 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich course? Discourse! Teaching Discourse and Generation in the Era of LLMs
Feb 02, 2026The field of NLP has undergone vast, continuous transformations over the past few years, sparking debates going beyond discipline boundaries. This begs important questions in education: how do we design courses that bridge sub-disciplines in this shifting landscape? This paper explores this question from the angle of discourse processing, an area with rich linguistic insights and computational models for the intentional, attentional, and coherence structure of language. Discourse is highly relevant for open-ended or long-form text generation, yet this connection is under-explored in existing undergraduate curricula. We present a new course, "Computational Discourse and Natural Language Generation". The course is collaboratively designed by a team with complementary expertise and was offered for the first time in Fall 2025 as an upper-level undergraduate course, cross-listed between Linguistics and Computer Science. Our philosophy is to deeply integrate the theoretical and empirical aspects, and create an exploratory mindset inside the classroom and in the assignments. This paper describes the course in detail and concludes with takeaways from an independent survey as well as our vision for future directions.
Bears, all bears, and some bears. Language Constraints on Language Models' Inductive Inferences
Jan 14, 2026Language places subtle constraints on how we make inductive inferences. Developmental evidence by Gelman et al. (2002) has shown children (4 years and older) to differentiate among generic statements ("Bears are daxable"), universally quantified NPs ("all bears are daxable") and indefinite plural NPs ("some bears are daxable") in extending novel properties to a specific member (all > generics > some), suggesting that they represent these types of propositions differently. We test if these subtle differences arise in general purpose statistical learners like Vision Language Models, by replicating the original experiment. On tasking them through a series of precondition tests (robust identification of categories in images and sensitivities to all and some), followed by the original experiment, we find behavioral alignment between models and humans. Post-hoc analyses on their representations revealed that these differences are organized based on inductive constraints and not surface-form differences.
Hey, wait a minute: on at-issue sensitivity in Language Models
Oct 14, 2025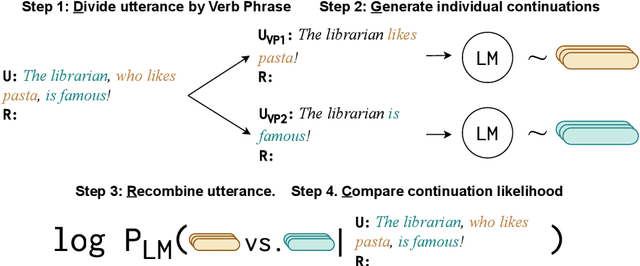
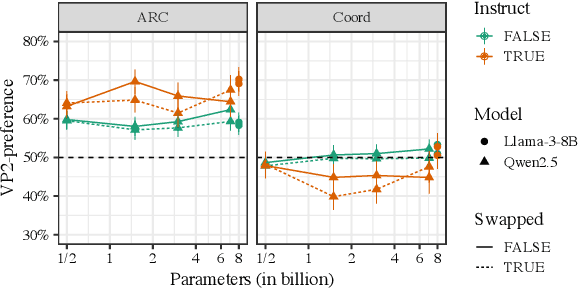
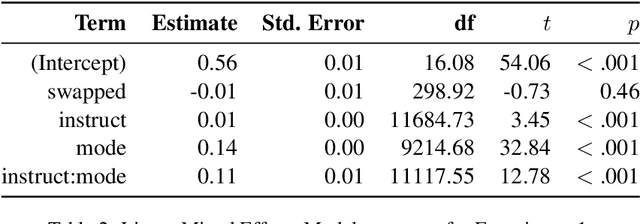
Evaluating the naturalness of dialogue in language models (LMs) is not trivial: notions of 'naturalness' vary, and scalable quantitative metrics remain limited. This study leverages the linguistic notion of 'at-issueness' to assess dialogue naturalness and introduces a new method: Divide, Generate, Recombine, and Compare (DGRC). DGRC (i) divides a dialogue as a prompt, (ii) generates continuations for subparts using LMs, (iii) recombines the dialogue and continuations, and (iv) compares the likelihoods of the recombined sequences. This approach mitigates bias in linguistic analyses of LMs and enables systematic testing of discourse-sensitive behavior. Applying DGRC, we find that LMs prefer to continue dialogue on at-issue content, with this effect enhanced in instruct-tuned models. They also reduce their at-issue preference when relevant cues (e.g., "Hey, wait a minute") are present. Although instruct-tuning does not further amplify this modulation, the pattern reflects a hallmark of successful dialogue dynamics.
WUGNECTIVES: Novel Entity Inferences of Language Models from Discourse Connectives
Oct 10, 2025The role of world knowledge has been particularly crucial to predict the discourse connective that marks the discourse relation between two arguments, with language models (LMs) being generally successful at this task. We flip this premise in our work, and instead study the inverse problem of understanding whether discourse connectives can inform LMs about the world. To this end, we present WUGNECTIVES, a dataset of 8,880 stimuli that evaluates LMs' inferences about novel entities in contexts where connectives link the entities to particular attributes. On investigating 17 different LMs at various scales, and training regimens, we found that tuning an LM to show reasoning behavior yields noteworthy improvements on most connectives. At the same time, there was a large variation in LMs' overall performance across connective type, with all models systematically struggling on connectives that express a concessive meaning. Our findings pave the way for more nuanced investigations into the functional role of language cues as captured by LMs. We release WUGNECTIVES at https://github.com/sheffwb/wugnectives.
Vision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Jul 17, 2025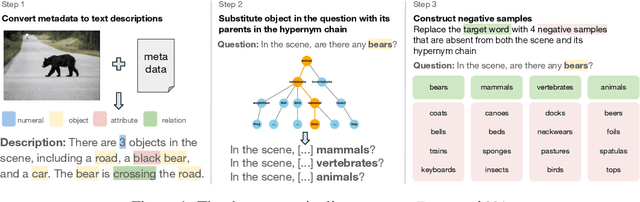
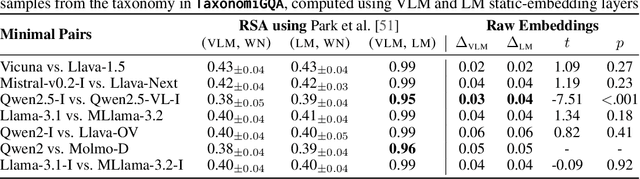
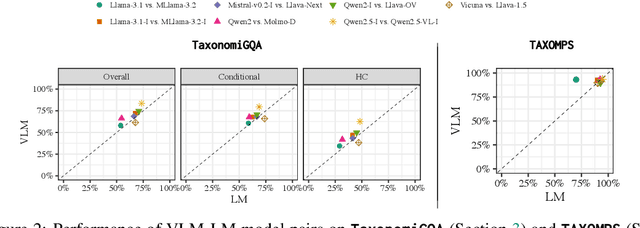
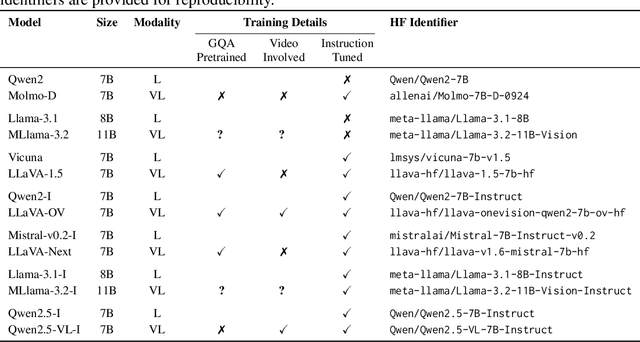
Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
semantic-features: A User-Friendly Tool for Studying Contextual Word Embeddings in Interpretable Semantic Spaces
Jun 06, 2025


We introduce semantic-features, an extensible, easy-to-use library based on Chronis et al. (2023) for studying contextualized word embeddings of LMs by projecting them into interpretable spaces. We apply this tool in an experiment where we measure the contextual effect of the choice of dative construction (prepositional or double object) on the semantic interpretation of utterances (Bresnan, 2007). Specifically, we test whether "London" in "I sent London the letter." is more likely to be interpreted as an animate referent (e.g., as the name of a person) than in "I sent the letter to London." To this end, we devise a dataset of 450 sentence pairs, one in each dative construction, with recipients being ambiguous with respect to person-hood vs. place-hood. By applying semantic-features, we show that the contextualized word embeddings of three masked language models show the expected sensitivities. This leaves us optimistic about the usefulness of our tool.
Is It JUST Semantics? A Case Study of Discourse Particle Understanding in LLMs
Jun 05, 2025Discourse particles are crucial elements that subtly shape the meaning of text. These words, often polyfunctional, give rise to nuanced and often quite disparate semantic/discourse effects, as exemplified by the diverse uses of the particle "just" (e.g., exclusive, temporal, emphatic). This work investigates the capacity of LLMs to distinguish the fine-grained senses of English "just", a well-studied example in formal semantics, using data meticulously created and labeled by expert linguists. Our findings reveal that while LLMs exhibit some ability to differentiate between broader categories, they struggle to fully capture more subtle nuances, highlighting a gap in their understanding of discourse particles.
On Language Models' Sensitivity to Suspicious Coincidences
Apr 13, 2025Humans are sensitive to suspicious coincidences when generalizing inductively over data, as they make assumptions as to how the data was sampled. This results in smaller, more specific hypotheses being favored over more general ones. For instance, when provided the set {Austin, Dallas, Houston}, one is more likely to think that this is sampled from "Texas Cities" over "US Cities" even though both are compatible. Suspicious coincidence is strongly connected to pragmatic reasoning, and can serve as a testbed to analyze systems on their sensitivity towards the communicative goals of the task (i.e., figuring out the true category underlying the data). In this paper, we analyze whether suspicious coincidence effects are reflected in language models' (LMs) behavior. We do so in the context of two domains: 1) the number game, where humans made judgments of whether a number (e.g., 4) fits a list of given numbers (e.g., 16, 32, 2); and 2) by extending the number game setup to prominent cities. For both domains, the data is compatible with multiple hypotheses and we study which hypothesis is most consistent with the models' behavior. On analyzing five models, we do not find strong evidence for suspicious coincidences in LMs' zero-shot behavior. However, when provided access to the hypotheses space via chain-of-thought or explicit prompting, LMs start to show an effect resembling suspicious coincidences, sometimes even showing effects consistent with humans. Our study suggests that inductive reasoning behavior in LMs can be enhanced with explicit access to the hypothesis landscape.
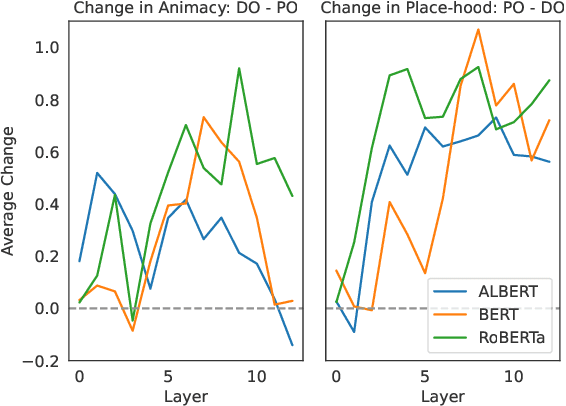
Both Direct and Indirect Evidence Contribute to Dative Alternation Preferences in Language Models
Mar 26, 2025



Language models (LMs) tend to show human-like preferences on a number of syntactic phenomena, but the extent to which these are attributable to direct exposure to the phenomena or more general properties of language is unclear. We explore this with the English dative alternation (DO: "gave Y the X" vs. PO: "gave the X to Y"), using a controlled rearing paradigm wherein we iteratively train small LMs on systematically manipulated input. We focus on properties that affect the choice of alternant: length and animacy. Both properties are directly present in datives but also reflect more global tendencies for shorter elements to precede longer ones and animates to precede inanimates. First, by manipulating and ablating datives for these biases in the input, we show that direct evidence of length and animacy matters, but easy-first preferences persist even without such evidence. Then, using LMs trained on systematically perturbed datasets to manipulate global length effects (re-linearizing sentences globally while preserving dependency structure), we find that dative preferences can emerge from indirect evidence. We conclude that LMs' emergent syntactic preferences come from a mix of direct and indirect sources.
Characterizing the Role of Similarity in the Property Inferences of Language Models
Oct 29, 2024



Property inheritance -- a phenomenon where novel properties are projected from higher level categories (e.g., birds) to lower level ones (e.g., sparrows) -- provides a unique window into how humans organize and deploy conceptual knowledge. It is debated whether this ability arises due to explicitly stored taxonomic knowledge vs. simple computations of similarity between mental representations. How are these mechanistic hypotheses manifested in contemporary language models? In this work, we investigate how LMs perform property inheritance with behavioral and causal representational analysis experiments. We find that taxonomy and categorical similarities are not mutually exclusive in LMs' property inheritance behavior. That is, LMs are more likely to project novel properties from one category to the other when they are taxonomically related and at the same time, highly similar. Our findings provide insight into the conceptual structure of language models and may suggest new psycholinguistic experiments for human subjects.