 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Prediction of Dynamic Physical Simulations With Pixel-Space Spatiotemporal Transformers
Oct 23, 2025Inspired by the performance and scalability of autoregressive large language models (LLMs), transformer-based models have seen recent success in the visual domain. This study investigates a transformer adaptation for video prediction with a simple end-to-end approach, comparing various spatiotemporal self-attention layouts. Focusing on causal modeling of physical simulations over time; a common shortcoming of existing video-generative approaches, we attempt to isolate spatiotemporal reasoning via physical object tracking metrics and unsupervised training on physical simulation datasets. We introduce a simple yet effective pure transformer model for autoregressive video prediction, utilizing continuous pixel-space representations for video prediction. Without the need for complex training strategies or latent feature-learning components, our approach significantly extends the time horizon for physically accurate predictions by up to 50% when compared with existing latent-space approaches, while maintaining comparable performance on common video quality metrics. In addition, we conduct interpretability experiments to identify network regions that encode information useful to perform accurate estimations of PDE simulation parameters via probing models, and find that this generalizes to the estimation of out-of-distribution simulation parameters. This work serves as a platform for further attention-based spatiotemporal modeling of videos via a simple, parameter efficient, and interpretable approach.
* 14 pages, 14 figures
RAR-b: Reasoning as Retrieval Benchmark
Apr 09, 2024



Semantic textual similartiy (STS) and information retrieval tasks (IR) tasks have been the two major avenues to record the progress of embedding models in the past few years. Under the emerging Retrieval-augmented Generation (RAG) paradigm, we envision the need to evaluate next-level language understanding abilities of embedding models, and take a conscious look at the reasoning abilities stored in them. Addressing this, we pose the question: Can retrievers solve reasoning problems? By transforming reasoning tasks into retrieval tasks, we find that without specifically trained for reasoning-level language understanding, current state-of-the-art retriever models may still be far from being competent for playing the role of assisting LLMs, especially in reasoning-intensive tasks. Moreover, albeit trained to be aware of instructions, instruction-aware IR models are often better off without instructions in inference time for reasoning tasks, posing an overlooked retriever-LLM behavioral gap for the research community to align. However, recent decoder-based embedding models show great promise in narrowing the gap, highlighting the pathway for embedding models to achieve reasoning-level language understanding. We also show that, although current off-the-shelf re-ranker models fail on these tasks, injecting reasoning abilities into them through fine-tuning still appears easier than doing so to bi-encoders, and we are able to achieve state-of-the-art performance across all tasks by fine-tuning a reranking model. We release Reasoning as Retrieval Benchmark (RAR-b), a holistic suite of tasks and settings to evaluate the reasoning abilities stored in retriever models. RAR-b is available at https://github.com/gowitheflow-1998/RAR-b.
Pixel Sentence Representation Learning
Feb 13, 2024



Pretrained language models are long known to be subpar in capturing sentence and document-level semantics. Though heavily investigated, transferring perturbation-based methods from unsupervised visual representation learning to NLP remains an unsolved problem. This is largely due to the discreteness of subword units brought by tokenization of language models, limiting small perturbations of inputs to form semantics-preserved positive pairs. In this work, we conceptualize the learning of sentence-level textual semantics as a visual representation learning process. Drawing from cognitive and linguistic sciences, we introduce an unsupervised visual sentence representation learning framework, employing visually-grounded text perturbation methods like typos and word order shuffling, resonating with human cognitive patterns, and enabling perturbation to texts to be perceived as continuous. Our approach is further bolstered by large-scale unsupervised topical alignment training and natural language inference supervision, achieving comparable performance in semantic textual similarity (STS) to existing state-of-the-art NLP methods. Additionally, we unveil our method's inherent zero-shot cross-lingual transferability and a unique leapfrogging pattern across languages during iterative training. To our knowledge, this is the first representation learning method devoid of traditional language models for understanding sentence and document semantics, marking a stride closer to human-like textual comprehension. Our code is available at https://github.com/gowitheflow-1998/Pixel-Linguist
Length is a Curse and a Blessing for Document-level Semantics
Oct 24, 2023In recent years, contrastive learning (CL) has been extensively utilized to recover sentence and document-level encoding capability from pre-trained language models. In this work, we question the length generalizability of CL-based models, i.e., their vulnerability towards length-induced semantic shift. We verify not only that length vulnerability is a significant yet overlooked research gap, but we can devise unsupervised CL methods solely depending on the semantic signal provided by document length. We first derive the theoretical foundations underlying length attacks, showing that elongating a document would intensify the high intra-document similarity that is already brought by CL. Moreover, we found that isotropy promised by CL is highly dependent on the length range of text exposed in training. Inspired by these findings, we introduce a simple yet universal document representation learning framework, LA(SER)$^{3}$: length-agnostic self-reference for semantically robust sentence representation learning, achieving state-of-the-art unsupervised performance on the standard information retrieval benchmark.
MuLD: The Multitask Long Document Benchmark
Feb 15, 2022

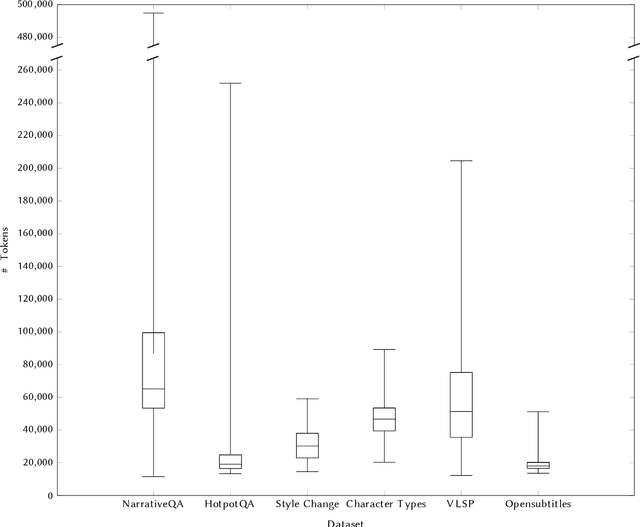
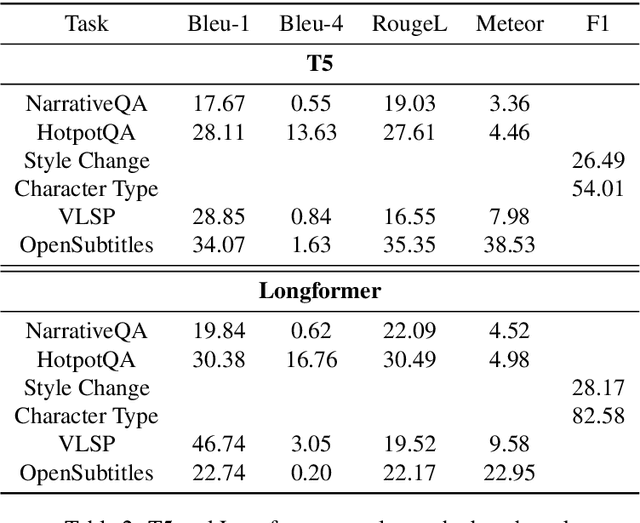
The impressive progress in NLP techniques has been driven by the development of multi-task benchmarks such as GLUE and SuperGLUE. While these benchmarks focus on tasks for one or two input sentences, there has been exciting work in designing efficient techniques for processing much longer inputs. In this paper, we present MuLD: a new long document benchmark consisting of only documents over 10,000 tokens. By modifying existing NLP tasks, we create a diverse benchmark which requires models to successfully model long-term dependencies in the text. We evaluate how existing models perform, and find that our benchmark is much more challenging than their `short document' equivalents. Furthermore, by evaluating both regular and efficient transformers, we show that models with increased context length are better able to solve the tasks presented, suggesting that future improvements in these models are vital for solving similar long document problems. We release the data and code for baselines to encourage further research on efficient NLP models.