 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELPD: Mitigating Hallucination of LVLMs by Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding
Sep 30, 2024
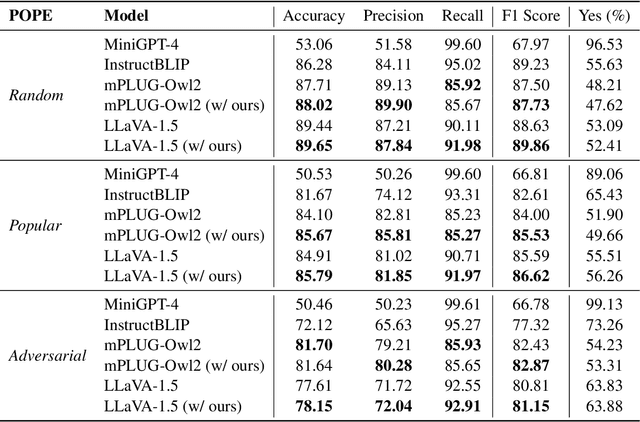
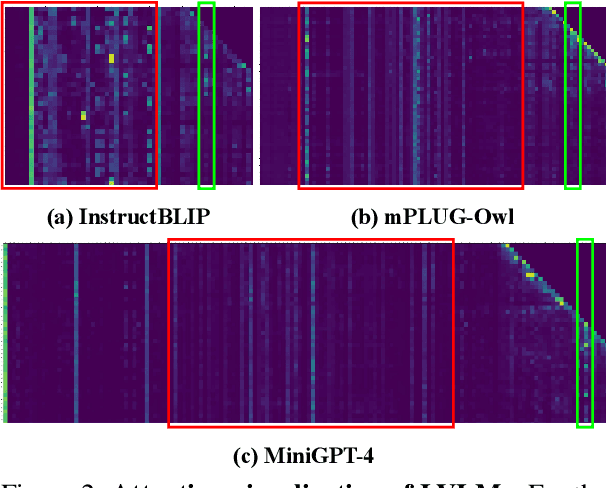

Large Vision-Language Models (LVLMs) have shown remarkable performance on many visual-language tasks. However, these models still suffer from multimodal hallucination, which means the generation of objects or content that violates the images. Many existing work detects hallucination by directly judging whether an object exists in an image, overlooking the association between the object and semantics. To address this issue, we propose Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding (HELPD). This framework incorporates hallucination feedback at both object and sentence semantic levels. Remarkably, even with a marginal degree of training, this approach can alleviate over 15% of hallucination. Simultaneously, HELPD penalizes the output logits according to the image attention window to avoid being overly affected by generated text. HELPD can be seamlessly integrated with any LVLMs. Our experiments demonstrate that the proposed framework yields favorable results across multiple hallucination benchmarks. It effectively mitigates hallucination for different LVLMs and concurrently improves their text generation quality.
Osprey: Pixel Understanding with Visual Instruction Tuning
Dec 25, 2023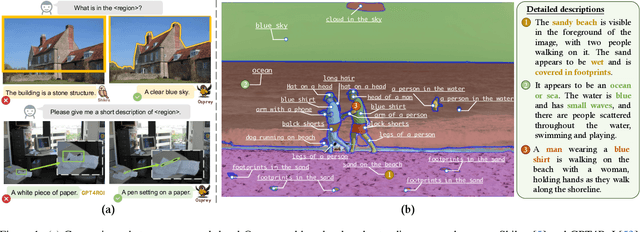



Multimodal large language models (MLLMs) have recently achieved impressive general-purpose vision-language capabilities through visual instruction tuning. However, current MLLMs primarily focus on image-level or box-level understanding, falling short of achieving fine-grained vision-language alignment at the pixel level. Besides, the lack of mask-based instruction data limits their advancements. In this paper, we propose Osprey, a mask-text instruction tuning approach, to extend MLLMs by incorporating fine-grained mask regions into language instruction, aiming at achieving pixel-wise visual understanding. To achieve this goal, we first meticulously curate a mask-based region-text dataset with 724K samples, and then design a vision-language model by injecting pixel-level representation into LLM. Especially, Osprey adopts a convolutional CLIP backbone as the vision encoder and employs a mask-aware visual extractor to extract precise visual mask features from high resolution input. Experimental results demonstrate Osprey's superiority in various region understanding tasks, showcasing its new capability for pixel-level instruction tuning. In particular, Osprey can be integrated with Segment Anything Model (SAM) seamlessly to obtain multi-granularity semantics. The source code, dataset and demo can be found at https://github.com/CircleRadon/Osprey.