 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation or Recitation? Calibrating Evaluation Scores for Machine Translation of Extremely Low-Resource Languages
Mar 26, 2026The landscape of extremely low-resource machine translation (MT) is characterized by perplexing variability in reported performance, often making results across different language pairs difficult to contextualize. For researchers focused on specific language groups -- such as ancient languages -- it is nearly impossible to determine if breakthroughs reported in other contexts (e.g., native African or American languages) result from superior methodologies or are merely artifacts of benchmark collection. To address this problem, we introduce the FRED Difficulty Metrics, which include the Fertility Ratio (F), Retrieval Proxy (R), Pre-training Exposure (E), and Corpus Diversity (D) and serve as dataset-intrinsic metrics to contextualize reported scores. These metrics reveal that a significant portion of result variability is explained by train-test overlap and pre-training exposure rather than model capability. Additionally, we identify that some languages -- particularly extinct and non-Latin indigenous languages -- suffer from poor tokenization coverage (high token fertility), highlighting a fundamental limitation of transferring models from high-resource languages that lack a shared vocabulary. By providing these indices alongside performance scores, we enable more transparent evaluation of cross-lingual transfer and provide a more reliable foundation for the XLR MT community.
GUARD: Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation
Aug 28, 2025

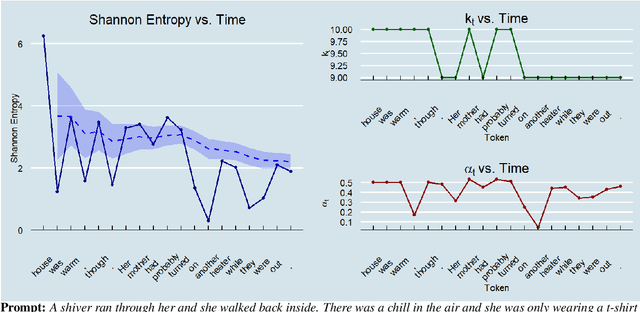

Open-ended text generation faces a critical challenge: balancing coherence with diversity in LLM outputs. While contrastive search-based decoding strategies have emerged to address this trade-off, their practical utility is often limited by hyperparameter dependence and high computational costs. We introduce GUARD, a self-adaptive decoding method that effectively balances these competing objectives through a novel "Glocal" uncertainty-driven framework. GUARD combines global entropy estimates with local entropy deviations to integrate both long-term and short-term uncertainty signals. We demonstrate that our proposed global entropy formulation effectively mitigates abrupt variations in uncertainty, such as sudden overconfidence or high entropy spikes, and provides theoretical guarantees of unbiasedness and consistency. To reduce computational overhead, we incorporate a simple yet effective token-count-based penalty into GUARD. Experimental results demonstrate that GUARD achieves a good balance between text diversity and coherence, while exhibiting substantial improvements in generation speed. In a more nuanced comparison study across different dimensions of text quality, both human and LLM evaluators validated its remarkable performance. Our code is available at https://github.com/YecanLee/GUARD.
LogogramNLP: Comparing Visual and Textual Representations of Ancient Logographic Writing Systems for NLP
Aug 08, 2024



Standard natural language processing (NLP) pipelines operate on symbolic representations of language, which typically consist of sequences of discrete tokens. However, creating an analogous representation for ancient logographic writing systems is an extremely labor intensive process that requires expert knowledge. At present, a large portion of logographic data persists in a purely visual form due to the absence of transcription -- this issue poses a bottleneck for researchers seeking to apply NLP toolkits to study ancient logographic languages: most of the relevant data are images of writing. This paper investigates whether direct processing of visual representations of language offers a potential solution. We introduce LogogramNLP, the first benchmark enabling NLP analysis of ancient logographic languages, featuring both transcribed and visual datasets for four writing systems along with annotations for tasks like classification, translation, and parsing. Our experiments compare systems that employ recent visual and text encoding strategies as backbones. The results demonstrate that visual representations outperform textual representations for some investigated tasks, suggesting that visual processing pipelines may unlock a large amount of cultural heritage data of logographic languages for NLP-based analyses.
Pixel Sentence Representation Learning
Feb 13, 2024



Pretrained language models are long known to be subpar in capturing sentence and document-level semantics. Though heavily investigated, transferring perturbation-based methods from unsupervised visual representation learning to NLP remains an unsolved problem. This is largely due to the discreteness of subword units brought by tokenization of language models, limiting small perturbations of inputs to form semantics-preserved positive pairs. In this work, we conceptualize the learning of sentence-level textual semantics as a visual representation learning process. Drawing from cognitive and linguistic sciences, we introduce an unsupervised visual sentence representation learning framework, employing visually-grounded text perturbation methods like typos and word order shuffling, resonating with human cognitive patterns, and enabling perturbation to texts to be perceived as continuous. Our approach is further bolstered by large-scale unsupervised topical alignment training and natural language inference supervision, achieving comparable performance in semantic textual similarity (STS) to existing state-of-the-art NLP methods. Additionally, we unveil our method's inherent zero-shot cross-lingual transferability and a unique leapfrogging pattern across languages during iterative training. To our knowledge, this is the first representation learning method devoid of traditional language models for understanding sentence and document semantics, marking a stride closer to human-like textual comprehension. Our code is available at https://github.com/gowitheflow-1998/Pixel-Linguist
VizSeq: A Visual Analysis Toolkit for Text Generation Tasks
Sep 12, 2019

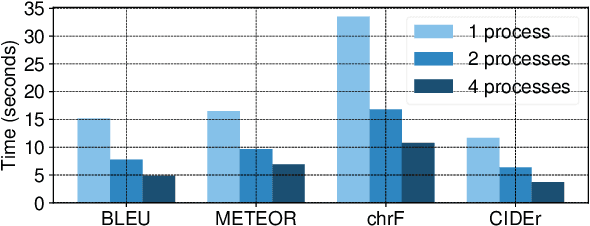

Automatic evaluation of text generation tasks (e.g. machine translation, text summarization, image captioning and video description) usually relies heavily on task-specific metrics, such as BLEU and ROUGE. They, however, are abstract numbers and are not perfectly aligned with human assessment. This suggests inspecting detailed examples as a complement to identify system error patterns. In this paper, we present VizSeq, a visual analysis toolkit for instance-level and corpus-level system evaluation on a wide variety of text generation tasks. It supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface. It can be used locally or deployed onto public servers for centralized data hosting and benchmarking. It covers most common n-gram based metrics accelerated with multiprocessing, and also provides latest embedding-based metrics such as BERTScore.
Predictive Ensemble Learning with Application to Scene Text Detection
May 16, 2019

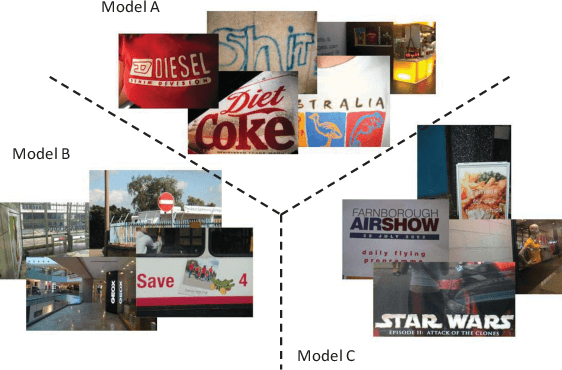
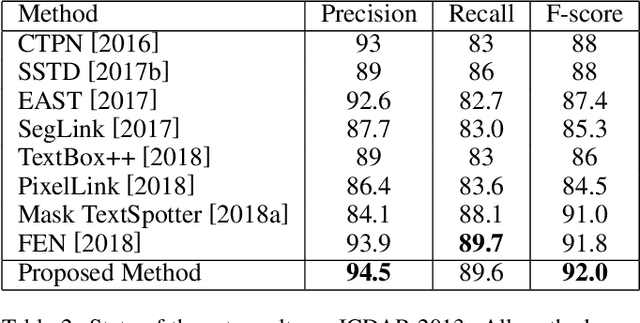
Deep learning based approaches have achieved significant progresses in different tasks like classification, detection, segmentation, and so on. Ensemble learning is widely known to further improve performance by combining multiple complementary models. It is easy to apply ensemble learning for classification tasks, for example, based on averaging, voting, or other methods. However, for other tasks (like object detection) where the outputs are varying in quantity and unable to be simply compared, the ensemble of multiple models become difficult. In this paper, we propose a new method called Predictive Ensemble Learning (PEL), based on powerful predictive ability of deep neural networks, to directly predict the best performing model among a pool of base models for each test example, thus transforming ensemble learning to a traditional classification task. Taking scene text detection as the application, where no suitable ensemble learning strategy exists, PEL can significantly improve the performance, compared to either individual state-of-the-art models, or the fusion of multiple models by non-maximum suppression. Experimental results show the possibility and potential of PEL in predicting different models' performance based only on a query example, which can be extended for ensemble learning in many other complex tasks.
Multi-Scale Dense Networks for Resource Efficient Image Classification
Jun 07, 2018
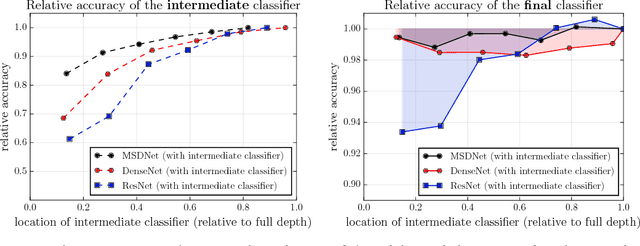

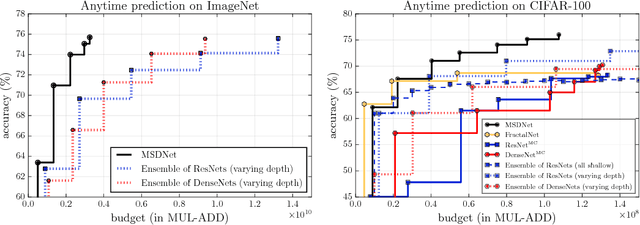
In this paper we investigate image classification with computational resource limits at test time. Two such settings are: 1. anytime classification, where the network's prediction for a test example is progressively updated, facilitating the output of a prediction at any time; and 2. budgeted batch classification, where a fixed amount of computation is available to classify a set of examples that can be spent unevenly across "easier" and "harder" inputs. In contrast to most prior work, such as the popular Viola and Jones algorithm, our approach is based on convolutional neural networks. We train multiple classifiers with varying resource demands, which we adaptively apply during test time. To maximally re-use computation between the classifiers, we incorporate them as early-exits into a single deep convolutional neural network and inter-connect them with dense connectivity. To facilitate high quality classification early on, we use a two-dimensional multi-scale network architecture that maintains coarse and fine level features all-throughout the network. Experiments on three image-classification tasks demonstrate that our framework substantially improves the existing state-of-the-art in both settings.
Memory-Efficient Implementation of DenseNets
Jul 21, 2017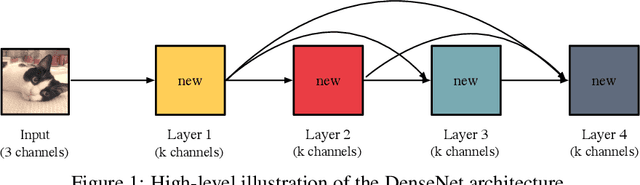



The DenseNet architecture is highly computationally efficient as a result of feature reuse. However, a naive DenseNet implementation can require a significant amount of GPU memory: If not properly managed, pre-activation batch normalization and contiguous convolution operations can produce feature maps that grow quadratically with network depth. In this technical report, we introduce strategies to reduce the memory consumption of DenseNets during training. By strategically using shared memory allocations, we reduce the memory cost for storing feature maps from quadratic to linear. Without the GPU memory bottleneck, it is now possible to train extremely deep DenseNets. Networks with 14M parameters can be trained on a single GPU, up from 4M. A 264-layer DenseNet (73M parameters), which previously would have been infeasible to train, can now be trained on a single workstation with 8 NVIDIA Tesla M40 GPUs. On the ImageNet ILSVRC classification dataset, this large DenseNet obtains a state-of-the-art single-crop top-1 error of 20.26%.
Cached Long Short-Term Memory Neural Networks for Document-Level Sentiment Classification
Oct 17, 2016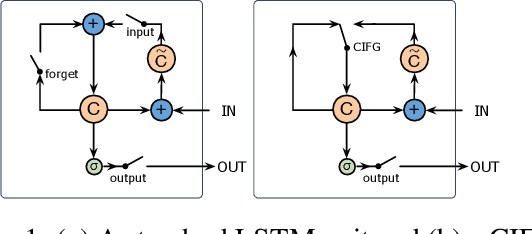

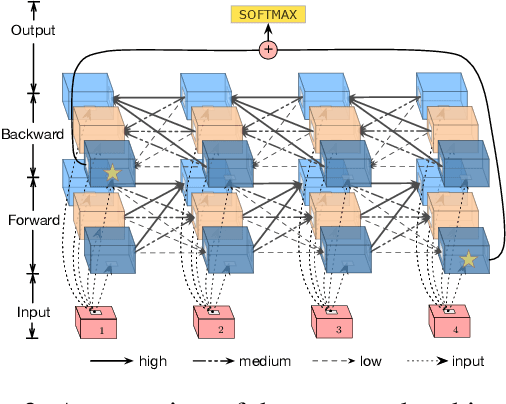
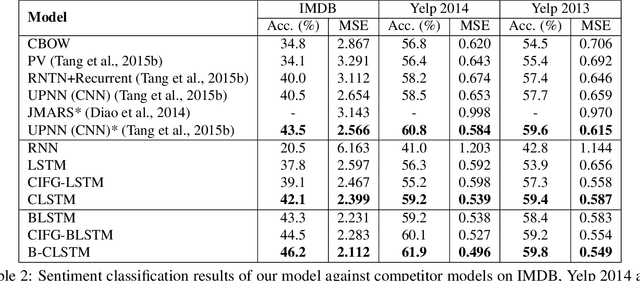
Recently, neural networks have achieved great success on sentiment classification due to their ability to alleviate feature engineering. However, one of the remaining challenges is to model long texts in document-level sentiment classification under a recurrent architecture because of the deficiency of the memory unit. To address this problem, we present a Cached Long Short-Term Memory neural networks (CLSTM) to capture the overall semantic information in long texts. CLSTM introduces a cache mechanism, which divides memory into several groups with different forgetting rates and thus enables the network to keep sentiment information better within a recurrent unit. The proposed CLSTM outperforms the state-of-the-art models on three publicly available document-level sentiment analysis datasets.