 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Forensics of Manipulated Segments in Untrimmed Long Videos
Jun 01, 2026The rapid advancement of AI-driven video generation has transformed content creation, while simultaneously increasing the risk of misinformation through localized manipulations in long-form videos. Existing video forensic methods predominantly operate on short, independent clips, and thus fail to capture realistic scenarios where AI-generated content is sparsely embedded within otherwise authentic footage. To bridge this gap, we formulate the task of Temporal AI-Generated Segment Localization and Explanation, which targets authenticity detection, temporal localization, and interpretable analysis of manipulated segments in untrimmed long videos. We further introduce TASLE, a large-scale benchmark comprising 12,472 untrimmed videos with diverse manipulation patterns and rich annotation signals, including temporal boundaries, authenticity labels, and segment-level rationales. In addition, we propose MSLoc, a coarse-to-fine forensic baseline that combines a boundary-sensitive proposal generation module for efficient long-video scanning with an MLLM-based refinement module for precise boundary localization and interpretable reasoning. Experiments validate the effectiveness of the proposed baseline, highlighting the importance of segment-level explainable forensics for long-form AI-generated video analysis. Our dataset and code are publicly available at https://debby-0527.github.io/TASLE.
InstructSAM: Segment Any Instance with Any Instructions
May 25, 2026In this paper, we introduce InstructSAM, a unified and streamlined framework designed for multi-instance segmentation under arbitrary instructions. We formulates instruction-driven instance segmentation as a set-structured query prediction problem and propose an explicit reasoning-to-instance query interface that elegantly bridges a vision-language model (VLM) and SAM3. Specifically, a bank of learnable instance queries is injected into the VLM and contextualized with instruction and visual information, enabling each query to serve as an instance-aware slot. A hybrid-attention mechanism further promotes interaction among these queries, visual tokens, and instruction tokens, improving instance enumeration and reducing duplicate predictions. The resulting LLM-conditioned queries are projected into SAM3's detector query space to drive accurate multi-instance segmentation in a single forward pass. This design equips SAM3 with high-level instruction understanding, compositional reasoning, and instance-level set prediction without modifying its core architecture. To support training and evaluation, we further construct Inst2Seg, a high-quality and large-scale instruction-based instance segmentation dataset and benchmark that couples free-form instructions with instance-level masks. Extensive experiments show that only 2B-scale InstructSAM achieves strong results across complex instruction-driven and phrase-level referring segmentation benchmarks, outperforming prior end-to-end methods and SAM3's agentic pipeline while enabling efficient single-pass multi-instance prediction.
LMMs Meet Object-Centric Vision: Understanding, Segmentation, Editing and Generation
Apr 13, 2026Large Multimodal Models (LMMs) have achieved remarkable progress in general-purpose vision--language understanding, yet they remain limited in tasks requiring precise object-level grounding, fine-grained spatial reasoning, and controllable visual manipulation. In particular, existing systems often struggle to identify the correct instance, preserve object identity across interactions, and localize or modify designated regions with high precision. Object-centric vision provides a principled framework for addressing these challenges by promoting explicit representations and operations over visual entities, thereby extending multimodal systems from global scene understanding to object-level understanding, segmentation, editing, and generation. This paper presents a comprehensive review of recent advances at the convergence of LMMs and object-centric vision. We organize the literature into four major themes: object-centric visual understanding, object-centric referring segmentation, object-centric visual editing, and object-centric visual generation. We further summarize the key modeling paradigms, learning strategies, and evaluation protocols that support these capabilities. Finally, we discuss open challenges and future directions, including robust instance permanence, fine-grained spatial control, consistent multi-step interaction, unified cross-task modeling, and reliable benchmarking under distribution shift. We hope this paper provides a structured perspective on the development of scalable, precise, and trustworthy object-centric multimodal systems.
AgentVLN: Towards Agentic Vision-and-Language Navigation
Mar 18, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to ground complex natural-language instructions into long-horizon navigation in unseen environments. While Vision-Language Models (VLMs) offer strong 2D semantic understanding, current VLN systems remain constrained by limited spatial perception, 2D-3D representation mismatch, and monocular scale ambiguity. In this paper, we propose AgentVLN, a novel and efficient embodied navigation framework that can be deployed on edge computing platforms. We formulate VLN as a Partially Observable Semi-Markov Decision Process (POSMDP) and introduce a VLM-as-Brain paradigm that decouples high-level semantic reasoning from perception and planning via a plug-and-play skill library. To resolve multi-level representation inconsistency, we design a cross-space representation mapping that projects perception-layer 3D topological waypoints into the image plane, yielding pixel-aligned visual prompts for the VLM. Building on this bridge, we integrate a context-aware self-correction and active exploration strategy to recover from occlusions and suppress error accumulation over long trajectories. To further address the spatial ambiguity of instructions in unstructured environments, we propose a Query-Driven Perceptual Chain-of-Thought (QD-PCoT) scheme, enabling the agent with the metacognitive ability to actively seek geometric depth information. Finally, we construct AgentVLN-Instruct, a large-scale instruction-tuning dataset with dynamic stage routing conditioned on target visibility. Extensive experiments show that AgentVLN consistently outperforms prior state-of-the-art methods (SOTA) on long-horizon VLN benchmarks, offering a practical paradigm for lightweight deployment of next-generation embodied navigation models. Code: https://github.com/Allenxinn/AgentVLN.
DecoVLN: Decoupling Observation, Reasoning, and Correction for Vision-and-Language Navigation
Mar 13, 2026Vision-and-Language Navigation (VLN) requires agents to follow long-horizon instructions and navigate complex 3D environments. However, existing approaches face two major challenges: constructing an effective long-term memory bank and overcoming the compounding errors problem. To address these issues, we propose DecoVLN, an effective framework designed for robust streaming perception and closed-loop control in long-horizon navigation. First, we formulate long-term memory construction as an optimization problem and introduce adaptive refinement mechanism that selects frames from a historical candidate pool by iteratively optimizing a unified scoring function. This function jointly balances three key criteria: semantic relevance to the instruction, visual diversity from the selected memory, and temporal coverage of the historical trajectory. Second, to alleviate compounding errors, we introduce a state-action pair-level corrective finetuning strategy. By leveraging geodesic distance between states to precisely quantify deviation from the expert trajectory, the agent collects high-quality state-action pairs in the trusted region while filtering out the polluted data with low relevance. This improves both the efficiency and stability of error correction. Extensive experiments demonstrate the effectiveness of DecoVLN, and we have deployed it in real-world environments.
VisionTrim: Unified Vision Token Compression for Training-Free MLLM Acceleration
Jan 30, 2026Multimodal large language models (MLLMs) suffer from high computational costs due to excessive visual tokens, particularly in high-resolution and video-based scenarios. Existing token reduction methods typically focus on isolated pipeline components and often neglect textual alignment, leading to performance degradation. In this paper, we propose VisionTrim, a unified framework for training-free MLLM acceleration, integrating two effective plug-and-play modules: 1) the Dominant Vision Token Selection (DVTS) module, which preserves essential visual tokens via a global-local view, and 2) the Text-Guided Vision Complement (TGVC) module, which facilitates context-aware token merging guided by textual cues. Extensive experiments across diverse image and video multimodal benchmarks demonstrate the performance superiority of our VisionTrim, advancing practical MLLM deployment in real-world applications. The code is available at: https://github.com/hanxunyu/VisionTrim.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
Tailored Teaching with Balanced Difficulty: Elevating Reasoning in Multimodal Chain-of-Thought via Prompt Curriculum
Aug 26, 2025The effectiveness of Multimodal Chain-of-Thought (MCoT) prompting is often limited by the use of randomly or manually selected examples. These examples fail to account for both model-specific knowledge distributions and the intrinsic complexity of the tasks, resulting in suboptimal and unstable model performance. To address this, we propose a novel framework inspired by the pedagogical principle of "tailored teaching with balanced difficulty". We reframe prompt selection as a prompt curriculum design problem: constructing a well ordered set of training examples that align with the model's current capabilities. Our approach integrates two complementary signals: (1) model-perceived difficulty, quantified through prediction disagreement in an active learning setup, capturing what the model itself finds challenging; and (2) intrinsic sample complexity, which measures the inherent difficulty of each question-image pair independently of any model. By jointly analyzing these signals, we develop a difficulty-balanced sampling strategy that ensures the selected prompt examples are diverse across both dimensions. Extensive experiments conducted on five challenging benchmarks and multiple popular Multimodal Large Language Models (MLLMs) demonstrate that our method yields substantial and consistent improvements and greatly reduces performance discrepancies caused by random sampling, providing a principled and robust approach for enhancing multimodal reasoning.
EOC-Bench: Can MLLMs Identify, Recall, and Forecast Objects in an Egocentric World?
Jun 05, 2025



The emergence of multimodal large language models (MLLMs) has driven breakthroughs in egocentric vision applications. These applications necessitate persistent, context-aware understanding of objects, as users interact with tools in dynamic and cluttered environments. However, existing embodied benchmarks primarily focus on static scene exploration, emphasizing object's appearance and spatial attributes while neglecting the assessment of dynamic changes arising from users' interactions. To address this gap, we introduce EOC-Bench, an innovative benchmark designed to systematically evaluate object-centric embodied cognition in dynamic egocentric scenarios. Specially, EOC-Bench features 3,277 meticulously annotated QA pairs categorized into three temporal categories: Past, Present, and Future, covering 11 fine-grained evaluation dimensions and 3 visual object referencing types. To ensure thorough assessment, we develop a mixed-format human-in-the-loop annotation framework with four types of questions and design a novel multi-scale temporal accuracy metric for open-ended temporal evaluation. Based on EOC-Bench, we conduct comprehensive evaluations of various proprietary, open-source, and object-level MLLMs. EOC-Bench serves as a crucial tool for advancing the embodied object cognitive capabilities of MLLMs, establishing a robust foundation for developing reliable core models for embodied systems.
PointLoRA: Low-Rank Adaptation with Token Selection for Point Cloud Learning
Apr 22, 2025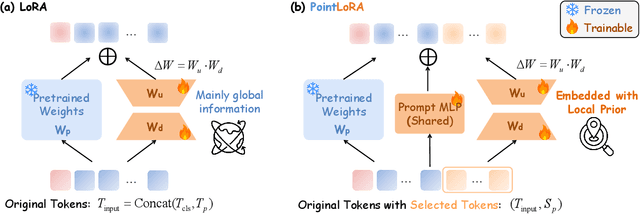
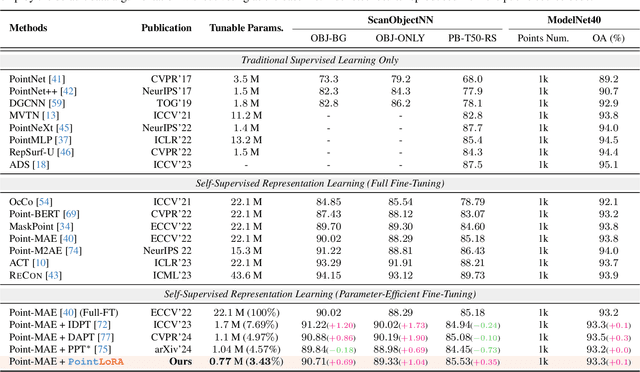
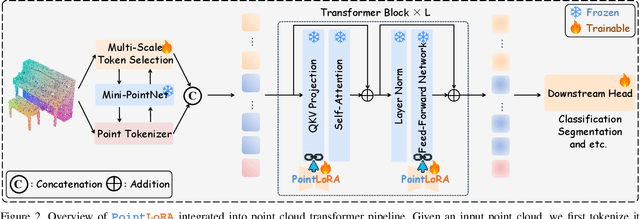
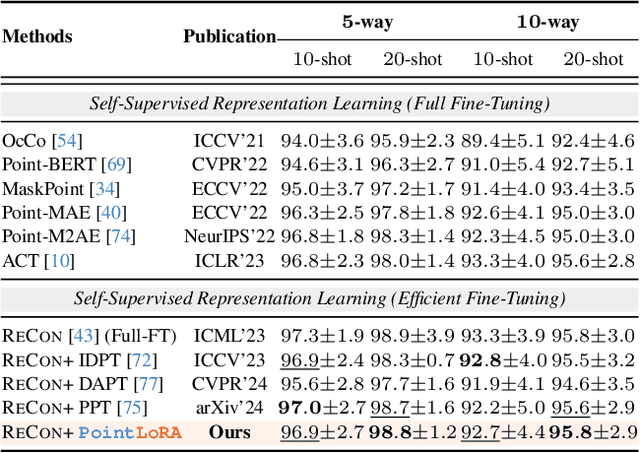
Self-supervised representation learning for point cloud has demonstrated effectiveness in improving pre-trained model performance across diverse tasks. However, as pre-trained models grow in complexity, fully fine-tuning them for downstream applications demands substantial computational and storage resources. Parameter-efficient fine-tuning (PEFT) methods offer a promising solution to mitigate these resource requirements, yet most current approaches rely on complex adapter and prompt mechanisms that increase tunable parameters. In this paper, we propose PointLoRA, a simple yet effective method that combines low-rank adaptation (LoRA) with multi-scale token selection to efficiently fine-tune point cloud models. Our approach embeds LoRA layers within the most parameter-intensive components of point cloud transformers, reducing the need for tunable parameters while enhancing global feature capture. Additionally, multi-scale token selection extracts critical local information to serve as prompts for downstream fine-tuning, effectively complementing the global context captured by LoRA. The experimental results across various pre-trained models and three challenging public datasets demonstrate that our approach achieves competitive performance with only 3.43% of the trainable parameters, making it highly effective for resource-constrained applications. Source code is available at: https://github.com/songw-zju/PointLoRA.