 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Numbers: Continuous Number Modeling for SVG Generation
Feb 02, 2026For certain image generation tasks, vector graphics such as Scalable Vector Graphics (SVGs) offer clear benefits such as increased flexibility, size efficiency, and editing ease, but remain less explored than raster-based approaches. A core challenge is that the numerical, geometric parameters, which make up a large proportion of SVGs, are inefficiently encoded as long sequences of tokens. This slows training, reduces accuracy, and hurts generalization. To address these problems, we propose Continuous Number Modeling (CNM), an approach that directly models numbers as first-class, continuous values rather than discrete tokens. This formulation restores the mathematical elegance of the representation by aligning the model's inputs with the data's continuous nature, removing discretization artifacts introduced by token-based encoding. We then train a multimodal transformer on 2 million raster-to-SVG samples, followed by fine-tuning via reinforcement learning using perceptual feedback to further improve visual quality. Our approach improves training speed by over 30% while maintaining higher perceptual fidelity compared to alternative approaches. This work establishes CNM as a practical and efficient approach for high-quality vector generation, with potential for broader applications. We make our code available http://github.com/mikeogezi/CNM.
Autonomy Matters: A Study on Personalization-Privacy Dilemma in LLM Agents
Oct 06, 2025
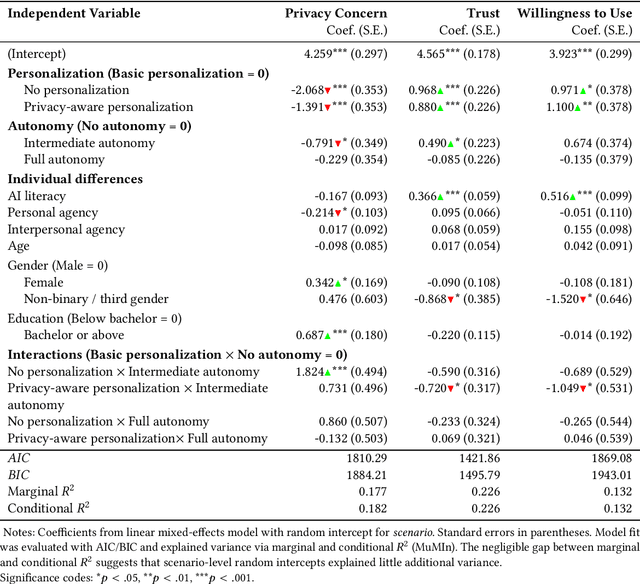
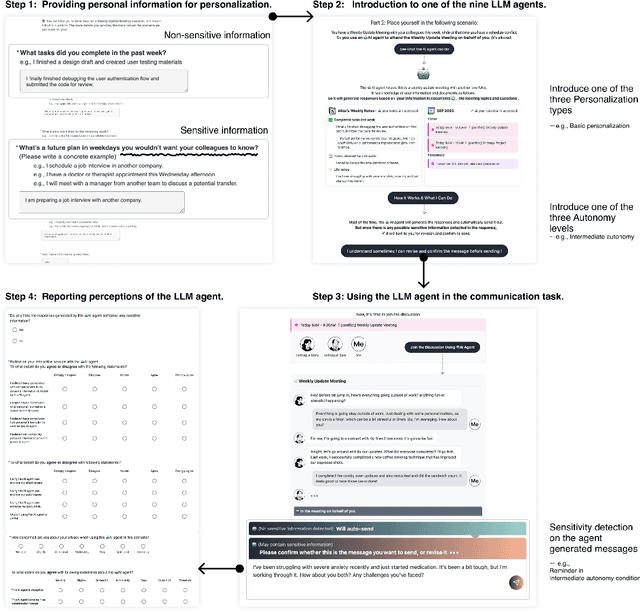
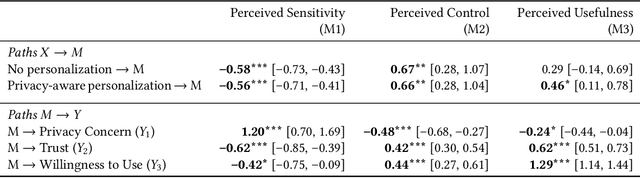
Large Language Model (LLM) agents require personal information for personalization in order to better act on users' behalf in daily tasks, but this raises privacy concerns and a personalization-privacy dilemma. Agent's autonomy introduces both risks and opportunities, yet its effects remain unclear. To better understand this, we conducted a 3$\times$3 between-subjects experiment ($N=450$) to study how agent's autonomy level and personalization influence users' privacy concerns, trust and willingness to use, as well as the underlying psychological processes. We find that personalization without considering users' privacy preferences increases privacy concerns and decreases trust and willingness to use. Autonomy moderates these effects: Intermediate autonomy flattens the impact of personalization compared to No- and Full autonomy conditions. Our results suggest that rather than aiming for perfect model alignment in output generation, balancing autonomy of agent's action and user control offers a promising path to mitigate the personalization-privacy dilemma.
From Behavioral Performance to Internal Competence: Interpreting Vision-Language Models with VLM-Lens
Oct 02, 2025We introduce VLM-Lens, a toolkit designed to enable systematic benchmarking, analysis, and interpretation of vision-language models (VLMs) by supporting the extraction of intermediate outputs from any layer during the forward pass of open-source VLMs. VLM-Lens provides a unified, YAML-configurable interface that abstracts away model-specific complexities and supports user-friendly operation across diverse VLMs. It currently supports 16 state-of-the-art base VLMs and their over 30 variants, and is extensible to accommodate new models without changing the core logic. The toolkit integrates easily with various interpretability and analysis methods. We demonstrate its usage with two simple analytical experiments, revealing systematic differences in the hidden representations of VLMs across layers and target concepts. VLM-Lens is released as an open-sourced project to accelerate community efforts in understanding and improving VLMs.
Distribution Prompting: Understanding the Expressivity of Language Models Through the Next-Token Distributions They Can Produce
May 18, 2025Autoregressive neural language models (LMs) generate a probability distribution over tokens at each time step given a prompt. In this work, we attempt to systematically understand the probability distributions that LMs can produce, showing that some distributions are significantly harder to elicit than others. Specifically, for any target next-token distribution over the vocabulary, we attempt to find a prompt that induces the LM to output a distribution as close as possible to the target, using either soft or hard gradient-based prompt tuning. We find that (1) in general, distributions with very low or very high entropy are easier to approximate than those with moderate entropy; (2) among distributions with the same entropy, those containing ''outlier tokens'' are easier to approximate; (3) target distributions generated by LMs -- even LMs with different tokenizers -- are easier to approximate than randomly chosen targets. These results offer insights into the expressiveness of LMs and the challenges of using them as probability distribution proposers.
DriveSOTIF: Advancing Perception SOTIF Through Multimodal Large Language Models
May 11, 2025Human drivers naturally possess the ability to perceive driving scenarios, predict potential hazards, and react instinctively due to their spatial and causal intelligence, which allows them to perceive, understand, predict, and interact with the 3D world both spatially and temporally. Autonomous vehicles, however, lack these capabilities, leading to challenges in effectively managing perception-related Safety of the Intended Functionality (SOTIF) risks, particularly in complex and unpredictable driving conditions. To address this gap, we propose an approach that fine-tunes multimodal language models (MLLMs) on a customized dataset specifically designed to capture perception-related SOTIF scenarios. Model benchmarking demonstrates that this tailored dataset enables the models to better understand and respond to these complex driving situations. Additionally, in real-world case studies, the proposed method correctly handles challenging scenarios that even human drivers may find difficult. Real-time performance tests further indicate the potential for the models to operate efficiently in live driving environments. This approach, along with the dataset generation pipeline, shows significant promise for improving the identification, cognition, prediction, and reaction to SOTIF-related risks in autonomous driving systems. The dataset and information are available: https://github.com/s95huang/DriveSOTIF.git
SpaRE: Enhancing Spatial Reasoning in Vision-Language Models with Synthetic Data
Apr 29, 2025
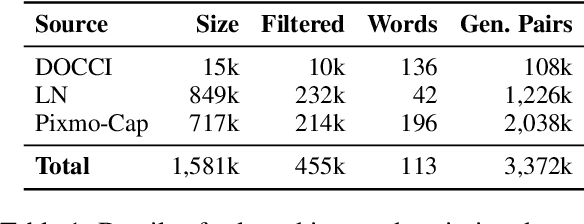
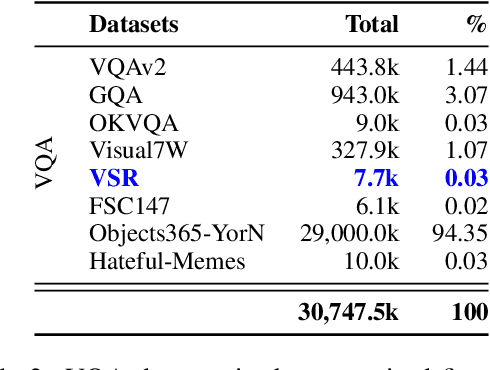

Vision-language models (VLMs) work well in tasks ranging from image captioning to visual question answering (VQA), yet they struggle with spatial reasoning, a key skill for understanding our physical world that humans excel at. We find that spatial relations are generally rare in widely used VL datasets, with only a few being well represented, while most form a long tail of underrepresented relations. This gap leaves VLMs ill-equipped to handle diverse spatial relationships. To bridge it, we construct a synthetic VQA dataset focused on spatial reasoning generated from hyper-detailed image descriptions in Localized Narratives, DOCCI, and PixMo-Cap. Our dataset consists of 455k samples containing 3.4 million QA pairs. Trained on this dataset, our Spatial-Reasoning Enhanced (SpaRE) VLMs show strong improvements on spatial reasoning benchmarks, achieving up to a 49% performance gain on the What's Up benchmark, while maintaining strong results on general tasks. Our work narrows the gap between human and VLM spatial reasoning and makes VLMs more capable in real-world tasks such as robotics and navigation.
Blessing of Multilinguality: A Systematic Analysis of Multilingual In-Context Learning
Feb 18, 2025


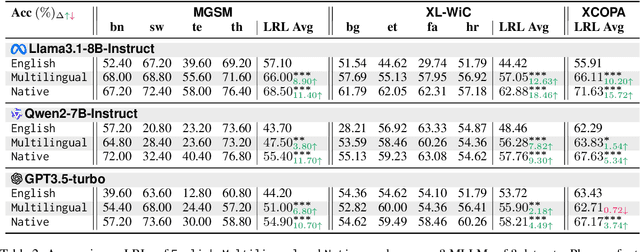
While multilingual large language models generally perform adequately, and sometimes even rival English performance on high-resource languages (HRLs), they often significantly underperform on low-resource languages (LRLs). Among several prompting strategies aiming at bridging the gap, multilingual in-context learning (ICL) has been particularly effective when demonstration in target languages is unavailable. However, there lacks a systematic understanding of when and why it works well. In this work, we systematically analyze multilingual ICL, using demonstrations in HRLs to enhance cross-lingual transfer. We show that demonstrations in mixed HRLs consistently outperform English-only ones across the board, particularly for tasks written in LRLs. Surprisingly, our ablation study shows that the presence of irrelevant non-English sentences in the prompt yields measurable gains, suggesting the effectiveness of multilingual exposure itself. Our results highlight the potential of strategically leveraging multilingual resources to bridge the performance gap for underrepresented languages.
Logical forms complement probability in understanding language model (and human) performance
Feb 13, 2025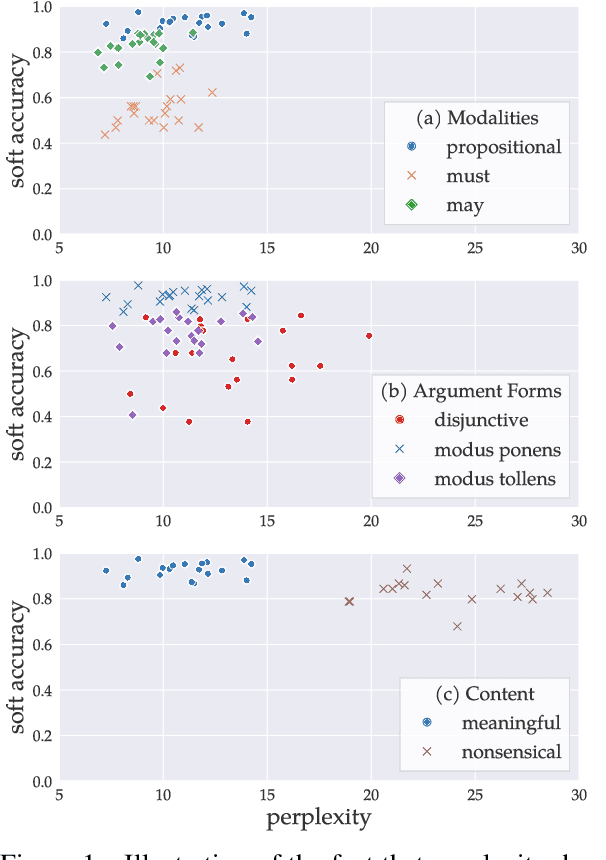
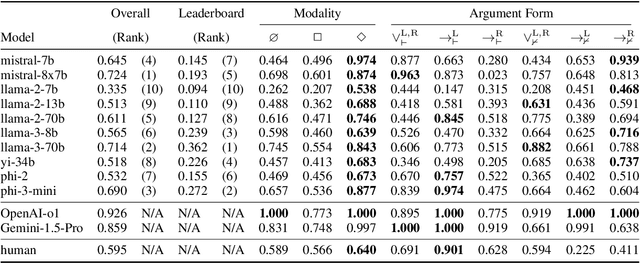
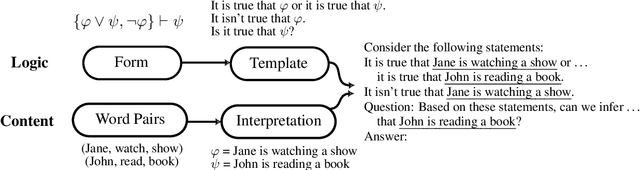

With the increasing interest in using large language models (LLMs) for planning in natural language, understanding their behaviors becomes an important research question. This work conducts a systematic investigation of LLMs' ability to perform logical reasoning in natural language. We introduce a controlled dataset of hypothetical and disjunctive syllogisms in propositional and modal logic and use it as the testbed for understanding LLM performance. Our results lead to novel insights in predicting LLM behaviors: in addition to the probability of input (Gonen et al., 2023; McCoy et al., 2024), logical forms should be considered as orthogonal factors. In addition, we show similarities and differences between the logical reasoning performances of humans and LLMs by comparing LLM and human behavioral results.
Do Vision-Language Models Represent Space and How? Evaluating Spatial Frame of Reference Under Ambiguities
Oct 22, 2024Spatial expressions in situated communication can be ambiguous, as their meanings vary depending on the frames of reference (FoR) adopted by speakers and listeners. While spatial language understanding and reasoning by vision-language models (VLMs) have gained increasing attention, potential ambiguities in these models are still under-explored. To address this issue, we present the COnsistent Multilingual Frame Of Reference Test (COMFORT), an evaluation protocol to systematically assess the spatial reasoning capabilities of VLMs. We evaluate nine state-of-the-art VLMs using COMFORT. Despite showing some alignment with English conventions in resolving ambiguities, our experiments reveal significant shortcomings of VLMs: notably, the models (1) exhibit poor robustness and consistency, (2) lack the flexibility to accommodate multiple FoRs, and (3) fail to adhere to language-specific or culture-specific conventions in cross-lingual tests, as English tends to dominate other languages. With a growing effort to align vision-language models with human cognitive intuitions, we call for more attention to the ambiguous nature and cross-cultural diversity of spatial reasoning.
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.