 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCPFormer: Towards Effective 3D Point Cloud Analysis via Local Context Propagation in Transformers
Oct 23, 2022Transformer with its underlying attention mechanism and the ability to capture long-range dependencies makes it become a natural choice for unordered point cloud data. However, separated local regions from the general sampling architecture corrupt the structural information of the instances, and the inherent relationships between adjacent local regions lack exploration, while local structural information is crucial in a transformer-based 3D point cloud model. Therefore, in this paper, we propose a novel module named Local Context Propagation (LCP) to exploit the message passing between neighboring local regions and make their representations more informative and discriminative. More specifically, we use the overlap points of adjacent local regions (which statistically show to be prevalent) as intermediaries, then re-weight the features of these shared points from different local regions before passing them to the next layers. Inserting the LCP module between two transformer layers results in a significant improvement in network expressiveness. Finally, we design a flexible LCPFormer architecture equipped with the LCP module. The proposed method is applicable to different tasks and outperforms various transformer-based methods in benchmarks including 3D shape classification and dense prediction tasks such as 3D object detection and semantic segmentation. Code will be released for reproduction.
Beta R-CNN: Looking into Pedestrian Detection from Another Perspective
Oct 23, 2022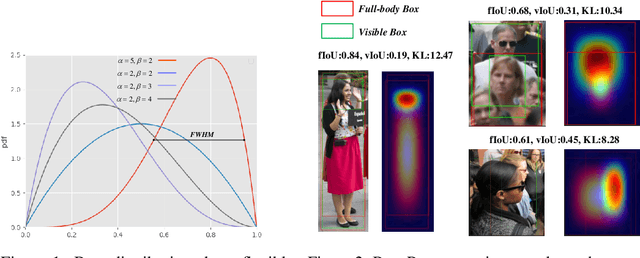

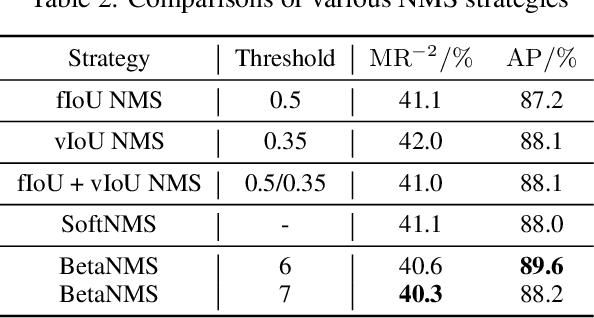
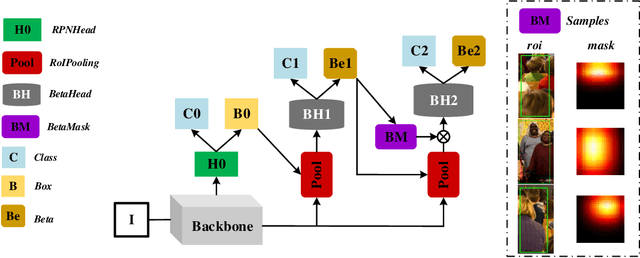
Recently significant progress has been made in pedestrian detection, but it remains challenging to achieve high performance in occluded and crowded scenes. It could be attributed mostly to the widely used representation of pedestrians, i.e., 2D axis-aligned bounding box, which just describes the approximate location and size of the object. Bounding box models the object as a uniform distribution within the boundary, making pedestrians indistinguishable in occluded and crowded scenes due to much noise. To eliminate the problem, we propose a novel representation based on 2D beta distribution, named Beta Representation. It pictures a pedestrian by explicitly constructing the relationship between full-body and visible boxes, and emphasizes the center of visual mass by assigning different probability values to pixels. As a result, Beta Representation is much better for distinguishing highly-overlapped instances in crowded scenes with a new NMS strategy named BetaNMS. What's more, to fully exploit Beta Representation, a novel pipeline Beta R-CNN equipped with BetaHead and BetaMask is proposed, leading to high detection performance in occluded and crowded scenes.
ES-CRF: Embedded Superpixel CRF for Semantic Segmentation
Dec 14, 2021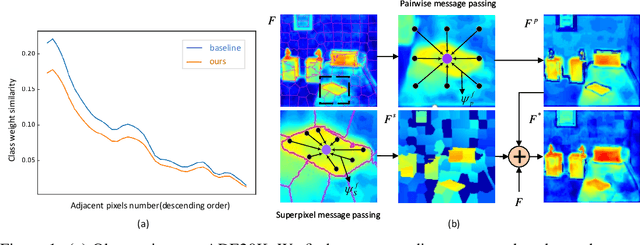
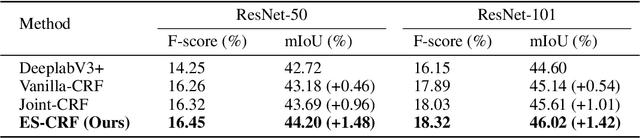
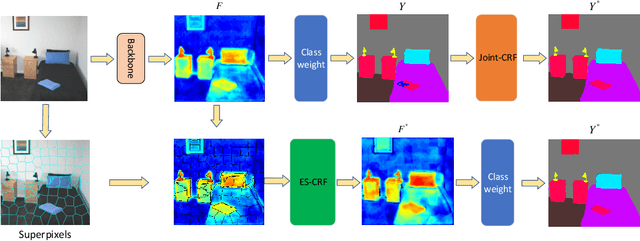

Modern semantic segmentation methods devote much attention to adjusting feature representations to improve the segmentation performance in various ways, such as metric learning, architecture design, etc. However, almost all those methods neglect the particularity of boundary pixels. These pixels are prone to obtain confusing features from both sides due to the continuous expansion of receptive fields in CNN networks. In this way, they will mislead the model optimization direction and make the class weights of such categories that tend to share many adjacent pixels lack discrimination, which will damage the overall performance. In this work, we dive deep into this problem and propose a novel method named Embedded Superpixel CRF (ES-CRF) to address it. ES-CRF involves two main aspects. On the one hand, ES-CRF innovatively fuses the CRF mechanism into the CNN network as an organic whole for more effective end-to-end optimization. It utilizes CRF to guide the message passing between pixels in high-level features to purify the feature representation of boundary pixels, with the help of inner pixels belong to the same object. On the other hand, superpixel is integrated into ES-CRF to exploit the local object prior for more reliable message passing. Finally, our proposed method yields new records on two challenging benchmarks, i.e., Cityscapes and ADE20K. Moreover, we make detailed theoretical analysis to verify the superiority of ES-CRF.
MSP : Refine Boundary Segmentation via Multiscale Superpixel
Dec 03, 2021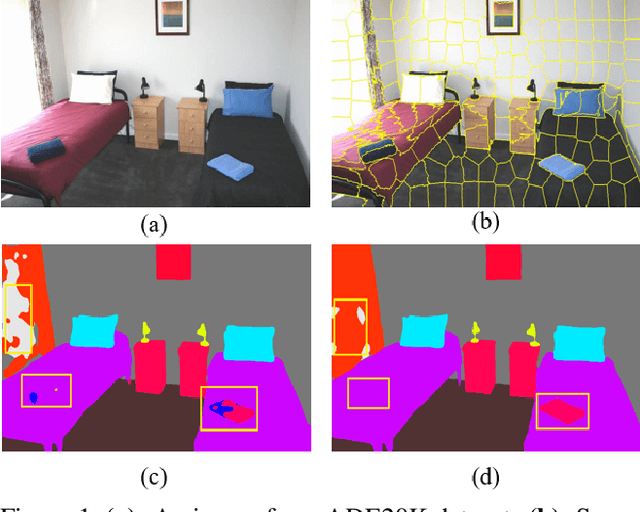

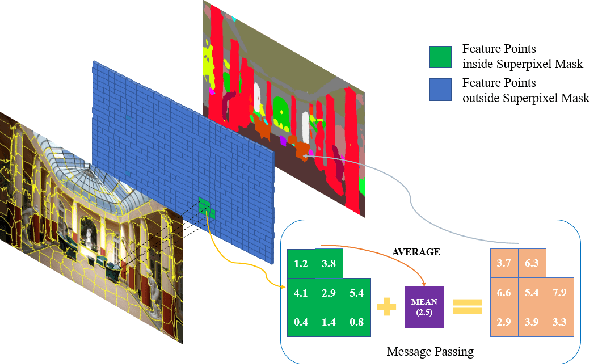
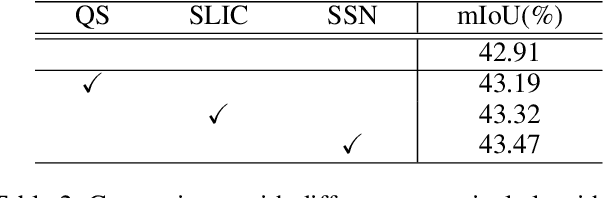
In this paper, we propose a simple but effective message passing method to improve the boundary quality for the semantic segmentation result. Inspired by the generated sharp edges of superpixel blocks, we employ superpixel to guide the information passing within feature map. Simultaneously, the sharp boundaries of the blocks also restrict the message passing scope. Specifically, we average features that the superpixel block covers within feature map, and add the result back to each feature vector. Further, to obtain sharper edges and farther spatial dependence, we develop a multiscale superpixel module (MSP) by a cascade of different scales superpixel blocks. Our method can be served as a plug-and-play module and easily inserted into any segmentation network without introducing new parameters. Extensive experiments are conducted on three strong baselines, namely PSPNet, DeeplabV3, and DeepLabV3+, and four challenging scene parsing datasets including ADE20K, Cityscapes, PASCAL VOC, and PASCAL Context. The experimental results verify its effectiveness and generalizability.
FBNet: Feature Balance Network for Urban-Scene Segmentation
Nov 05, 2021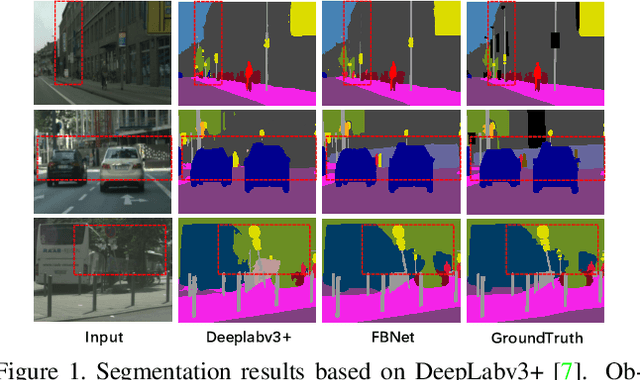


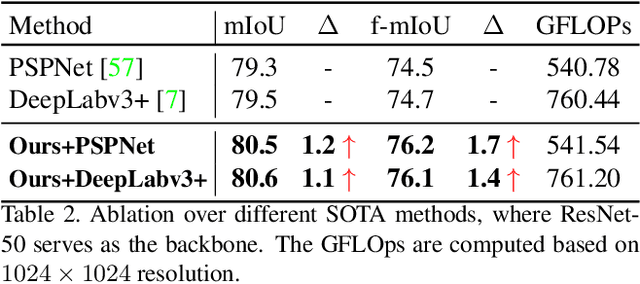
Image segmentation in the urban scene has recently attracted much attention due to its success in autonomous driving systems. However, the poor performance of concerned foreground targets, e.g., traffic lights and poles, still limits its further practical applications. In urban scenes, foreground targets are always concealed in their surrounding stuff because of the special camera position and 3D perspective projection. What's worse, it exacerbates the unbalance between foreground and background classes in high-level features due to the continuous expansion of the reception field. We call it Feature Camouflage. In this paper, we present a novel add-on module, named Feature Balance Network (FBNet), to eliminate the feature camouflage in urban-scene segmentation. FBNet consists of two key components, i.e., Block-wise BCE(BwBCE) and Dual Feature Modulator(DFM). BwBCE serves as an auxiliary loss to ensure uniform gradients for foreground classes and their surroundings during backpropagation. At the same time, DFM intends to enhance the deep representation of foreground classes in high-level features adaptively under the supervision of BwBCE. These two modules facilitate each other as a whole to ease feature camouflage effectively. Our proposed method achieves a new state-of-the-art segmentation performance on two challenging urban-scene benchmarks, i.e., Cityscapes and BDD100K. Code will be released for reproduction.
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
Mar 13, 2021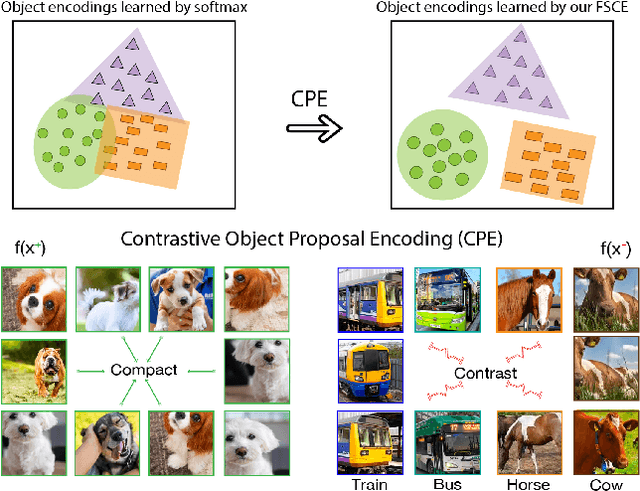


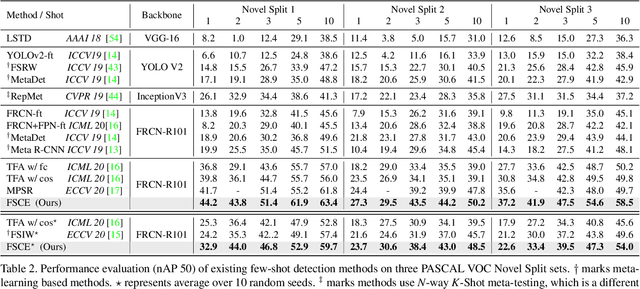
Emerging interests have been brought to recognize previously unseen objects given very few training examples, known as few-shot object detection (FSOD). Recent researches demonstrate that good feature embedding is the key to reach favorable few-shot learning performance. We observe object proposals with different Intersection-of-Union (IoU) scores are analogous to the intra-image augmentation used in contrastive approaches. And we exploit this analogy and incorporate supervised contrastive learning to achieve more robust objects representations in FSOD. We present Few-Shot object detection via Contrastive proposals Encoding (FSCE), a simple yet effective approach to learning contrastive-aware object proposal encodings that facilitate the classification of detected objects. We notice the degradation of average precision (AP) for rare objects mainly comes from misclassifying novel instances as confusable classes. And we ease the misclassification issues by promoting instance level intra-class compactness and inter-class variance via our contrastive proposal encoding loss (CPE loss). Our design outperforms current state-of-the-art works in any shot and all data splits, with up to +8.8% on standard benchmark PASCAL VOC and +2.7% on challenging COCO benchmark. Code is available at: https: //github.com/MegviiDetection/FSCE
AnchorFace: An Anchor-based Facial Landmark Detector Across Large Poses
Jul 07, 2020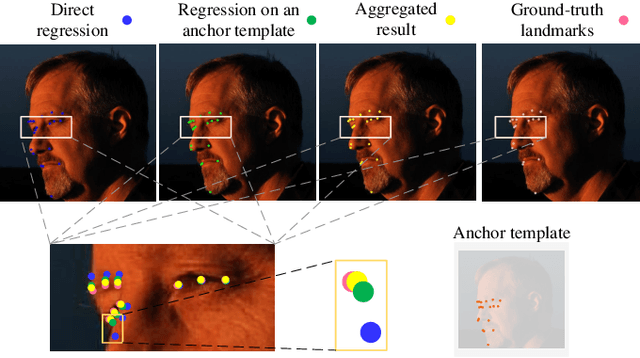

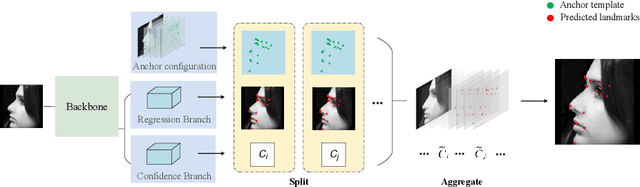
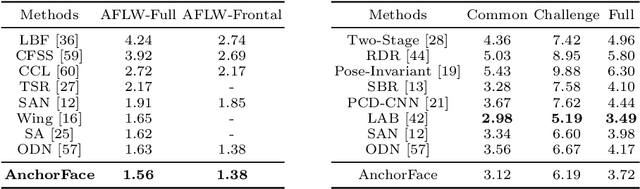
Facial landmark localization aims to detect the predefined points of human faces, and the topic has been rapidly improved with the recent development of neural network based methods. However, it remains a challenging task when dealing with faces in unconstrained scenarios, especially with large pose variations. In this paper, we target the problem of facial landmark localization across large poses and address this task based on a split-and-aggregate strategy. To split the search space, we propose a set of anchor templates as references for regression, which well addresses the large variations of face poses. Based on the prediction of each anchor template, we propose to aggregate the results, which can reduce the landmark uncertainty due to the large poses. Overall, our proposed approach, named AnchorFace, obtains state-of-the-art results with extremely efficient inference speed on four challenging benchmarks, i.e. AFLW, 300W, Menpo, and WFLW dataset. Code will be released for reproduction.