 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Contextual Recognition of Rare Words with an Alternate Spelling Prediction Model
Paper and Code
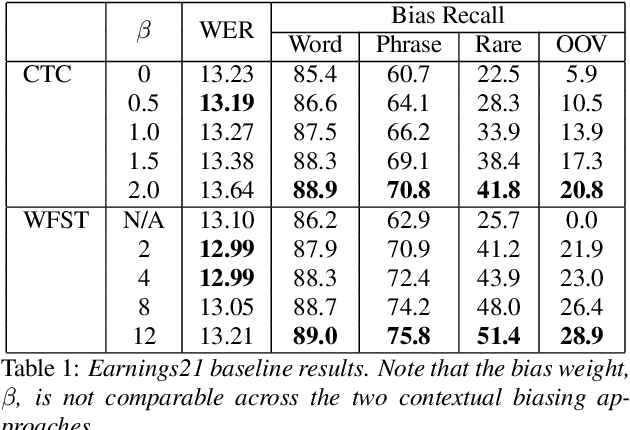
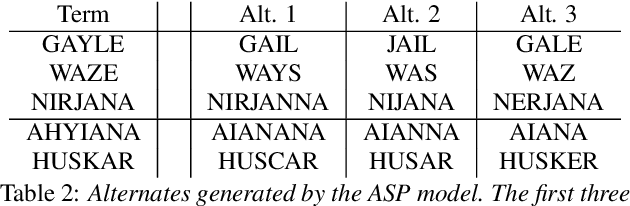
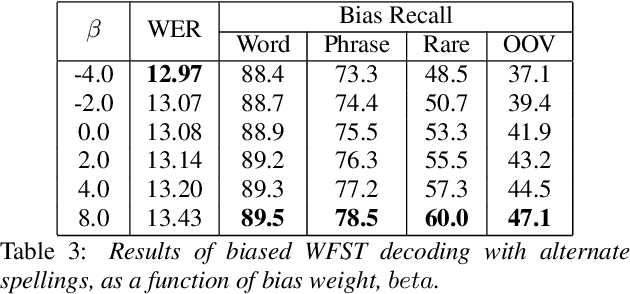
Contextual ASR, which takes a list of bias terms as input along with audio, has drawn recent interest as ASR use becomes more widespread. We are releasing contextual biasing lists to accompany the Earnings21 dataset, creating a public benchmark for this task. We present baseline results on this benchmark using a pretrained end-to-end ASR model from the WeNet toolkit. We show results for shallow fusion contextual biasing applied to two different decoding algorithms. Our baseline results confirm observations that end-to-end models struggle in particular with words that are rarely or never seen during training, and that existing shallow fusion techniques do not adequately address this problem. We propose an alternate spelling prediction model that improves recall of rare words by 34.7% relative and of out-of-vocabulary words by 97.2% relative, compared to contextual biasing without alternate spellings. This model is conceptually similar to ones used in prior work, but is simpler to implement as it does not rely on either a pronunciation dictionary or an existing text-to-speech system.