 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeES-CRF: Embedded Superpixel CRF for Semantic Segmentation
Dec 14, 2021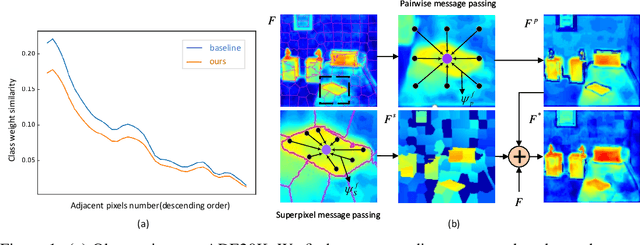
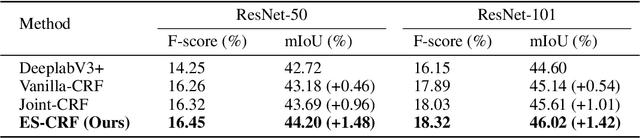
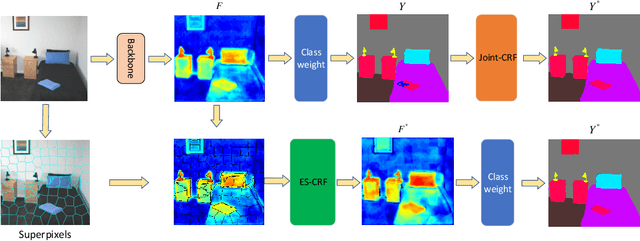

Modern semantic segmentation methods devote much attention to adjusting feature representations to improve the segmentation performance in various ways, such as metric learning, architecture design, etc. However, almost all those methods neglect the particularity of boundary pixels. These pixels are prone to obtain confusing features from both sides due to the continuous expansion of receptive fields in CNN networks. In this way, they will mislead the model optimization direction and make the class weights of such categories that tend to share many adjacent pixels lack discrimination, which will damage the overall performance. In this work, we dive deep into this problem and propose a novel method named Embedded Superpixel CRF (ES-CRF) to address it. ES-CRF involves two main aspects. On the one hand, ES-CRF innovatively fuses the CRF mechanism into the CNN network as an organic whole for more effective end-to-end optimization. It utilizes CRF to guide the message passing between pixels in high-level features to purify the feature representation of boundary pixels, with the help of inner pixels belong to the same object. On the other hand, superpixel is integrated into ES-CRF to exploit the local object prior for more reliable message passing. Finally, our proposed method yields new records on two challenging benchmarks, i.e., Cityscapes and ADE20K. Moreover, we make detailed theoretical analysis to verify the superiority of ES-CRF.
MSP : Refine Boundary Segmentation via Multiscale Superpixel
Dec 03, 2021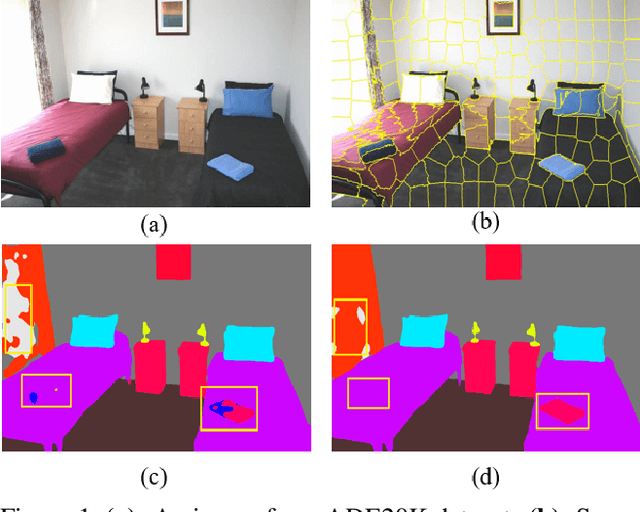

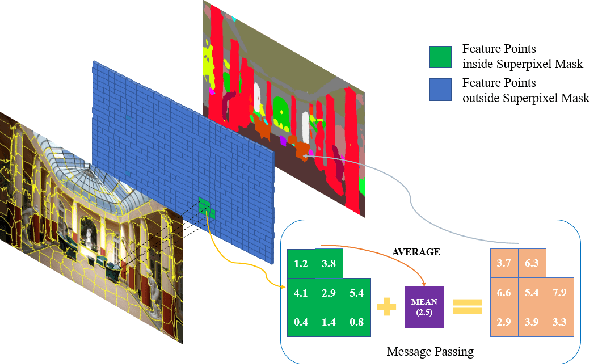
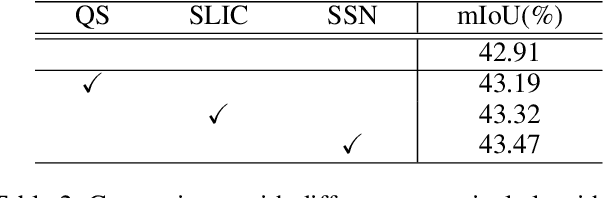
In this paper, we propose a simple but effective message passing method to improve the boundary quality for the semantic segmentation result. Inspired by the generated sharp edges of superpixel blocks, we employ superpixel to guide the information passing within feature map. Simultaneously, the sharp boundaries of the blocks also restrict the message passing scope. Specifically, we average features that the superpixel block covers within feature map, and add the result back to each feature vector. Further, to obtain sharper edges and farther spatial dependence, we develop a multiscale superpixel module (MSP) by a cascade of different scales superpixel blocks. Our method can be served as a plug-and-play module and easily inserted into any segmentation network without introducing new parameters. Extensive experiments are conducted on three strong baselines, namely PSPNet, DeeplabV3, and DeepLabV3+, and four challenging scene parsing datasets including ADE20K, Cityscapes, PASCAL VOC, and PASCAL Context. The experimental results verify its effectiveness and generalizability.
FBNet: Feature Balance Network for Urban-Scene Segmentation
Nov 05, 2021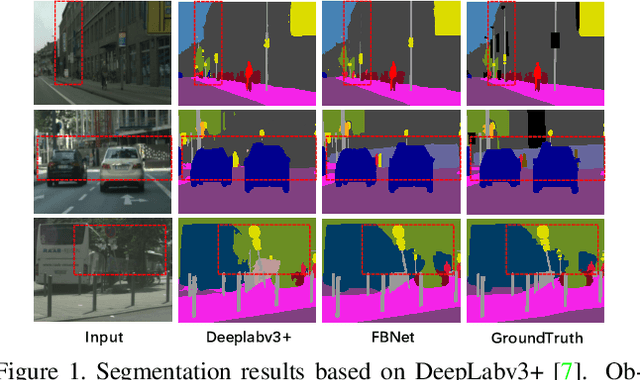


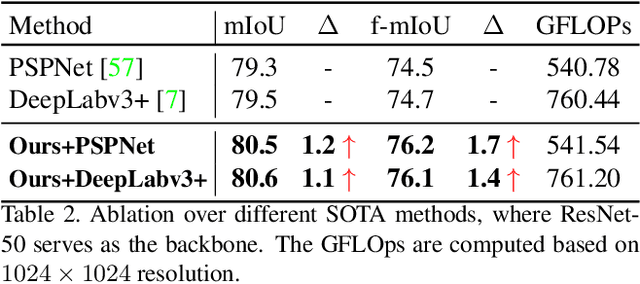
Image segmentation in the urban scene has recently attracted much attention due to its success in autonomous driving systems. However, the poor performance of concerned foreground targets, e.g., traffic lights and poles, still limits its further practical applications. In urban scenes, foreground targets are always concealed in their surrounding stuff because of the special camera position and 3D perspective projection. What's worse, it exacerbates the unbalance between foreground and background classes in high-level features due to the continuous expansion of the reception field. We call it Feature Camouflage. In this paper, we present a novel add-on module, named Feature Balance Network (FBNet), to eliminate the feature camouflage in urban-scene segmentation. FBNet consists of two key components, i.e., Block-wise BCE(BwBCE) and Dual Feature Modulator(DFM). BwBCE serves as an auxiliary loss to ensure uniform gradients for foreground classes and their surroundings during backpropagation. At the same time, DFM intends to enhance the deep representation of foreground classes in high-level features adaptively under the supervision of BwBCE. These two modules facilitate each other as a whole to ease feature camouflage effectively. Our proposed method achieves a new state-of-the-art segmentation performance on two challenging urban-scene benchmarks, i.e., Cityscapes and BDD100K. Code will be released for reproduction.