 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity or Precision? A Deep Dive into Next Token Prediction
Dec 28, 2025Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of large language models (LLMs). The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.
BoningKnife: Joint Entity Mention Detection and Typing for Nested NER via prior Boundary Knowledge
Jul 20, 2021
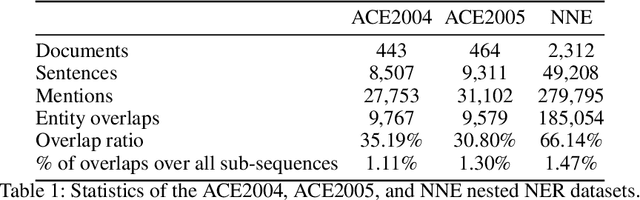
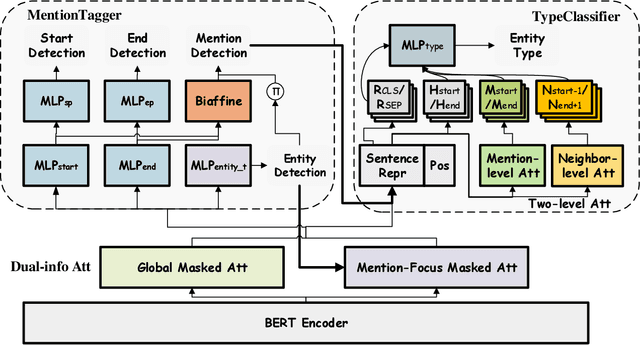
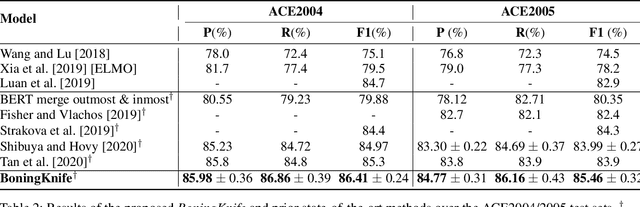
While named entity recognition (NER) is a key task in natural language processing, most approaches only target flat entities, ignoring nested structures which are common in many scenarios. Most existing nested NER methods traverse all sub-sequences which is both expensive and inefficient, and also don't well consider boundary knowledge which is significant for nested entities. In this paper, we propose a joint entity mention detection and typing model via prior boundary knowledge (BoningKnife) to better handle nested NER extraction and recognition tasks. BoningKnife consists of two modules, MentionTagger and TypeClassifier. MentionTagger better leverages boundary knowledge beyond just entity start/end to improve the handling of nesting levels and longer spans, while generating high quality mention candidates. TypeClassifier utilizes a two-level attention mechanism to decouple different nested level representations and better distinguish entity types. We jointly train both modules sharing a common representation and a new dual-info attention layer, which leads to improved representation focus on entity-related information. Experiments over different datasets show that our approach outperforms previous state of the art methods and achieves 86.41, 85.46, and 94.2 F1 scores on ACE2004, ACE2005, and NNE, respectively.
AdvPicker: Effectively Leveraging Unlabeled Data via Adversarial Discriminator for Cross-Lingual NER
Jun 07, 2021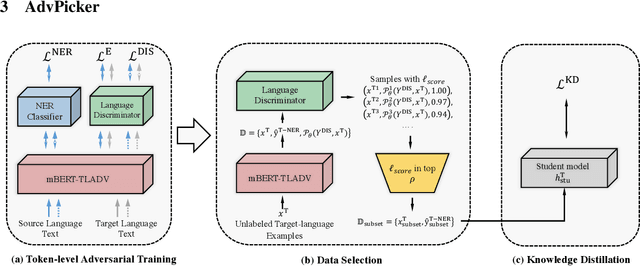
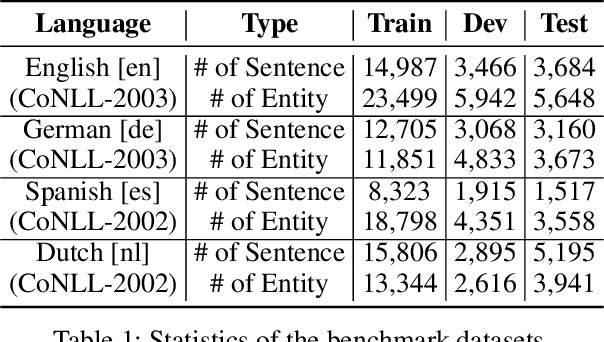
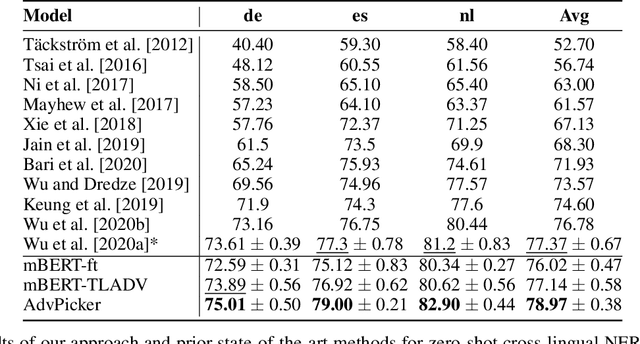
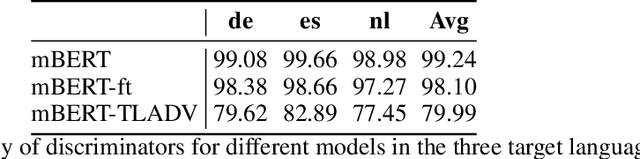
Neural methods have been shown to achieve high performance in Named Entity Recognition (NER), but rely on costly high-quality labeled data for training, which is not always available across languages. While previous works have shown that unlabeled data in a target language can be used to improve cross-lingual model performance, we propose a novel adversarial approach (AdvPicker) to better leverage such data and further improve results. We design an adversarial learning framework in which an encoder learns entity domain knowledge from labeled source-language data and better shared features are captured via adversarial training - where a discriminator selects less language-dependent target-language data via similarity to the source language. Experimental results on standard benchmark datasets well demonstrate that the proposed method benefits strongly from this data selection process and outperforms existing state-of-the-art methods; without requiring any additional external resources (e.g., gazetteers or via machine translation). The code is available at https://aka.ms/AdvPicker
Do recommender systems function in the health domain: a system review
Jul 26, 2020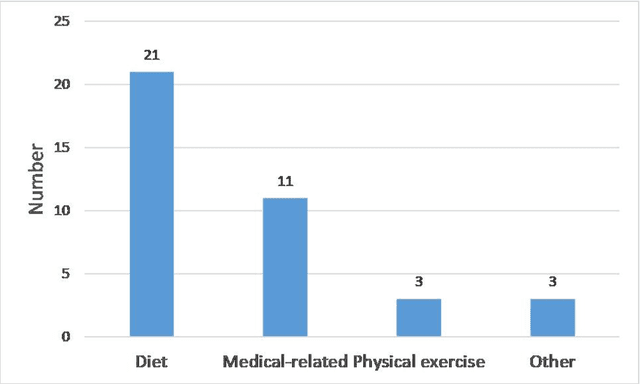
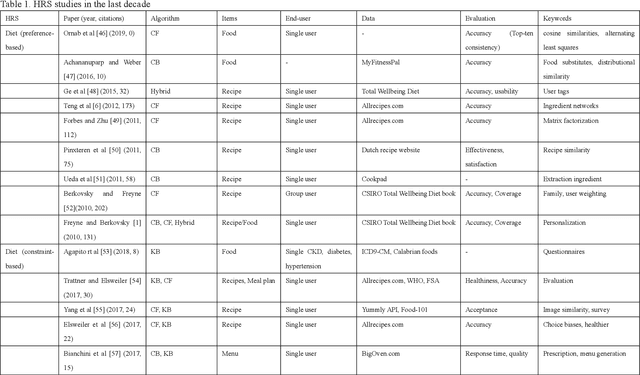
Recommender systems have fulfilled an important role in everyday life. Recommendations such as news by Google, videos by Netflix, goods by e-commerce providers, etc. have heavily changed everyones lifestyle. Health domains contain similar decision-making problems such as what to eat, how to exercise, and what is the proper medicine for a patient. Recently, studies focused on recommender systems to solve health problems have attracted attention. In this paper, we review aspects of health recommender systems including interests, methods, evaluation, future challenges and trend issues. We find that 1) health recommender systems have their own health concern limitations that cause them to focus on less-risky recommendations such as diet recommendation; 2) traditional recommender methods such as content-based and collaborative filtering methods can hardly handle health constraints, but knowledge-based methods function more than ever; 3) evaluating a health recommendation is more complicated than evaluating a commercial one because multiple dimensions in addition to accuracy should be considered. Recommender systems can function well in the health domain after the solution of several key problems. Our work is a systematic review of health recommender system studies, we show current conditions and future directions. It is believed that this review will help domain researchers and promote health recommender systems to the next step.