 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Linguist Model: Segment Any Object via Bridged Large 3D-Language Model
Sep 09, 2025
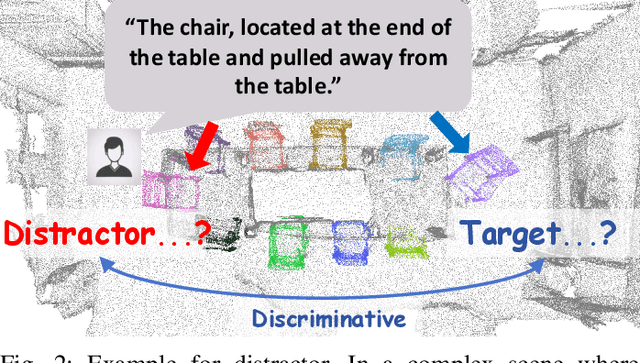


3D object segmentation with Large Language Models (LLMs) has become a prevailing paradigm due to its broad semantics, task flexibility, and strong generalization. However, this paradigm is hindered by representation misalignment: LLMs process high-level semantic tokens, whereas 3D point clouds convey only dense geometric structures. In prior methods, misalignment limits both input and output. At the input stage, dense point patches require heavy pre-alignment, weakening object-level semantics and confusing similar distractors. At the output stage, predictions depend only on dense features without explicit geometric cues, leading to a loss of fine-grained accuracy. To address these limitations, we present the Point Linguist Model (PLM), a general framework that bridges the representation gap between LLMs and dense 3D point clouds without requiring large-scale pre-alignment between 3D-text or 3D-images. Specifically, we introduce Object-centric Discriminative Representation (OcDR), which learns object-centric tokens that capture target semantics and scene relations under a hard negative-aware training objective. This mitigates the misalignment between LLM tokens and 3D points, enhances resilience to distractors, and facilitates semantic-level reasoning within LLMs. For accurate segmentation, we introduce the Geometric Reactivation Decoder (GRD), which predicts masks by combining OcDR tokens carrying LLM-inferred geometry with corresponding dense features, preserving comprehensive dense features throughout the pipeline. Extensive experiments show that PLM achieves significant improvements of +7.3 mIoU on ScanNetv2 and +6.0 mIoU on Multi3DRefer for 3D referring segmentation, with consistent gains across 7 benchmarks spanning 4 different tasks, demonstrating the effectiveness of comprehensive object-centric reasoning for robust 3D understanding.
On Exploring PDE Modeling for Point Cloud Video Representation Learning
Apr 06, 2024Point cloud video representation learning is challenging due to complex structures and unordered spatial arrangement. Traditional methods struggle with frame-to-frame correlations and point-wise correspondence tracking. Recently, partial differential equations (PDE) have provided a new perspective in uniformly solving spatial-temporal data information within certain constraints. While tracking tangible point correspondence remains challenging, we propose to formalize point cloud video representation learning as a PDE-solving problem. Inspired by fluid analysis, where PDEs are used to solve the deformation of spatial shape over time, we employ PDE to solve the variations of spatial points affected by temporal information. By modeling spatial-temporal correlations, we aim to regularize spatial variations with temporal features, thereby enhancing representation learning in point cloud videos. We introduce Motion PointNet composed of a PointNet-like encoder and a PDE-solving module. Initially, we construct a lightweight yet effective encoder to model an initial state of the spatial variations. Subsequently, we develop our PDE-solving module in a parameterized latent space, tailored to address the spatio-temporal correlations inherent in point cloud video. The process of solving PDE is guided and refined by a contrastive learning structure, which is pivotal in reshaping the feature distribution, thereby optimizing the feature representation within point cloud video data. Remarkably, our Motion PointNet achieves an impressive accuracy of 97.52% on the MSRAction-3D dataset, surpassing the current state-of-the-art in all aspects while consuming minimal resources (only 0.72M parameters and 0.82G FLOPs).
Pixel Sentence Representation Learning
Feb 13, 2024



Pretrained language models are long known to be subpar in capturing sentence and document-level semantics. Though heavily investigated, transferring perturbation-based methods from unsupervised visual representation learning to NLP remains an unsolved problem. This is largely due to the discreteness of subword units brought by tokenization of language models, limiting small perturbations of inputs to form semantics-preserved positive pairs. In this work, we conceptualize the learning of sentence-level textual semantics as a visual representation learning process. Drawing from cognitive and linguistic sciences, we introduce an unsupervised visual sentence representation learning framework, employing visually-grounded text perturbation methods like typos and word order shuffling, resonating with human cognitive patterns, and enabling perturbation to texts to be perceived as continuous. Our approach is further bolstered by large-scale unsupervised topical alignment training and natural language inference supervision, achieving comparable performance in semantic textual similarity (STS) to existing state-of-the-art NLP methods. Additionally, we unveil our method's inherent zero-shot cross-lingual transferability and a unique leapfrogging pattern across languages during iterative training. To our knowledge, this is the first representation learning method devoid of traditional language models for understanding sentence and document semantics, marking a stride closer to human-like textual comprehension. Our code is available at https://github.com/gowitheflow-1998/Pixel-Linguist
MF-MOS: A Motion-Focused Model for Moving Object Segmentation
Jan 30, 2024



Moving object segmentation (MOS) provides a reliable solution for detecting traffic participants and thus is of great interest in the autonomous driving field. Dynamic capture is always critical in the MOS problem. Previous methods capture motion features from the range images directly. Differently, we argue that the residual maps provide greater potential for motion information, while range images contain rich semantic guidance. Based on this intuition, we propose MF-MOS, a novel motion-focused model with a dual-branch structure for LiDAR moving object segmentation. Novelly, we decouple the spatial-temporal information by capturing the motion from residual maps and generating semantic features from range images, which are used as movable object guidance for the motion branch. Our straightforward yet distinctive solution can make the most use of both range images and residual maps, thus greatly improving the performance of the LiDAR-based MOS task. Remarkably, our MF-MOS achieved a leading IoU of 76.7% on the MOS leaderboard of the SemanticKITTI dataset upon submission, demonstrating the current state-of-the-art performance. The implementation of our MF-MOS has been released at https://github.com/SCNU-RISLAB/MF-MOS.
LCPFormer: Towards Effective 3D Point Cloud Analysis via Local Context Propagation in Transformers
Oct 23, 2022Transformer with its underlying attention mechanism and the ability to capture long-range dependencies makes it become a natural choice for unordered point cloud data. However, separated local regions from the general sampling architecture corrupt the structural information of the instances, and the inherent relationships between adjacent local regions lack exploration, while local structural information is crucial in a transformer-based 3D point cloud model. Therefore, in this paper, we propose a novel module named Local Context Propagation (LCP) to exploit the message passing between neighboring local regions and make their representations more informative and discriminative. More specifically, we use the overlap points of adjacent local regions (which statistically show to be prevalent) as intermediaries, then re-weight the features of these shared points from different local regions before passing them to the next layers. Inserting the LCP module between two transformer layers results in a significant improvement in network expressiveness. Finally, we design a flexible LCPFormer architecture equipped with the LCP module. The proposed method is applicable to different tasks and outperforms various transformer-based methods in benchmarks including 3D shape classification and dense prediction tasks such as 3D object detection and semantic segmentation. Code will be released for reproduction.