 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Multi-View Hand Reconstruction Using Inverse Rendering
Jul 09, 2024Reconstructing high-fidelity hand models with intricate textures plays a crucial role in enhancing human-object interaction and advancing real-world applications. Despite the state-of-the-art methods excelling in texture generation and image rendering, they often face challenges in accurately capturing geometric details. Learning-based approaches usually offer better robustness and faster inference, which tend to produce smoother results and require substantial amounts of training data. To address these issues, we present a novel fine-grained multi-view hand mesh reconstruction method that leverages inverse rendering to restore hand poses and intricate details. Firstly, our approach predicts a parametric hand mesh model through Graph Convolutional Networks (GCN) based method from multi-view images. We further introduce a novel Hand Albedo and Mesh (HAM) optimization module to refine both the hand mesh and textures, which is capable of preserving the mesh topology. In addition, we suggest an effective mesh-based neural rendering scheme to simultaneously generate photo-realistic image and optimize mesh geometry by fusing the pre-trained rendering network with vertex features. We conduct the comprehensive experiments on InterHand2.6M, DeepHandMesh and dataset collected by ourself, whose promising results show that our proposed approach outperforms the state-of-the-art methods on both reconstruction accuracy and rendering quality. Code and dataset are publicly available at https://github.com/agnJason/FMHR.
Pyramid Deep Fusion Network for Two-Hand Reconstruction from RGB-D Images
Jul 12, 2023Accurately recovering the dense 3D mesh of both hands from monocular images poses considerable challenges due to occlusions and projection ambiguity. Most of the existing methods extract features from color images to estimate the root-aligned hand meshes, which neglect the crucial depth and scale information in the real world. Given the noisy sensor measurements with limited resolution, depth-based methods predict 3D keypoints rather than a dense mesh. These limitations motivate us to take advantage of these two complementary inputs to acquire dense hand meshes on a real-world scale. In this work, we propose an end-to-end framework for recovering dense meshes for both hands, which employ single-view RGB-D image pairs as input. The primary challenge lies in effectively utilizing two different input modalities to mitigate the blurring effects in RGB images and noises in depth images. Instead of directly treating depth maps as additional channels for RGB images, we encode the depth information into the unordered point cloud to preserve more geometric details. Specifically, our framework employs ResNet50 and PointNet++ to derive features from RGB and point cloud, respectively. Additionally, we introduce a novel pyramid deep fusion network (PDFNet) to aggregate features at different scales, which demonstrates superior efficacy compared to previous fusion strategies. Furthermore, we employ a GCN-based decoder to process the fused features and recover the corresponding 3D pose and dense mesh. Through comprehensive ablation experiments, we have not only demonstrated the effectiveness of our proposed fusion algorithm but also outperformed the state-of-the-art approaches on publicly available datasets. To reproduce the results, we will make our source code and models publicly available at {\url{https://github.com/zijinxuxu/PDFNet}}.
End-to-end Weakly-supervised Multiple 3D Hand Mesh Reconstruction from Single Image
Apr 18, 2022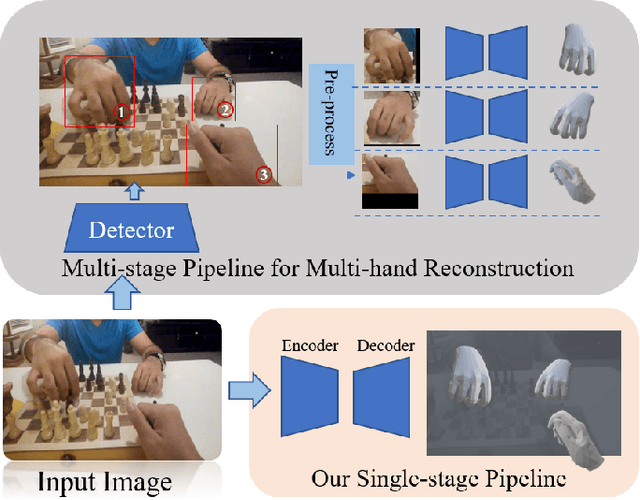


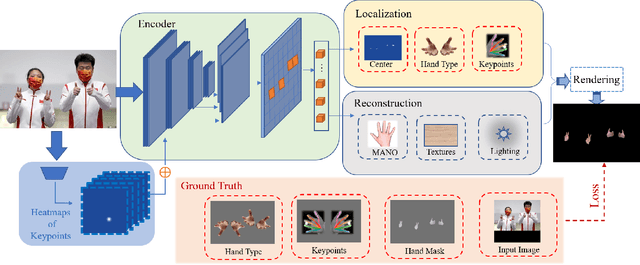
In this paper, we consider the challenging task of simultaneously locating and recovering multiple hands from single 2D image. Previous studies either focus on single hand reconstruction or solve this problem in a multi-stage way. Moreover, the conventional two-stage pipeline firstly detects hand areas, and then estimates 3D hand pose from each cropped patch. To reduce the computational redundancy in preprocessing and feature extraction, we propose a concise but efficient single-stage pipeline. Specifically, we design a multi-head auto-encoder structure for multi-hand reconstruction, where each head network shares the same feature map and outputs the hand center, pose and texture, respectively. Besides, we adopt a weakly-supervised scheme to alleviate the burden of expensive 3D real-world data annotations. To this end, we propose a series of losses optimized by a stage-wise training scheme, where a multi-hand dataset with 2D annotations is generated based on the publicly available single hand datasets. In order to further improve the accuracy of the weakly supervised model, we adopt several feature consistency constraints in both single and multiple hand settings. Specifically, the keypoints of each hand estimated from local features should be consistent with the re-projected points predicted from global features. Extensive experiments on public benchmarks including FreiHAND, HO3D, InterHand2.6M and RHD demonstrate that our method outperforms the state-of-the-art model-based methods in both weakly-supervised and fully-supervised manners.
Effective Occlusion Handling for Fast Correlation Filter-based Trackers
Jul 13, 2018



Correlation filter-based trackers heavily suffer from the problem of multiple peaks in their response maps incurred by occlusions. Moreover, the whole tracking pipeline may break down due to the uncertainties brought by shifting among peaks, which will further lead to the degraded correlation filter model. To alleviate the drift problem caused by occlusions, we propose a novel scheme to choose the specific filter model according to different scenarios. Specifically, an effective measurement function is designed to evaluate the quality of filter response. A sophisticated strategy is employed to judge whether occlusions occur, and then decide how to update the filter models. In addition, we take advantage of both log-polar method and pyramid-like approach to estimate the best scale of the target. We evaluate our proposed approach on VOT2018 challenge and OTB100 dataset, whose experimental result shows that the proposed tracker achieves the promising performance compared against the state-of-the-art trackers.