 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich course? Discourse! Teaching Discourse and Generation in the Era of LLMs
Feb 02, 2026The field of NLP has undergone vast, continuous transformations over the past few years, sparking debates going beyond discipline boundaries. This begs important questions in education: how do we design courses that bridge sub-disciplines in this shifting landscape? This paper explores this question from the angle of discourse processing, an area with rich linguistic insights and computational models for the intentional, attentional, and coherence structure of language. Discourse is highly relevant for open-ended or long-form text generation, yet this connection is under-explored in existing undergraduate curricula. We present a new course, "Computational Discourse and Natural Language Generation". The course is collaboratively designed by a team with complementary expertise and was offered for the first time in Fall 2025 as an upper-level undergraduate course, cross-listed between Linguistics and Computer Science. Our philosophy is to deeply integrate the theoretical and empirical aspects, and create an exploratory mindset inside the classroom and in the assignments. This paper describes the course in detail and concludes with takeaways from an independent survey as well as our vision for future directions.
WUGNECTIVES: Novel Entity Inferences of Language Models from Discourse Connectives
Oct 10, 2025The role of world knowledge has been particularly crucial to predict the discourse connective that marks the discourse relation between two arguments, with language models (LMs) being generally successful at this task. We flip this premise in our work, and instead study the inverse problem of understanding whether discourse connectives can inform LMs about the world. To this end, we present WUGNECTIVES, a dataset of 8,880 stimuli that evaluates LMs' inferences about novel entities in contexts where connectives link the entities to particular attributes. On investigating 17 different LMs at various scales, and training regimens, we found that tuning an LM to show reasoning behavior yields noteworthy improvements on most connectives. At the same time, there was a large variation in LMs' overall performance across connective type, with all models systematically struggling on connectives that express a concessive meaning. Our findings pave the way for more nuanced investigations into the functional role of language cues as captured by LMs. We release WUGNECTIVES at https://github.com/sheffwb/wugnectives.
Is It JUST Semantics? A Case Study of Discourse Particle Understanding in LLMs
Jun 05, 2025Discourse particles are crucial elements that subtly shape the meaning of text. These words, often polyfunctional, give rise to nuanced and often quite disparate semantic/discourse effects, as exemplified by the diverse uses of the particle "just" (e.g., exclusive, temporal, emphatic). This work investigates the capacity of LLMs to distinguish the fine-grained senses of English "just", a well-studied example in formal semantics, using data meticulously created and labeled by expert linguists. Our findings reveal that while LLMs exhibit some ability to differentiate between broader categories, they struggle to fully capture more subtle nuances, highlighting a gap in their understanding of discourse particles.
Elaborative Simplification as Implicit Questions Under Discussion
May 17, 2023Automated text simplification, a technique useful for making text more accessible to people such as children and emergent bilinguals, is often thought of as a monolingual translation task from complex sentences to simplified sentences using encoder-decoder models. This view fails to account for elaborative simplification, where new information is added into the simplified text. This paper proposes to view elaborative simplification through the lens of the Question Under Discussion (QUD) framework, providing a robust way to investigate what writers elaborate upon, how they elaborate, and how elaborations fit into the discourse context by viewing elaborations as explicit answers to implicit questions. We introduce ElabQUD, consisting of 1.3K elaborations accompanied with implicit QUDs, to study these phenomena. We show that explicitly modeling QUD (via question generation) not only provides essential understanding of elaborative simplification and how the elaborations connect with the rest of the discourse, but also substantially improves the quality of elaboration generation.
Evaluating Factuality in Text Simplification
Apr 15, 2022


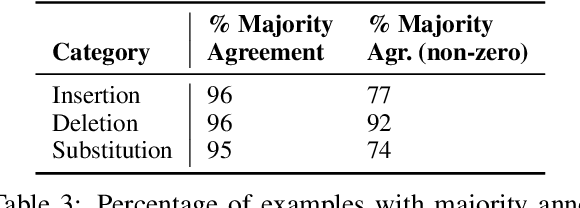
Automated simplification models aim to make input texts more readable. Such methods have the potential to make complex information accessible to a wider audience, e.g., providing access to recent medical literature which might otherwise be impenetrable for a lay reader. However, such models risk introducing errors into automatically simplified texts, for instance by inserting statements unsupported by the corresponding original text, or by omitting key information. Providing more readable but inaccurate versions of texts may in many cases be worse than providing no such access at all. The problem of factual accuracy (and the lack thereof) has received heightened attention in the context of summarization models, but the factuality of automatically simplified texts has not been investigated. We introduce a taxonomy of errors that we use to analyze both references drawn from standard simplification datasets and state-of-the-art model outputs. We find that errors often appear in both that are not captured by existing evaluation metrics, motivating a need for research into ensuring the factual accuracy of automated simplification models.