 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Matters: Benchmarking Factual Error Correction for Dialogue Summarization with Fine-grained Evaluation Framework
Jun 08, 2023



Factuality is important to dialogue summarization. Factual error correction (FEC) of model-generated summaries is one way to improve factuality. Current FEC evaluation that relies on factuality metrics is not reliable and detailed enough. To address this problem, we are the first to manually annotate a FEC dataset for dialogue summarization containing 4000 items and propose FERRANTI, a fine-grained evaluation framework based on reference correction that automatically evaluates the performance of FEC models on different error categories. Using this evaluation framework, we conduct sufficient experiments with FEC approaches under a variety of settings and find the best training modes and significant differences in the performance of the existing approaches on different factual error categories.
Do recommender systems function in the health domain: a system review
Jul 26, 2020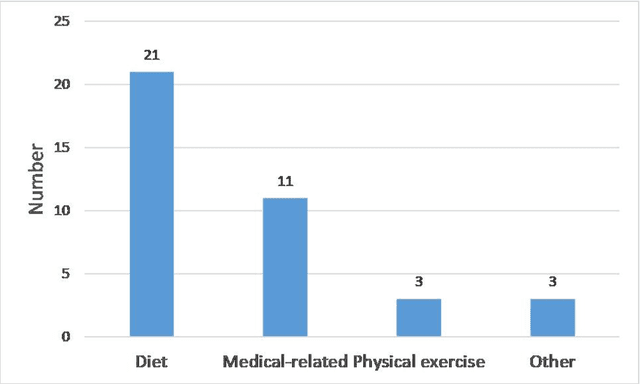
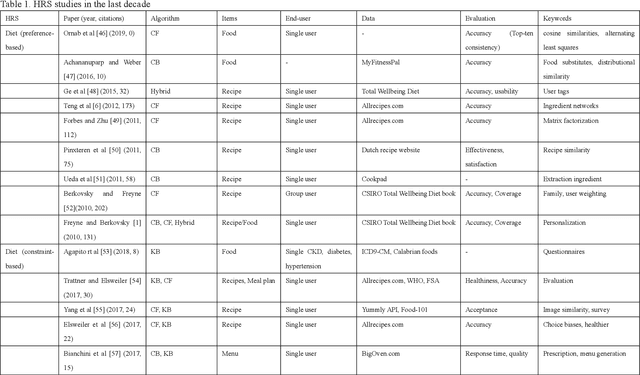
Recommender systems have fulfilled an important role in everyday life. Recommendations such as news by Google, videos by Netflix, goods by e-commerce providers, etc. have heavily changed everyones lifestyle. Health domains contain similar decision-making problems such as what to eat, how to exercise, and what is the proper medicine for a patient. Recently, studies focused on recommender systems to solve health problems have attracted attention. In this paper, we review aspects of health recommender systems including interests, methods, evaluation, future challenges and trend issues. We find that 1) health recommender systems have their own health concern limitations that cause them to focus on less-risky recommendations such as diet recommendation; 2) traditional recommender methods such as content-based and collaborative filtering methods can hardly handle health constraints, but knowledge-based methods function more than ever; 3) evaluating a health recommendation is more complicated than evaluating a commercial one because multiple dimensions in addition to accuracy should be considered. Recommender systems can function well in the health domain after the solution of several key problems. Our work is a systematic review of health recommender system studies, we show current conditions and future directions. It is believed that this review will help domain researchers and promote health recommender systems to the next step.
Developing a cardiovascular disease risk factor annotated corpus of Chinese electronic medical records
Mar 03, 2017
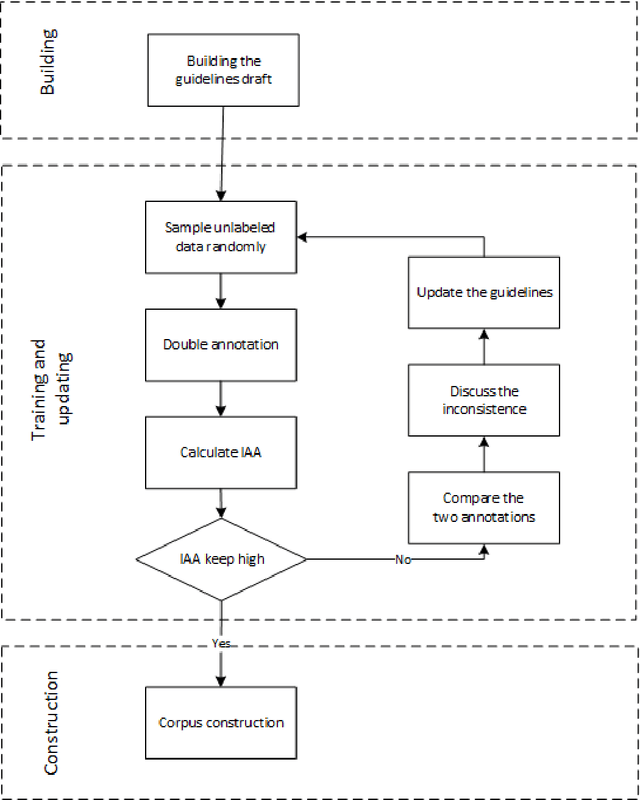
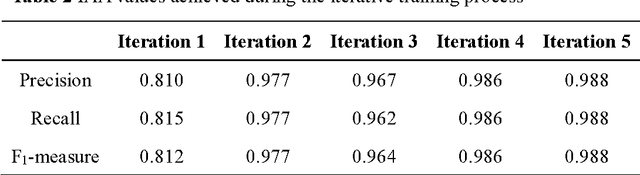

Cardiovascular disease (CVD) has become the leading cause of death in China, and most of the cases can be prevented by controlling risk factors. The goal of this study was to build a corpus of CVD risk factor annotations based on Chinese electronic medical records (CEMRs). This corpus is intended to be used to develop a risk factor information extraction system that, in turn, can be applied as a foundation for the further study of the progress of risk factors and CVD. We designed a light annotation task to capture CVD risk factors with indicators, temporal attributes and assertions that were explicitly or implicitly displayed in the records. The task included: 1) preparing data; 2) creating guidelines for capturing annotations (these were created with the help of clinicians); 3) proposing an annotation method including building the guidelines draft, training the annotators and updating the guidelines, and corpus construction. Then, a risk factor annotated corpus based on de-identified discharge summaries and progress notes from 600 patients was developed. Built with the help of clinicians, this corpus has an inter-annotator agreement (IAA) F1-measure of 0.968, indicating a high reliability. To the best of our knowledge, this is the first annotated corpus concerning CVD risk factors in CEMRs and the guidelines for capturing CVD risk factor annotations from CEMRs were proposed. The obtained document-level annotations can be applied in future studies to monitor risk factors and CVD over the long term.