseline, and show that RA layers are just as accurate while being more efficient. We develop a long-form training paradigm which further improves RA performance, leading to better accuracy than LCA with 44% higher throughput. We also present Direction Dropout, a novel regularization method that improves accuracy, provides fine-grained control of the accuracy/throughput trade-off of bidirectional RA, and enables a new alternating directions decoding mode with even higher throughput.
Reverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Updated Corpora and Benchmarks for Long-Form Speech Recognition
Sep 26, 2023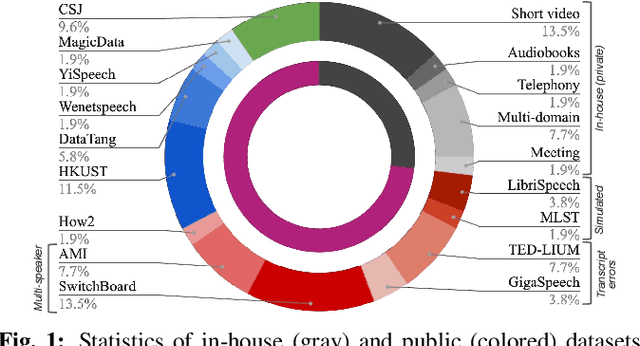
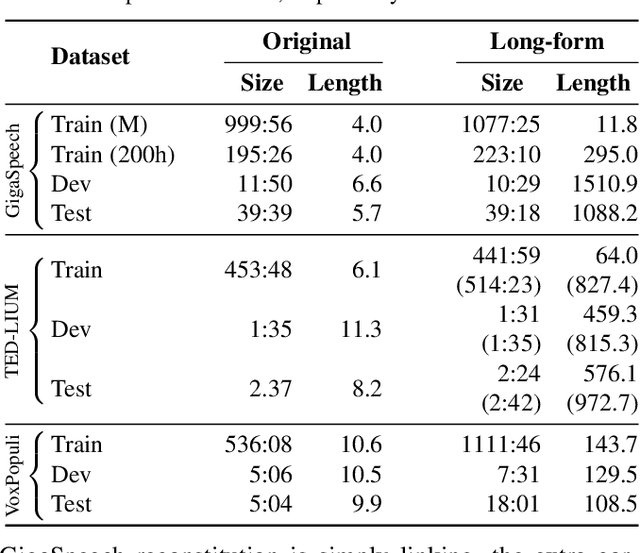

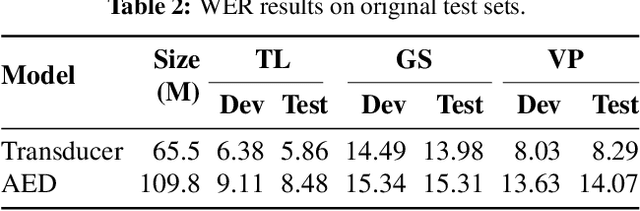
The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.
Improving Contextual Recognition of Rare Words with an Alternate Spelling Prediction Model
Sep 02, 2022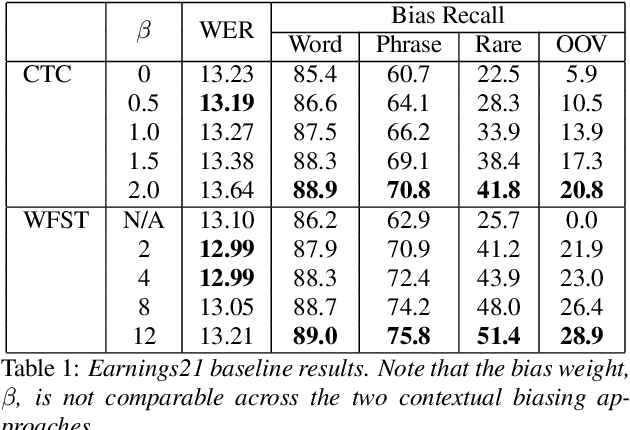
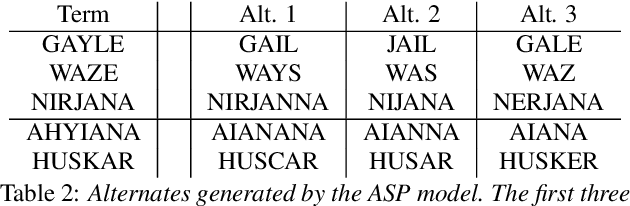
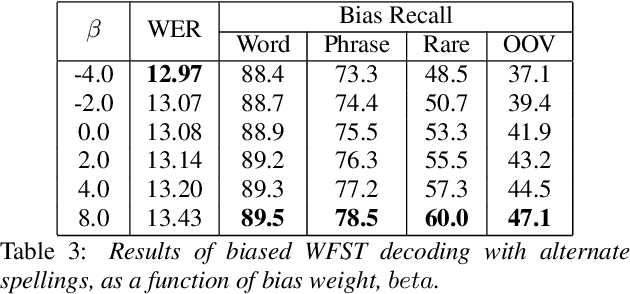
Contextual ASR, which takes a list of bias terms as input along with audio, has drawn recent interest as ASR use becomes more widespread. We are releasing contextual biasing lists to accompany the Earnings21 dataset, creating a public benchmark for this task. We present baseline results on this benchmark using a pretrained end-to-end ASR model from the WeNet toolkit. We show results for shallow fusion contextual biasing applied to two different decoding algorithms. Our baseline results confirm observations that end-to-end models struggle in particular with words that are rarely or never seen during training, and that existing shallow fusion techniques do not adequately address this problem. We propose an alternate spelling prediction model that improves recall of rare words by 34.7% relative and of out-of-vocabulary words by 97.2% relative, compared to contextual biasing without alternate spellings. This model is conceptually similar to ones used in prior work, but is simpler to implement as it does not rely on either a pronunciation dictionary or an existing text-to-speech system.
Curriculum optimization for low-resource speech recognition
Feb 17, 2022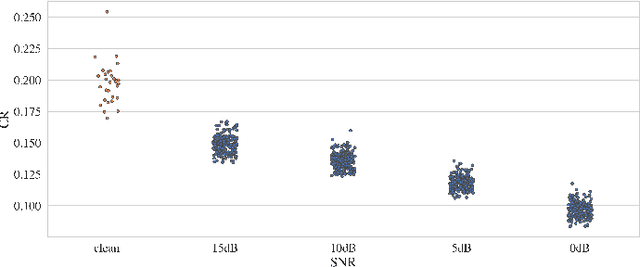
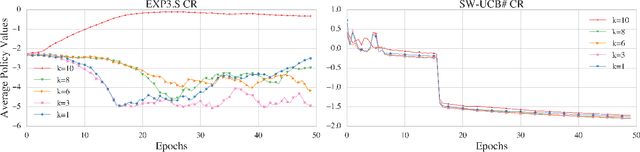
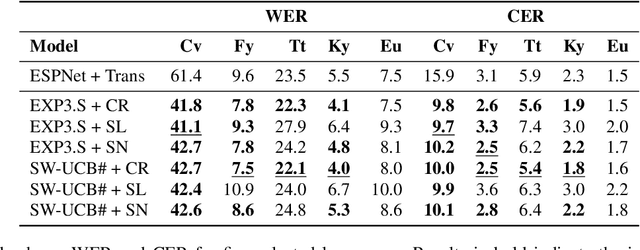
Modern end-to-end speech recognition models show astonishing results in transcribing audio signals into written text. However, conventional data feeding pipelines may be sub-optimal for low-resource speech recognition, which still remains a challenging task. We propose an automated curriculum learning approach to optimize the sequence of training examples based on both the progress of the model while training and prior knowledge about the difficulty of the training examples. We introduce a new difficulty measure called compression ratio that can be used as a scoring function for raw audio in various noise conditions. The proposed method improves speech recognition Word Error Rate performance by up to 33% relative over the baseline system