 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVAM: Universal Training-free Adaptive Visual Anchoring Embedded into Multimodal Large Language Model for Multi-image Question Answering
Aug 25, 2025The advancement of Multimodal Large Language Models (MLLMs) has driven significant progress in Visual Question Answering (VQA), evolving from Single to Multi Image VQA (MVQA). However, the increased number of images in MVQA inevitably introduces substantial visual redundancy that is irrelevant to question answering, negatively impacting both accuracy and efficiency. To address this issue, existing methods lack flexibility in controlling the number of compressed visual tokens and tend to produce discrete visual fragments, which hinder MLLMs' ability to comprehend images holistically. In this paper, we propose a straightforward yet universal Adaptive Visual Anchoring strategy, which can be seamlessly integrated into existing MLLMs, offering significant accuracy improvements through adaptive compression. Meanwhile, to balance the results derived from both global and compressed visual input, we further introduce a novel collaborative decoding mechanism, enabling optimal performance. Extensive experiments validate the effectiveness of our method, demonstrating consistent performance improvements across various MLLMs. The code will be publicly available.
TS-CGNet: Temporal-Spatial Fusion Meets Centerline-Guided Diffusion for BEV Mapping
Mar 04, 2025Bird's Eye View (BEV) perception technology is crucial for autonomous driving, as it generates top-down 2D maps for environment perception, navigation, and decision-making. Nevertheless, the majority of current BEV map generation studies focusing on visual map generation lack depth-aware reasoning capabilities. They exhibit limited efficacy in managing occlusions and handling complex environments, with a notable decline in perceptual performance under adverse weather conditions or low-light scenarios. Therefore, this paper proposes TS-CGNet, which leverages Temporal-Spatial fusion with Centerline-Guided diffusion. This visual framework, grounded in prior knowledge, is designed for integration into any existing network for building BEV maps. Specifically, this framework is decoupled into three parts: Local mapping system involves the initial generation of semantic maps using purely visual information; The Temporal-Spatial Aligner Module (TSAM) integrates historical information into mapping generation by applying transformation matrices; The Centerline-Guided Diffusion Model (CGDM) is a prediction module based on the diffusion model. CGDM incorporates centerline information through spatial-attention mechanisms to enhance semantic segmentation reconstruction. We construct BEV semantic segmentation maps by our methods on the public nuScenes and the robustness benchmarks under various corruptions. Our method improves 1.90%, 1.73%, and 2.87% for perceived ranges of 60x30m, 120x60m, and 240x60m in the task of BEV HD mapping. TS-CGNet attains an improvement of 1.92% for perceived ranges of 100x100m in the task of BEV semantic mapping. Moreover, TS-CGNet achieves an average improvement of 2.92% in detection accuracy under varying weather conditions and sensor interferences in the perception range of 240x60m. The source code will be publicly available at https://github.com/krabs-H/TS-CGNet.
MambaMOS: LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model
Apr 19, 2024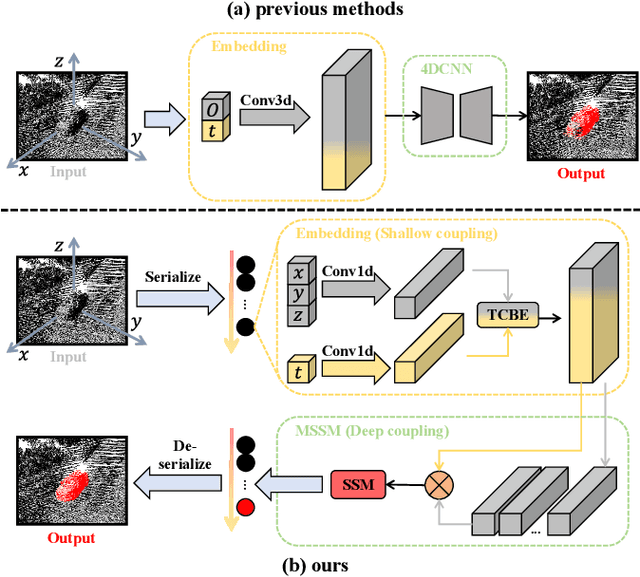
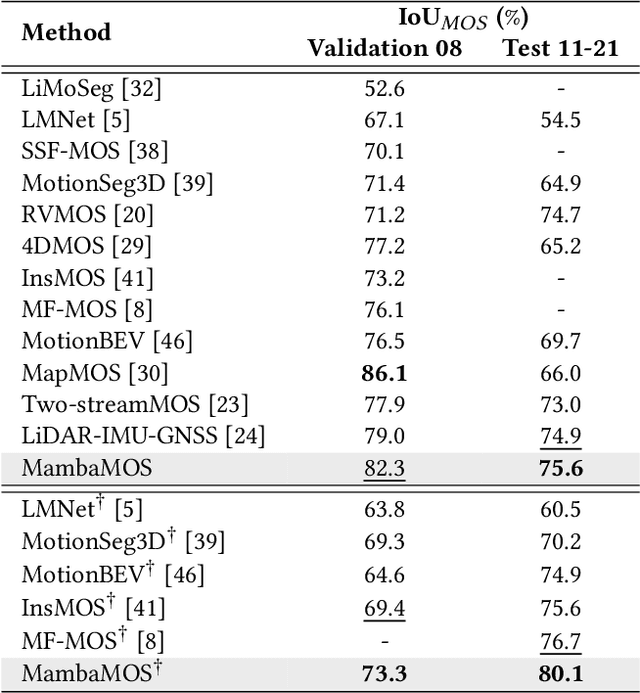
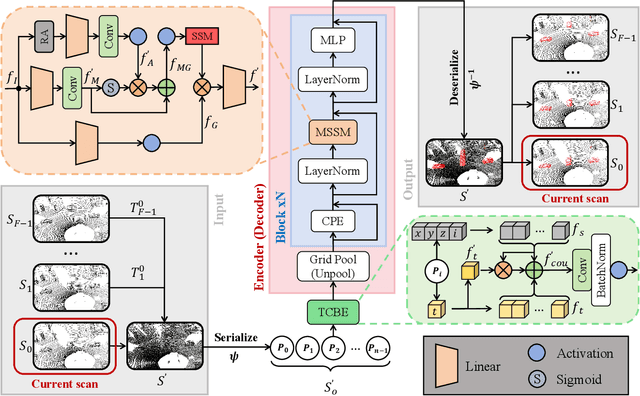
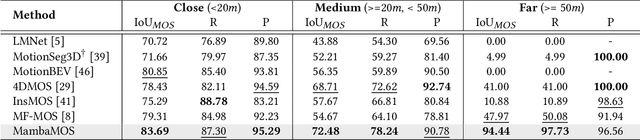
LiDAR-based Moving Object Segmentation (MOS) aims to locate and segment moving objects in point clouds of the current scan using motion information from previous scans. Despite the promising results achieved by previous MOS methods, several key issues, such as the weak coupling of temporal and spatial information, still need further study. In this paper, we propose a novel LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model, termed MambaMOS. Firstly, we develop a novel embedding module, the Time Clue Bootstrapping Embedding (TCBE), to enhance the coupling of temporal and spatial information in point clouds and alleviate the issue of overlooked temporal clues. Secondly, we introduce the Motion-aware State Space Model (MSSM) to endow the model with the capacity to understand the temporal correlations of the same object across different time steps. Specifically, MSSM emphasizes the motion states of the same object at different time steps through two distinct temporal modeling and correlation steps. We utilize an improved state space model to represent these motion differences, significantly modeling the motion states. Finally, extensive experiments on the SemanticKITTI-MOS and KITTI-Road benchmarks demonstrate that the proposed MambaMOS achieves state-of-the-art performance. The source code of this work will be made publicly available at https://github.com/Terminal-K/MambaMOS.
MF-MOS: A Motion-Focused Model for Moving Object Segmentation
Jan 30, 2024



Moving object segmentation (MOS) provides a reliable solution for detecting traffic participants and thus is of great interest in the autonomous driving field. Dynamic capture is always critical in the MOS problem. Previous methods capture motion features from the range images directly. Differently, we argue that the residual maps provide greater potential for motion information, while range images contain rich semantic guidance. Based on this intuition, we propose MF-MOS, a novel motion-focused model with a dual-branch structure for LiDAR moving object segmentation. Novelly, we decouple the spatial-temporal information by capturing the motion from residual maps and generating semantic features from range images, which are used as movable object guidance for the motion branch. Our straightforward yet distinctive solution can make the most use of both range images and residual maps, thus greatly improving the performance of the LiDAR-based MOS task. Remarkably, our MF-MOS achieved a leading IoU of 76.7% on the MOS leaderboard of the SemanticKITTI dataset upon submission, demonstrating the current state-of-the-art performance. The implementation of our MF-MOS has been released at https://github.com/SCNU-RISLAB/MF-MOS.