 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructing
Jan 15, 2025Visual Commonsense Reasoning, which is regarded as one challenging task to pursue advanced visual scene comprehension, has been used to diagnose the reasoning ability of AI systems. However, reliable reasoning requires a good grasp of the scene's details. Existing work fails to effectively exploit the real-world object relationship information present within the scene, and instead overly relies on knowledge from training memory. Based on these observations, we propose a novel scene-graph-enhanced visual commonsense reasoning generation method named \textit{\textbf{G2}}, which first utilizes the image patches and LLMs to construct a location-free scene graph, and then answer and explain based on the scene graph's information. We also propose automatic scene graph filtering and selection strategies to absorb valuable scene graph information during training. Extensive experiments are conducted on the tasks and datasets of scene graph constructing and visual commonsense answering and explaining, respectively. Experimental results and ablation analysis demonstrate the effectiveness of our proposed framework.
Pathformer3D: A 3D Scanpath Transformer for 360° Images
Jul 15, 2024Scanpath prediction in 360{\deg} images can help realize rapid rendering and better user interaction in Virtual/Augmented Reality applications. However, existing scanpath prediction models for 360{\deg} images execute scanpath prediction on 2D equirectangular projection plane, which always result in big computation error owing to the 2D plane's distortion and coordinate discontinuity. In this work, we perform scanpath prediction for 360{\deg} images in 3D spherical coordinate system and proposed a novel 3D scanpath Transformer named Pathformer3D. Specifically, a 3D Transformer encoder is first used to extract 3D contextual feature representation for the 360{\deg} image. Then, the contextual feature representation and historical fixation information are input into a Transformer decoder to output current time step's fixation embedding, where the self-attention module is used to imitate the visual working memory mechanism of human visual system and directly model the time dependencies among the fixations. Finally, a 3D Gaussian distribution is learned from each fixation embedding, from which the fixation position can be sampled. Evaluation on four panoramic eye-tracking datasets demonstrates that Pathformer3D outperforms the current state-of-the-art methods. Code is available at https://github.com/lsztzp/Pathformer3D .
Cross-Domain Few-Shot Semantic Segmentation via Doubly Matching Transformation
May 24, 2024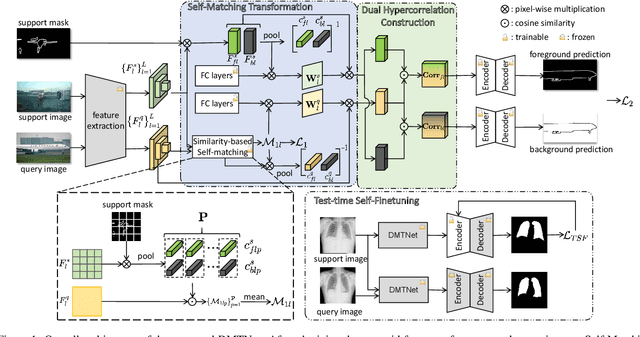


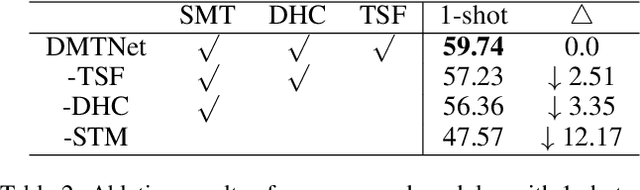
Cross-Domain Few-shot Semantic Segmentation (CD-FSS) aims to train generalized models that can segment classes from different domains with a few labeled images. Previous works have proven the effectiveness of feature transformation in addressing CD-FSS. However, they completely rely on support images for feature transformation, and repeatedly utilizing a few support images for each class may easily lead to overfitting and overlooking intra-class appearance differences. In this paper, we propose a Doubly Matching Transformation-based Network (DMTNet) to solve the above issue. Instead of completely relying on support images, we propose Self-Matching Transformation (SMT) to construct query-specific transformation matrices based on query images themselves to transform domain-specific query features into domain-agnostic ones. Calculating query-specific transformation matrices can prevent overfitting, especially for the meta-testing stage where only one or several images are used as support images to segment hundreds or thousands of images. After obtaining domain-agnostic features, we exploit a Dual Hypercorrelation Construction (DHC) module to explore the hypercorrelations between the query image with the foreground and background of the support image, based on which foreground and background prediction maps are generated and supervised, respectively, to enhance the segmentation result. In addition, we propose a Test-time Self-Finetuning (TSF) strategy to more accurately self-tune the query prediction in unseen domains. Extensive experiments on four popular datasets show that DMTNet achieves superior performance over state-of-the-art approaches. Code is available at https://github.com/ChenJiayi68/DMTNet.
MRGAN360: Multi-stage Recurrent Generative Adversarial Network for 360 Degree Image Saliency Prediction
Mar 15, 2023

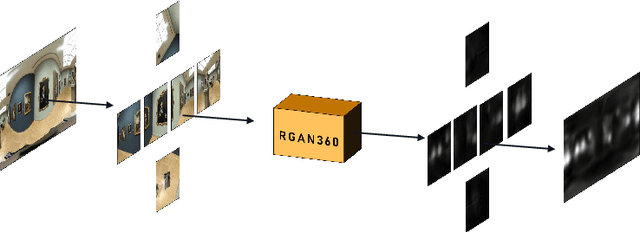

Thanks to the ability of providing an immersive and interactive experience, the uptake of 360 degree image content has been rapidly growing in consumer and industrial applications. Compared to planar 2D images, saliency prediction for 360 degree images is more challenging due to their high resolutions and spherical viewing ranges. Currently, most high-performance saliency prediction models for omnidirectional images (ODIs) rely on deeper or broader convolutional neural networks (CNNs), which benefit from CNNs' superior feature representation capabilities while suffering from their high computational costs. In this paper, inspired by the human visual cognitive process, i.e., human being's perception of a visual scene is always accomplished by multiple stages of analysis, we propose a novel multi-stage recurrent generative adversarial networks for ODIs dubbed MRGAN360, to predict the saliency maps stage by stage. At each stage, the prediction model takes as input the original image and the output of the previous stage and outputs a more accurate saliency map. We employ a recurrent neural network among adjacent prediction stages to model their correlations, and exploit a discriminator at the end of each stage to supervise the output saliency map. In addition, we share the weights among all the stages to obtain a lightweight architecture that is computationally cheap. Extensive experiments are conducted to demonstrate that our proposed model outperforms the state-of-the-art model in terms of both prediction accuracy and model size.