 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a cardiovascular disease risk factor annotated corpus of Chinese electronic medical records
Paper and Code
Mar 03, 2017
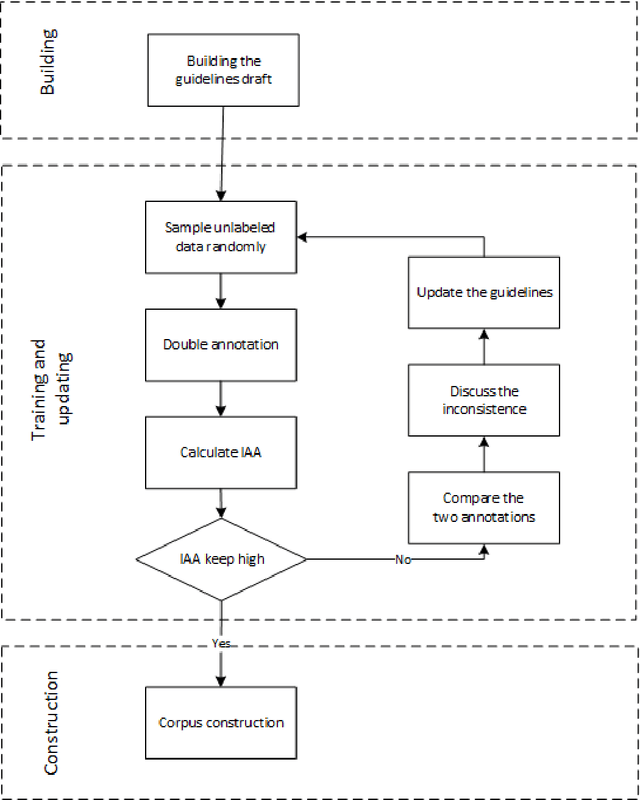
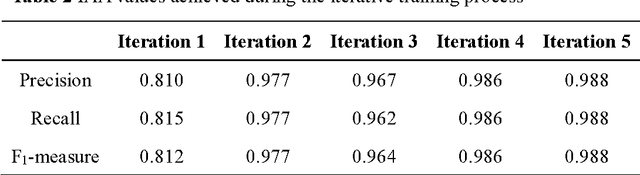

Cardiovascular disease (CVD) has become the leading cause of death in China, and most of the cases can be prevented by controlling risk factors. The goal of this study was to build a corpus of CVD risk factor annotations based on Chinese electronic medical records (CEMRs). This corpus is intended to be used to develop a risk factor information extraction system that, in turn, can be applied as a foundation for the further study of the progress of risk factors and CVD. We designed a light annotation task to capture CVD risk factors with indicators, temporal attributes and assertions that were explicitly or implicitly displayed in the records. The task included: 1) preparing data; 2) creating guidelines for capturing annotations (these were created with the help of clinicians); 3) proposing an annotation method including building the guidelines draft, training the annotators and updating the guidelines, and corpus construction. Then, a risk factor annotated corpus based on de-identified discharge summaries and progress notes from 600 patients was developed. Built with the help of clinicians, this corpus has an inter-annotator agreement (IAA) F1-measure of 0.968, indicating a high reliability. To the best of our knowledge, this is the first annotated corpus concerning CVD risk factors in CEMRs and the guidelines for capturing CVD risk factor annotations from CEMRs were proposed. The obtained document-level annotations can be applied in future studies to monitor risk factors and CVD over the long term.