 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Personalized Understanding, Generating and Editing
Jan 11, 2026Unified large multimodal models (LMMs) have achieved remarkable progress in general-purpose multimodal understanding and generation. However, they still operate under a ``one-size-fits-all'' paradigm and struggle to model user-specific concepts (e.g., generate a photo of \texttt{<maeve>}) in a consistent and controllable manner. Existing personalization methods typically rely on external retrieval, which is inefficient and poorly integrated into unified multimodal pipelines. Recent personalized unified models introduce learnable soft prompts to encode concept information, yet they either couple understanding and generation or depend on complex multi-stage training, leading to cross-task interference and ultimately to fuzzy or misaligned personalized knowledge. We present \textbf{OmniPersona}, an end-to-end personalization framework for unified LMMs that, for the first time, integrates personalized understanding, generation, and image editing within a single architecture. OmniPersona introduces structurally decoupled concept tokens, allocating dedicated subspaces for different tasks to minimize interference, and incorporates an explicit knowledge replay mechanism that propagates personalized attribute knowledge across tasks, enabling consistent personalized behavior. To systematically evaluate unified personalization, we propose \textbf{\texttt{OmniPBench}}, extending the public UnifyBench concept set with personalized editing tasks and cross-task evaluation protocols integrating understanding, generation, and editing. Experimental results demonstrate that OmniPersona delivers competitive and robust performance across diverse personalization tasks. We hope OmniPersona will serve as a strong baseline and spur further research on controllable, unified personalization.
AnyMS: Bottom-up Attention Decoupling for Layout-guided and Training-free Multi-subject Customization
Dec 29, 2025Multi-subject customization aims to synthesize multiple user-specified subjects into a coherent image. To address issues such as subjects missing or conflicts, recent works incorporate layout guidance to provide explicit spatial constraints. However, existing methods still struggle to balance three critical objectives: text alignment, subject identity preservation, and layout control, while the reliance on additional training further limits their scalability and efficiency. In this paper, we present AnyMS, a novel training-free framework for layout-guided multi-subject customization. AnyMS leverages three input conditions: text prompt, subject images, and layout constraints, and introduces a bottom-up dual-level attention decoupling mechanism to harmonize their integration during generation. Specifically, global decoupling separates cross-attention between textual and visual conditions to ensure text alignment. Local decoupling confines each subject's attention to its designated area, which prevents subject conflicts and thus guarantees identity preservation and layout control. Moreover, AnyMS employs pre-trained image adapters to extract subject-specific features aligned with the diffusion model, removing the need for subject learning or adapter tuning. Extensive experiments demonstrate that AnyMS achieves state-of-the-art performance, supporting complex compositions and scaling to a larger number of subjects.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
EOC-Bench: Can MLLMs Identify, Recall, and Forecast Objects in an Egocentric World?
Jun 05, 2025



The emergence of multimodal large language models (MLLMs) has driven breakthroughs in egocentric vision applications. These applications necessitate persistent, context-aware understanding of objects, as users interact with tools in dynamic and cluttered environments. However, existing embodied benchmarks primarily focus on static scene exploration, emphasizing object's appearance and spatial attributes while neglecting the assessment of dynamic changes arising from users' interactions. To address this gap, we introduce EOC-Bench, an innovative benchmark designed to systematically evaluate object-centric embodied cognition in dynamic egocentric scenarios. Specially, EOC-Bench features 3,277 meticulously annotated QA pairs categorized into three temporal categories: Past, Present, and Future, covering 11 fine-grained evaluation dimensions and 3 visual object referencing types. To ensure thorough assessment, we develop a mixed-format human-in-the-loop annotation framework with four types of questions and design a novel multi-scale temporal accuracy metric for open-ended temporal evaluation. Based on EOC-Bench, we conduct comprehensive evaluations of various proprietary, open-source, and object-level MLLMs. EOC-Bench serves as a crucial tool for advancing the embodied object cognitive capabilities of MLLMs, establishing a robust foundation for developing reliable core models for embodied systems.
ECBench: Can Multi-modal Foundation Models Understand the Egocentric World? A Holistic Embodied Cognition Benchmark
Jan 09, 2025



The enhancement of generalization in robots by large vision-language models (LVLMs) is increasingly evident. Therefore, the embodied cognitive abilities of LVLMs based on egocentric videos are of great interest. However, current datasets for embodied video question answering lack comprehensive and systematic evaluation frameworks. Critical embodied cognitive issues, such as robotic self-cognition, dynamic scene perception, and hallucination, are rarely addressed. To tackle these challenges, we propose ECBench, a high-quality benchmark designed to systematically evaluate the embodied cognitive abilities of LVLMs. ECBench features a diverse range of scene video sources, open and varied question formats, and 30 dimensions of embodied cognition. To ensure quality, balance, and high visual dependence, ECBench uses class-independent meticulous human annotation and multi-round question screening strategies. Additionally, we introduce ECEval, a comprehensive evaluation system that ensures the fairness and rationality of the indicators. Utilizing ECBench, we conduct extensive evaluations of proprietary, open-source, and task-specific LVLMs. ECBench is pivotal in advancing the embodied cognitive capabilities of LVLMs, laying a solid foundation for developing reliable core models for embodied agents. All data and code are available at https://github.com/Rh-Dang/ECBench.
VideoRefer Suite: Advancing Spatial-Temporal Object Understanding with Video LLM
Jan 08, 2025Video Large Language Models (Video LLMs) have recently exhibited remarkable capabilities in general video understanding. However, they mainly focus on holistic comprehension and struggle with capturing fine-grained spatial and temporal details. Besides, the lack of high-quality object-level video instruction data and a comprehensive benchmark further hinders their advancements. To tackle these challenges, we introduce the VideoRefer Suite to empower Video LLM for finer-level spatial-temporal video understanding, i.e., enabling perception and reasoning on any objects throughout the video. Specially, we thoroughly develop VideoRefer Suite across three essential aspects: dataset, model, and benchmark. Firstly, we introduce a multi-agent data engine to meticulously curate a large-scale, high-quality object-level video instruction dataset, termed VideoRefer-700K. Next, we present the VideoRefer model, which equips a versatile spatial-temporal object encoder to capture precise regional and sequential representations. Finally, we meticulously create a VideoRefer-Bench to comprehensively assess the spatial-temporal understanding capability of a Video LLM, evaluating it across various aspects. Extensive experiments and analyses demonstrate that our VideoRefer model not only achieves promising performance on video referring benchmarks but also facilitates general video understanding capabilities.
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024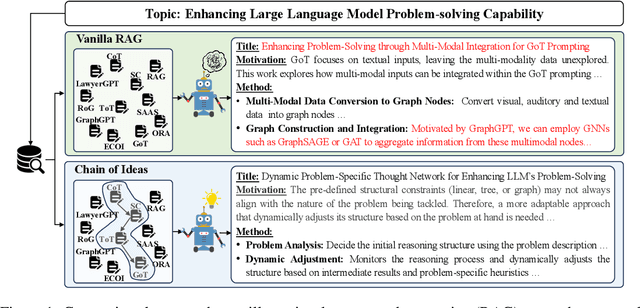

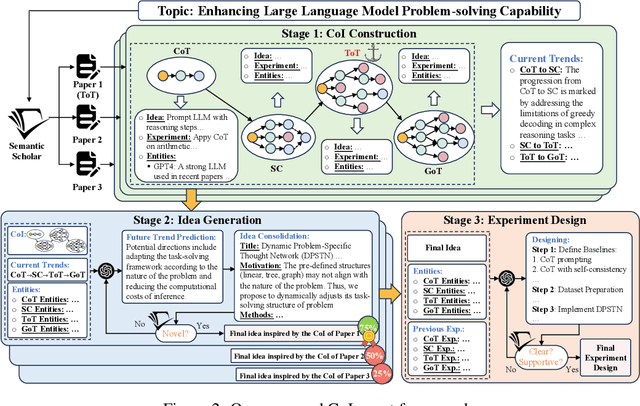
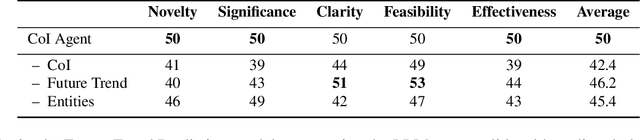
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
TokenPacker: Efficient Visual Projector for Multimodal LLM
Jul 02, 2024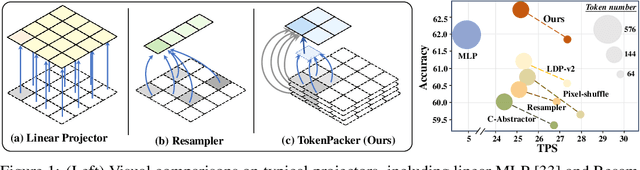
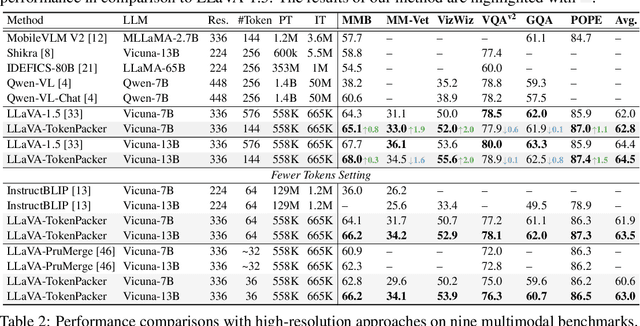
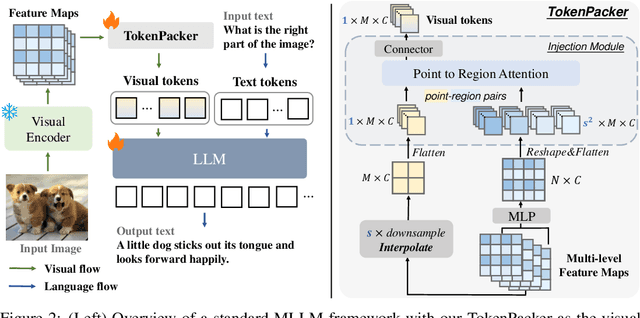
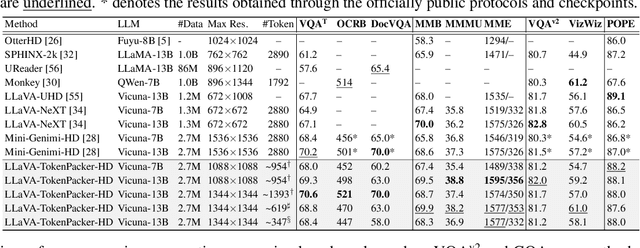
The visual projector serves as an essential bridge between the visual encoder and the Large Language Model (LLM) in a Multimodal LLM (MLLM). Typically, MLLMs adopt a simple MLP to preserve all visual contexts via one-to-one transformation. However, the visual tokens are redundant and can be considerably increased when dealing with high-resolution images, impairing the efficiency of MLLMs significantly. Some recent works have introduced resampler or abstractor to reduce the number of resulting visual tokens. Unfortunately, they fail to capture finer details and undermine the visual reasoning capabilities of MLLMs. In this work, we propose a novel visual projector, which adopts a coarse-to-fine scheme to inject the enriched characteristics to generate the condensed visual tokens. In specific, we first interpolate the visual features as a low-resolution point query, providing the overall visual representation as the foundation. Then, we introduce a region-to-point injection module that utilizes high-resolution, multi-level region-based cues as fine-grained reference keys and values, allowing them to be fully absorbed within the corresponding local context region. This step effectively updates the coarse point query, transforming it into an enriched one for the subsequent LLM reasoning. Extensive experiments demonstrate that our approach compresses the visual tokens by 75%~89%, while achieves comparable or even better performance across diverse benchmarks with significantly higher efficiency. The source codes can be found at https://github.com/CircleRadon/TokenPacker.
Osprey: Pixel Understanding with Visual Instruction Tuning
Dec 25, 2023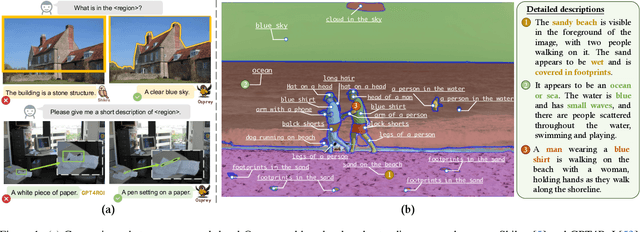



Multimodal large language models (MLLMs) have recently achieved impressive general-purpose vision-language capabilities through visual instruction tuning. However, current MLLMs primarily focus on image-level or box-level understanding, falling short of achieving fine-grained vision-language alignment at the pixel level. Besides, the lack of mask-based instruction data limits their advancements. In this paper, we propose Osprey, a mask-text instruction tuning approach, to extend MLLMs by incorporating fine-grained mask regions into language instruction, aiming at achieving pixel-wise visual understanding. To achieve this goal, we first meticulously curate a mask-based region-text dataset with 724K samples, and then design a vision-language model by injecting pixel-level representation into LLM. Especially, Osprey adopts a convolutional CLIP backbone as the vision encoder and employs a mask-aware visual extractor to extract precise visual mask features from high resolution input. Experimental results demonstrate Osprey's superiority in various region understanding tasks, showcasing its new capability for pixel-level instruction tuning. In particular, Osprey can be integrated with Segment Anything Model (SAM) seamlessly to obtain multi-granularity semantics. The source code, dataset and demo can be found at https://github.com/CircleRadon/Osprey.