 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Expert Factors: Trajectory-level Reward Shaping for Formulaic Alpha Mining
Jul 27, 2025
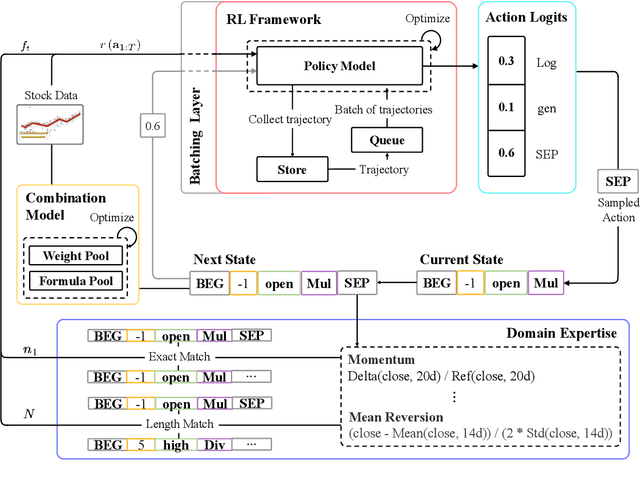
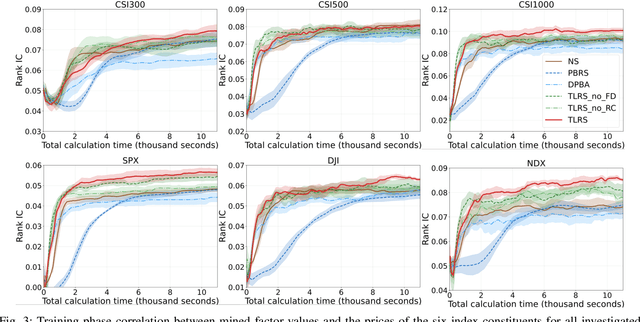
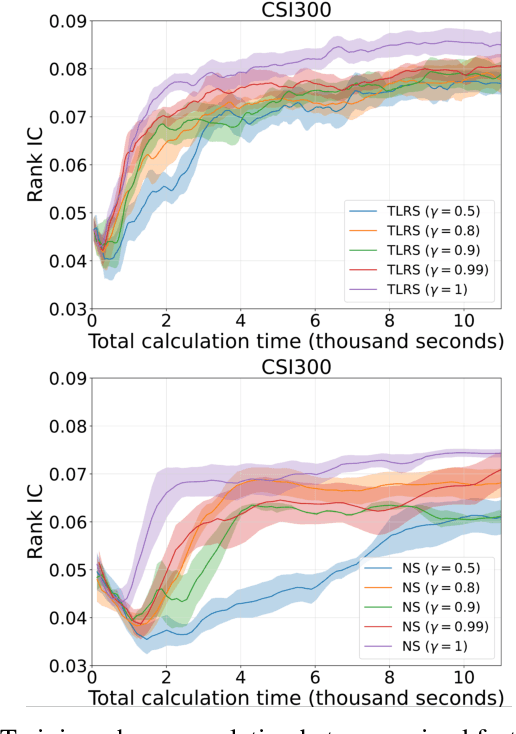
Reinforcement learning (RL) has successfully automated the complex process of mining formulaic alpha factors, for creating interpretable and profitable investment strategies. However, existing methods are hampered by the sparse rewards given the underlying Markov Decision Process. This inefficiency limits the exploration of the vast symbolic search space and destabilizes the training process. To address this, Trajectory-level Reward Shaping (TLRS), a novel reward shaping method, is proposed. TLRS provides dense, intermediate rewards by measuring the subsequence-level similarity between partially generated expressions and a set of expert-designed formulas. Furthermore, a reward centering mechanism is introduced to reduce training variance. Extensive experiments on six major Chinese and U.S. stock indices show that TLRS significantly improves the predictive power of mined factors, boosting the Rank Information Coefficient by 9.29% over existing potential-based shaping algorithms. Notably, TLRS achieves a major leap in computational efficiency by reducing its time complexity with respect to the feature dimension from linear to constant, which is a significant improvement over distance-based baselines.
Real-Time AIoT for UAV Antenna Interference Detection via Edge-Cloud Collaboration
Dec 04, 2024



In the fifth-generation (5G) era, eliminating communication interference sources is crucial for maintaining network performance. Interference often originates from unauthorized or malfunctioning antennas, and radio monitoring agencies must address numerous sources of such antennas annually. Unmanned aerial vehicles (UAVs) can improve inspection efficiency. However, the data transmission delay in the existing cloud-only (CO) artificial intelligence (AI) mode fails to meet the low latency requirements for real-time performance. Therefore, we propose a computer vision-based AI of Things (AIoT) system to detect antenna interference sources for UAVs. The system adopts an optimized edge-cloud collaboration (ECC+) mode, combining a keyframe selection algorithm (KSA), focusing on reducing end-to-end latency (E2EL) and ensuring reliable data transmission, which aligns with the core principles of ultra-reliable low-latency communication (URLLC). At the core of our approach is an end-to-end antenna localization scheme based on the tracking-by-detection (TBD) paradigm, including a detector (EdgeAnt) and a tracker (AntSort). EdgeAnt achieves state-of-the-art (SOTA) performance with a mean average precision (mAP) of 42.1% on our custom antenna interference source dataset, requiring only 3 million parameters and 14.7 GFLOPs. On the COCO dataset, EdgeAnt achieves 38.9% mAP with 5.4 GFLOPs. We deployed EdgeAnt on Jetson Xavier NX (TRT) and Raspberry Pi 4B (NCNN), achieving real-time inference speeds of 21.1 (1088) and 4.8 (640) frames per second (FPS), respectively. Compared with CO mode, the ECC+ mode reduces E2EL by 88.9%, increases accuracy by 28.2%. Additionally, the system offers excellent scalability for coordinated multiple UAVs inspections. The detector code is publicly available at https://github.com/SCNU-RISLAB/EdgeAnt.
QuantFactor REINFORCE: Mining Steady Formulaic Alpha Factors with Variance-bounded REINFORCE
Sep 08, 2024The goal of alpha factor mining is to discover indicative signals of investment opportunities from the historical financial market data of assets. Deep learning based alpha factor mining methods have shown to be powerful, which, however, lack of the interpretability, making them unacceptable in the risk-sensitive real markets. Alpha factors in formulaic forms are more interpretable and therefore favored by market participants, while the search space is complex and powerful explorative methods are urged. Recently, a promising framework is proposed for generating formulaic alpha factors using deep reinforcement learning, and quickly gained research focuses from both academia and industries. This paper first argues that the originally employed policy training method, i.e., Proximal Policy Optimization (PPO), faces several important issues in the context of alpha factors mining, making it ineffective to explore the search space of the formula. Herein, a novel reinforcement learning based on the well-known REINFORCE algorithm is proposed. Given that the underlying state transition function adheres to the Dirac distribution, the Markov Decision Process within this framework exhibit minimal environmental variability, making REINFORCE algorithm more appropriate than PPO. A new dedicated baseline is designed to theoretically reduce the commonly suffered high variance of REINFORCE. Moreover, the information ratio is introduced as a reward shaping mechanism to encourage the generation of steady alpha factors that can better adapt to changes in market volatility. Experimental evaluations on various real assets data show that the proposed algorithm can increase the correlation with asset returns by 3.83%, and a stronger ability to obtain excess returns compared to the latest alpha factors mining methods, which meets the theoretical results well.
YOLO-Ant: A Lightweight Detector via Depthwise Separable Convolutional and Large Kernel Design for Antenna Interference Source Detection
Feb 20, 2024In the era of 5G communication, removing interference sources that affect communication is a resource-intensive task. The rapid development of computer vision has enabled unmanned aerial vehicles to perform various high-altitude detection tasks. Because the field of object detection for antenna interference sources has not been fully explored, this industry lacks dedicated learning samples and detection models for this specific task. In this article, an antenna dataset is created to address important antenna interference source detection issues and serves as the basis for subsequent research. We introduce YOLO-Ant, a lightweight CNN and transformer hybrid detector specifically designed for antenna interference source detection. Specifically, we initially formulated a lightweight design for the network depth and width, ensuring that subsequent investigations were conducted within a lightweight framework. Then, we propose a DSLK-Block module based on depthwise separable convolution and large convolution kernels to enhance the network's feature extraction ability, effectively improving small object detection. To address challenges such as complex backgrounds and large interclass differences in antenna detection, we construct DSLKVit-Block, a powerful feature extraction module that combines DSLK-Block and transformer structures. Considering both its lightweight design and accuracy, our method not only achieves optimal performance on the antenna dataset but also yields competitive results on public datasets.
MF-MOS: A Motion-Focused Model for Moving Object Segmentation
Jan 30, 2024



Moving object segmentation (MOS) provides a reliable solution for detecting traffic participants and thus is of great interest in the autonomous driving field. Dynamic capture is always critical in the MOS problem. Previous methods capture motion features from the range images directly. Differently, we argue that the residual maps provide greater potential for motion information, while range images contain rich semantic guidance. Based on this intuition, we propose MF-MOS, a novel motion-focused model with a dual-branch structure for LiDAR moving object segmentation. Novelly, we decouple the spatial-temporal information by capturing the motion from residual maps and generating semantic features from range images, which are used as movable object guidance for the motion branch. Our straightforward yet distinctive solution can make the most use of both range images and residual maps, thus greatly improving the performance of the LiDAR-based MOS task. Remarkably, our MF-MOS achieved a leading IoU of 76.7% on the MOS leaderboard of the SemanticKITTI dataset upon submission, demonstrating the current state-of-the-art performance. The implementation of our MF-MOS has been released at https://github.com/SCNU-RISLAB/MF-MOS.
BoningKnife: Joint Entity Mention Detection and Typing for Nested NER via prior Boundary Knowledge
Jul 20, 2021
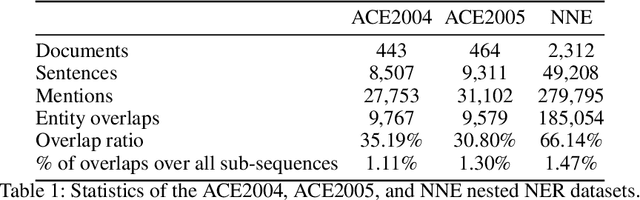
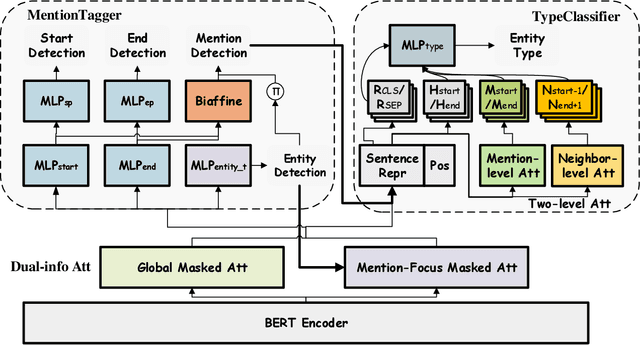
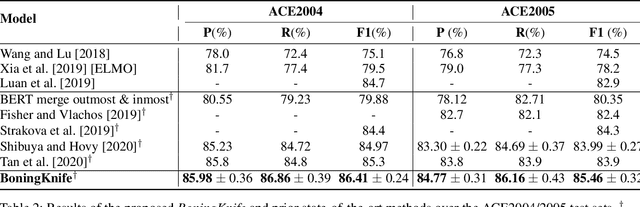
While named entity recognition (NER) is a key task in natural language processing, most approaches only target flat entities, ignoring nested structures which are common in many scenarios. Most existing nested NER methods traverse all sub-sequences which is both expensive and inefficient, and also don't well consider boundary knowledge which is significant for nested entities. In this paper, we propose a joint entity mention detection and typing model via prior boundary knowledge (BoningKnife) to better handle nested NER extraction and recognition tasks. BoningKnife consists of two modules, MentionTagger and TypeClassifier. MentionTagger better leverages boundary knowledge beyond just entity start/end to improve the handling of nesting levels and longer spans, while generating high quality mention candidates. TypeClassifier utilizes a two-level attention mechanism to decouple different nested level representations and better distinguish entity types. We jointly train both modules sharing a common representation and a new dual-info attention layer, which leads to improved representation focus on entity-related information. Experiments over different datasets show that our approach outperforms previous state of the art methods and achieves 86.41, 85.46, and 94.2 F1 scores on ACE2004, ACE2005, and NNE, respectively.