 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for Large Language Models
Jan 29, 2026On-policy reinforcement learning (RL) methods widely used for language model post-training, like Group Relative Policy Optimization (GRPO), often suffer from limited exploration and early saturation due to low sampling diversity. While off-policy data can help, current approaches that mix entire trajectories cause significant policy mismatch and instability. In this work, we propose the $\textbf{S}$ingle-sample Mix-p$\textbf{O}$licy $\textbf{U}$nified $\textbf{P}$aradigm (SOUP), a framework that unifies off- and on-policy learning within individual samples at the token level. It confines off-policy influence to the prefix of a generated sequence sampled from historical policies, while the continuation is generated on-policy. Through token-level importance ratios, SOUP effectively leverages off-policy information while preserving training stability. Extensive experiments demonstrate that SOUP consistently outperforms standard on-policy training and existing off-policy extensions. Our further analysis clarifies how our fine-grained, single-sample mix-policy training can improve both exploration and final performance in LLM RL.
A Unified Masked Jigsaw Puzzle Framework for Vision and Language Models
Jan 17, 2026In federated learning, Transformer, as a popular architecture, faces critical challenges in defending against gradient attacks and improving model performance in both Computer Vision (CV) and Natural Language Processing (NLP) tasks. It has been revealed that the gradient of Position Embeddings (PEs) in Transformer contains sufficient information, which can be used to reconstruct the input data. To mitigate this issue, we introduce a Masked Jigsaw Puzzle (MJP) framework. MJP starts with random token shuffling to break the token order, and then a learnable \textit{unknown (unk)} position embedding is used to mask out the PEs of the shuffled tokens. In this manner, the local spatial information which is encoded in the position embeddings is disrupted, and the models are forced to learn feature representations that are less reliant on the local spatial information. Notably, with the careful use of MJP, we can not only improve models' robustness against gradient attacks, but also boost their performance in both vision and text application scenarios, such as classification for images (\textit{e.g.,} ImageNet-1K) and sentiment analysis for text (\textit{e.g.,} Yelp and Amazon). Experimental results suggest that MJP is a unified framework for different Transformer-based models in both vision and language tasks. Code is publicly available via https://github.com/ywxsuperstar/transformerattack
DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
Jan 14, 2026Reinforcement learning (RL)-based enhancement of large language models (LLMs) often leads to reduced output diversity, undermining their utility in open-ended tasks like creative writing. Current methods lack explicit mechanisms for guiding diverse exploration and instead prioritize optimization efficiency and performance over diversity. This paper proposes an RL framework structured around a semi-structured long Chain-of-Thought (CoT), in which the generation process is decomposed into explicitly planned intermediate steps. We introduce a Diverse Planning Branching method that strategically introduces divergence at the planning phase based on diversity variation, alongside a group-aware diversity reward to encourage distinct trajectories. Experimental results on creative writing benchmarks demonstrate that our approach significantly improves output diversity without compromising generation quality, consistently outperforming existing baselines.
Weights to Code: Extracting Interpretable Algorithms from the Discrete Transformer
Jan 09, 2026Algorithm extraction aims to synthesize executable programs directly from models trained on specific algorithmic tasks, enabling de novo algorithm discovery without relying on human-written code. However, extending this paradigm to Transformer is hindered by superposition, where entangled features encoded in overlapping directions obstruct the extraction of symbolic expressions. In this work, we propose the Discrete Transformer, an architecture explicitly engineered to bridge the gap between continuous representations and discrete symbolic logic. By enforcing a strict functional disentanglement, which constrains Numerical Attention to information routing and Numerical MLP to element-wise arithmetic, and employing temperature-annealed sampling, our method effectively facilitates the extraction of human-readable programs. Empirically, the Discrete Transformer not only achieves performance comparable to RNN-based baselines but crucially extends interpretability to continuous variable domains. Moreover, our analysis of the annealing process shows that the efficient discrete search undergoes a clear phase transition from exploration to exploitation. We further demonstrate that our method enables fine-grained control over synthesized programs by imposing inductive biases. Collectively, these findings establish the Discrete Transformer as a robust framework for demonstration-free algorithm discovery, offering a rigorous pathway toward Transformer interpretability.
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone
Dec 27, 2025While autoregressive Large Vision-Language Models (VLMs) have achieved remarkable success, their sequential generation often limits their efficacy in complex visual planning and dynamic robotic control. In this work, we investigate the potential of constructing Vision-Language Models upon diffusion-based large language models (dLLMs) to overcome these limitations. We introduce Dream-VL, an open diffusion-based VLM (dVLM) that achieves state-of-the-art performance among previous dVLMs. Dream-VL is comparable to top-tier AR-based VLMs trained on open data on various benchmarks but exhibits superior potential when applied to visual planning tasks. Building upon Dream-VL, we introduce Dream-VLA, a dLLM-based Vision-Language-Action model (dVLA) developed through continuous pre-training on open robotic datasets. We demonstrate that the natively bidirectional nature of this diffusion backbone serves as a superior foundation for VLA tasks, inherently suited for action chunking and parallel generation, leading to significantly faster convergence in downstream fine-tuning. Dream-VLA achieves top-tier performance of 97.2% average success rate on LIBERO, 71.4% overall average on SimplerEnv-Bridge, and 60.5% overall average on SimplerEnv-Fractal, surpassing leading models such as $π_0$ and GR00T-N1. We also validate that dVLMs surpass AR baselines on downstream tasks across different training objectives. We release both Dream-VL and Dream-VLA to facilitate further research in the community.
Open Multimodal Retrieval-Augmented Factual Image Generation
Oct 26, 2025

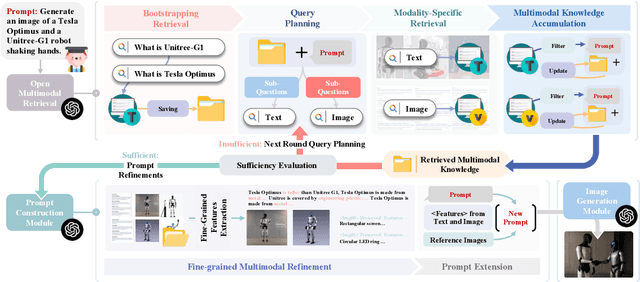

Large Multimodal Models (LMMs) have achieved remarkable progress in generating photorealistic and prompt-aligned images, but they often produce outputs that contradict verifiable knowledge, especially when prompts involve fine-grained attributes or time-sensitive events. Conventional retrieval-augmented approaches attempt to address this issue by introducing external information, yet they are fundamentally incapable of grounding generation in accurate and evolving knowledge due to their reliance on static sources and shallow evidence integration. To bridge this gap, we introduce ORIG, an agentic open multimodal retrieval-augmented framework for Factual Image Generation (FIG), a new task that requires both visual realism and factual grounding. ORIG iteratively retrieves and filters multimodal evidence from the web and incrementally integrates the refined knowledge into enriched prompts to guide generation. To support systematic evaluation, we build FIG-Eval, a benchmark spanning ten categories across perceptual, compositional, and temporal dimensions. Experiments demonstrate that ORIG substantially improves factual consistency and overall image quality over strong baselines, highlighting the potential of open multimodal retrieval for factual image generation.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Unlocking Multimodal Integration in EHRs: A Prompt Learning Framework for Language and Time Series Fusion
Feb 19, 2025Large language models (LLMs) have shown remarkable performance in vision-language tasks, but their application in the medical field remains underexplored, particularly for integrating structured time series data with unstructured clinical notes. In clinical practice, dynamic time series data such as lab test results capture critical temporal patterns, while clinical notes provide rich semantic context. Merging these modalities is challenging due to the inherent differences between continuous signals and discrete text. To bridge this gap, we introduce ProMedTS, a novel self-supervised multimodal framework that employs prompt-guided learning to unify these heterogeneous data types. Our approach leverages lightweight anomaly detection to generate anomaly captions that serve as prompts, guiding the encoding of raw time series data into informative embeddings. These embeddings are aligned with textual representations in a shared latent space, preserving fine-grained temporal nuances alongside semantic insights. Furthermore, our framework incorporates tailored self-supervised objectives to enhance both intra- and inter-modal alignment. We evaluate ProMedTS on disease diagnosis tasks using real-world datasets, and the results demonstrate that our method consistently outperforms state-of-the-art approaches.
Generative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructing
Jan 15, 2025
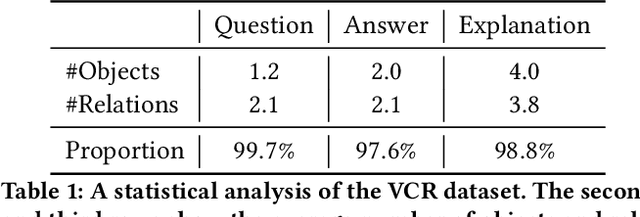

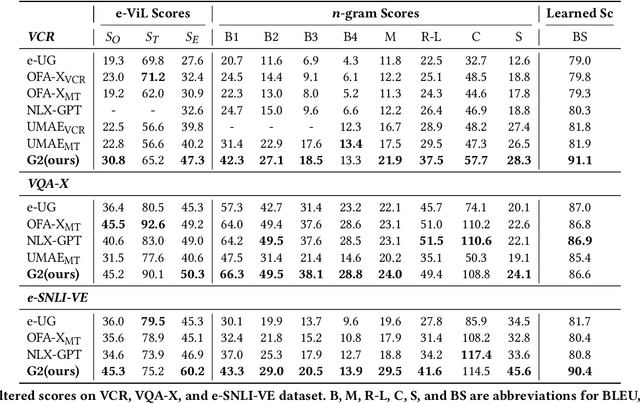
Visual Commonsense Reasoning, which is regarded as one challenging task to pursue advanced visual scene comprehension, has been used to diagnose the reasoning ability of AI systems. However, reliable reasoning requires a good grasp of the scene's details. Existing work fails to effectively exploit the real-world object relationship information present within the scene, and instead overly relies on knowledge from training memory. Based on these observations, we propose a novel scene-graph-enhanced visual commonsense reasoning generation method named \textit{\textbf{G2}}, which first utilizes the image patches and LLMs to construct a location-free scene graph, and then answer and explain based on the scene graph's information. We also propose automatic scene graph filtering and selection strategies to absorb valuable scene graph information during training. Extensive experiments are conducted on the tasks and datasets of scene graph constructing and visual commonsense answering and explaining, respectively. Experimental results and ablation analysis demonstrate the effectiveness of our proposed framework.