 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical forms complement probability in understanding language model (and human) performance
Paper and Code
Feb 13, 2025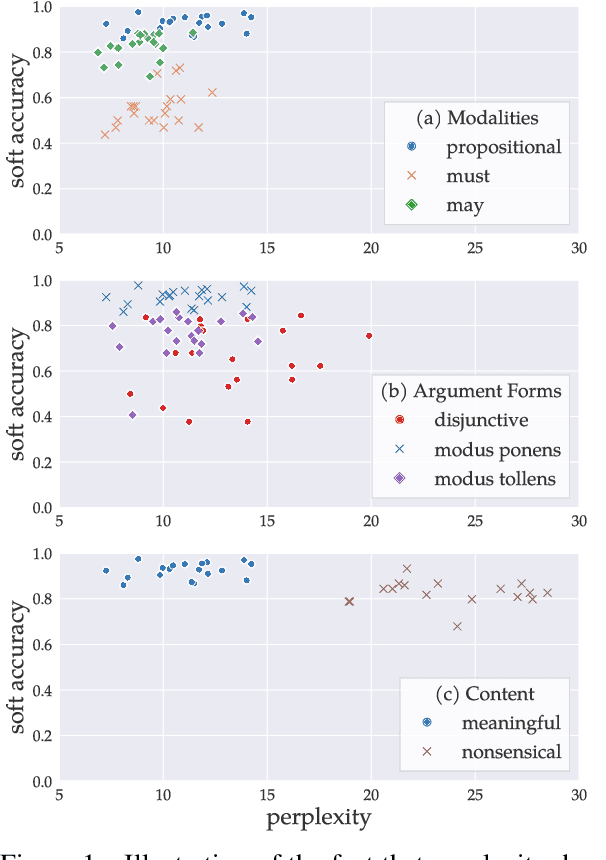
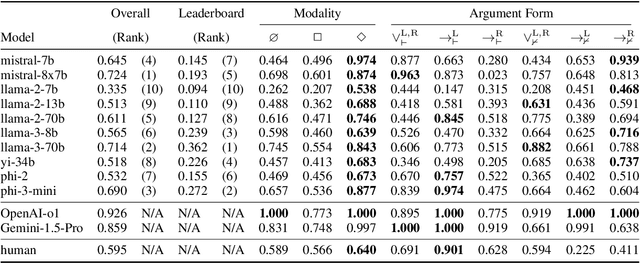
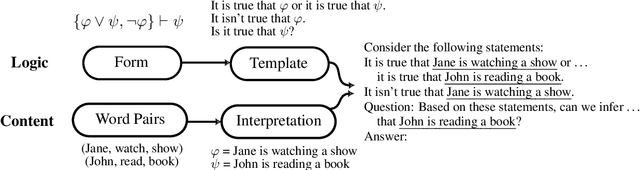

With the increasing interest in using large language models (LLMs) for planning in natural language, understanding their behaviors becomes an important research question. This work conducts a systematic investigation of LLMs' ability to perform logical reasoning in natural language. We introduce a controlled dataset of hypothetical and disjunctive syllogisms in propositional and modal logic and use it as the testbed for understanding LLM performance. Our results lead to novel insights in predicting LLM behaviors: in addition to the probability of input (Gonen et al., 2023; McCoy et al., 2024), logical forms should be considered as orthogonal factors. In addition, we show similarities and differences between the logical reasoning performances of humans and LLMs by comparing LLM and human behavioral results.