 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructing
Jan 15, 2025Visual Commonsense Reasoning, which is regarded as one challenging task to pursue advanced visual scene comprehension, has been used to diagnose the reasoning ability of AI systems. However, reliable reasoning requires a good grasp of the scene's details. Existing work fails to effectively exploit the real-world object relationship information present within the scene, and instead overly relies on knowledge from training memory. Based on these observations, we propose a novel scene-graph-enhanced visual commonsense reasoning generation method named \textit{\textbf{G2}}, which first utilizes the image patches and LLMs to construct a location-free scene graph, and then answer and explain based on the scene graph's information. We also propose automatic scene graph filtering and selection strategies to absorb valuable scene graph information during training. Extensive experiments are conducted on the tasks and datasets of scene graph constructing and visual commonsense answering and explaining, respectively. Experimental results and ablation analysis demonstrate the effectiveness of our proposed framework.
HELPD: Mitigating Hallucination of LVLMs by Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding
Sep 30, 2024
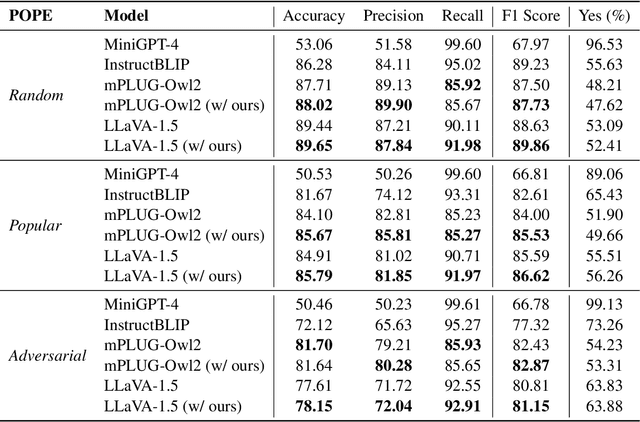
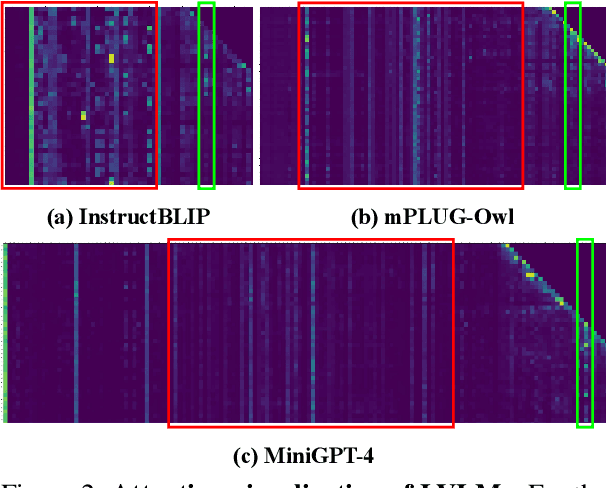

Large Vision-Language Models (LVLMs) have shown remarkable performance on many visual-language tasks. However, these models still suffer from multimodal hallucination, which means the generation of objects or content that violates the images. Many existing work detects hallucination by directly judging whether an object exists in an image, overlooking the association between the object and semantics. To address this issue, we propose Hierarchical Feedback Learning with Vision-enhanced Penalty Decoding (HELPD). This framework incorporates hallucination feedback at both object and sentence semantic levels. Remarkably, even with a marginal degree of training, this approach can alleviate over 15% of hallucination. Simultaneously, HELPD penalizes the output logits according to the image attention window to avoid being overly affected by generated text. HELPD can be seamlessly integrated with any LVLMs. Our experiments demonstrate that the proposed framework yields favorable results across multiple hallucination benchmarks. It effectively mitigates hallucination for different LVLMs and concurrently improves their text generation quality.