 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI2Agent: An End-to-End Framework for Deploying AI Projects as Autonomous Agents
Mar 31, 2025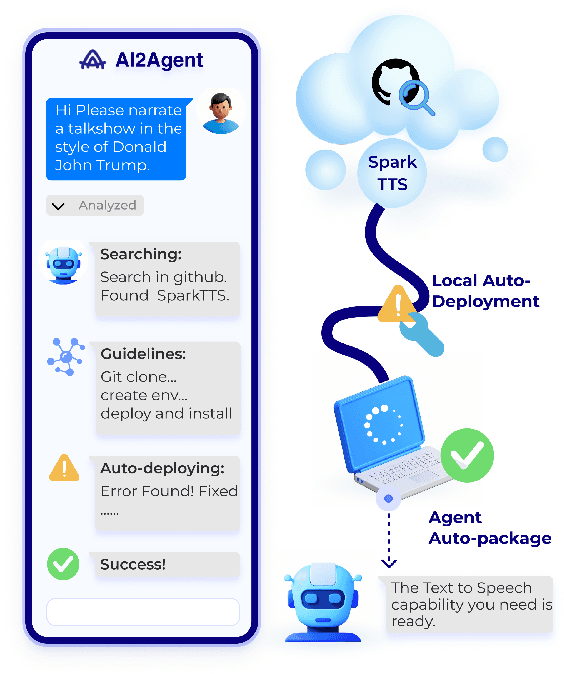
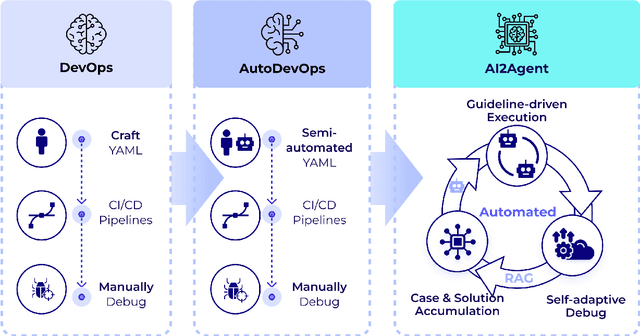
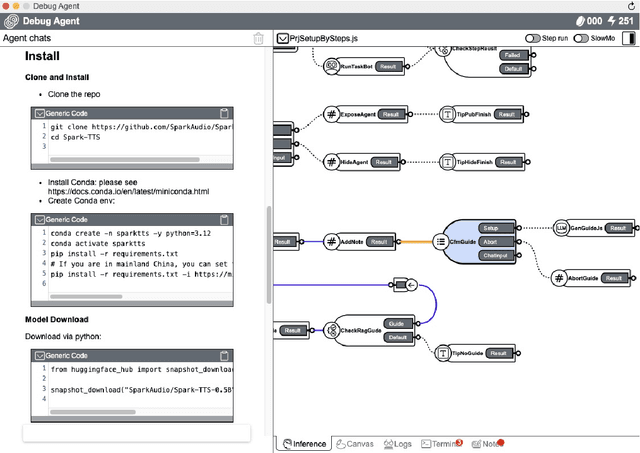
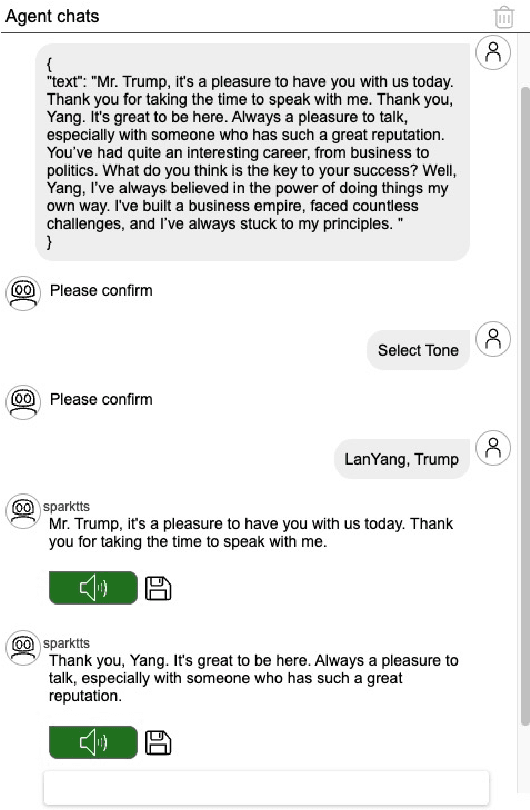
As AI technology advances, it is driving innovation across industries, increasing the demand for scalable AI project deployment. However, deployment remains a critical challenge due to complex environment configurations, dependency conflicts, cross-platform adaptation, and debugging difficulties, which hinder automation and adoption. This paper introduces AI2Agent, an end-to-end framework that automates AI project deployment through guideline-driven execution, self-adaptive debugging, and case \& solution accumulation. AI2Agent dynamically analyzes deployment challenges, learns from past cases, and iteratively refines its approach, significantly reducing human intervention. To evaluate its effectiveness, we conducted experiments on 30 AI deployment cases, covering TTS, text-to-image generation, image editing, and other AI applications. Results show that AI2Agent significantly reduces deployment time and improves success rates. The code and demo video are now publicly accessible.
Dissecting Dissonance: Benchmarking Large Multimodal Models Against Self-Contradictory Instructions
Aug 05, 2024



Large multimodal models (LMMs) excel in adhering to human instructions. However, self-contradictory instructions may arise due to the increasing trend of multimodal interaction and context length, which is challenging for language beginners and vulnerable populations. We introduce the Self-Contradictory Instructions benchmark to evaluate the capability of LMMs in recognizing conflicting commands. It comprises 20,000 conflicts, evenly distributed between language and vision paradigms. It is constructed by a novel automatic dataset creation framework, which expedites the process and enables us to encompass a wide range of instruction forms. Our comprehensive evaluation reveals current LMMs consistently struggle to identify multimodal instruction discordance due to a lack of self-awareness. Hence, we propose the Cognitive Awakening Prompting to inject cognition from external, largely enhancing dissonance detection. The dataset and code are here: https://selfcontradiction.github.io/.
BayesDiff: Estimating Pixel-wise Uncertainty in Diffusion via Bayesian Inference
Oct 17, 2023



Diffusion models have impressive image generation capability, but low-quality generations still exist, and their identification remains challenging due to the lack of a proper sample-wise metric. To address this, we propose BayesDiff, a pixel-wise uncertainty estimator for generations from diffusion models based on Bayesian inference. In particular, we derive a novel uncertainty iteration principle to characterize the uncertainty dynamics in diffusion, and leverage the last-layer Laplace approximation for efficient Bayesian inference. The estimated pixel-wise uncertainty can not only be aggregated into a sample-wise metric to filter out low-fidelity images but also aids in augmenting successful generations and rectifying artifacts in failed generations in text-to-image tasks. Extensive experiments demonstrate the efficacy of BayesDiff and its promise for practical applications.
FBNet: Feature Balance Network for Urban-Scene Segmentation
Nov 05, 2021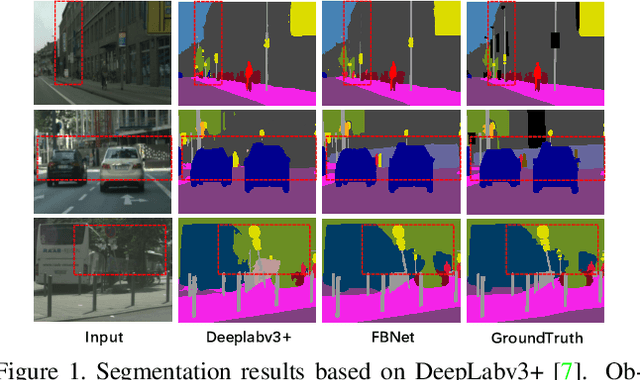


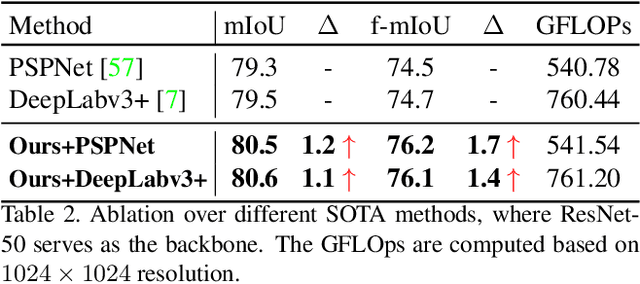
Image segmentation in the urban scene has recently attracted much attention due to its success in autonomous driving systems. However, the poor performance of concerned foreground targets, e.g., traffic lights and poles, still limits its further practical applications. In urban scenes, foreground targets are always concealed in their surrounding stuff because of the special camera position and 3D perspective projection. What's worse, it exacerbates the unbalance between foreground and background classes in high-level features due to the continuous expansion of the reception field. We call it Feature Camouflage. In this paper, we present a novel add-on module, named Feature Balance Network (FBNet), to eliminate the feature camouflage in urban-scene segmentation. FBNet consists of two key components, i.e., Block-wise BCE(BwBCE) and Dual Feature Modulator(DFM). BwBCE serves as an auxiliary loss to ensure uniform gradients for foreground classes and their surroundings during backpropagation. At the same time, DFM intends to enhance the deep representation of foreground classes in high-level features adaptively under the supervision of BwBCE. These two modules facilitate each other as a whole to ease feature camouflage effectively. Our proposed method achieves a new state-of-the-art segmentation performance on two challenging urban-scene benchmarks, i.e., Cityscapes and BDD100K. Code will be released for reproduction.
PAN: Towards Fast Action Recognition via Learning Persistence of Appearance
Aug 08, 2020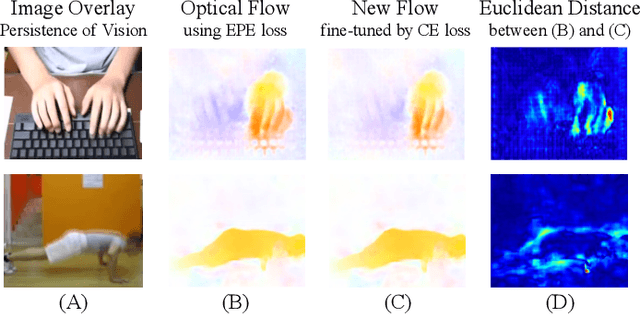
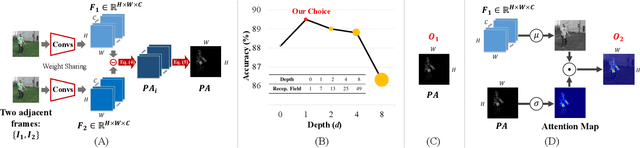
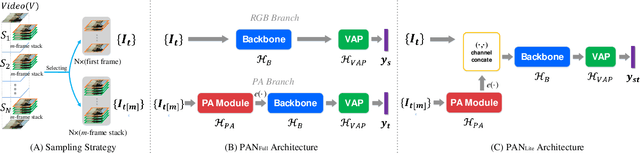
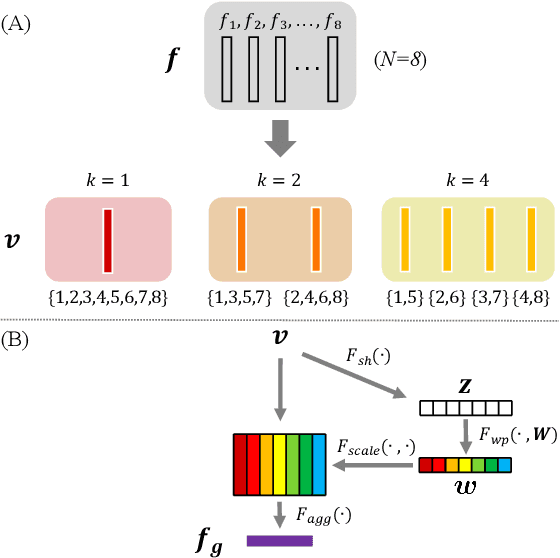
Efficiently modeling dynamic motion information in videos is crucial for action recognition task. Most state-of-the-art methods heavily rely on dense optical flow as motion representation. Although combining optical flow with RGB frames as input can achieve excellent recognition performance, the optical flow extraction is very time-consuming. This undoubtably will count against real-time action recognition. In this paper, we shed light on fast action recognition by lifting the reliance on optical flow. Our motivation lies in the observation that small displacements of motion boundaries are the most critical ingredients for distinguishing actions, so we design a novel motion cue called Persistence of Appearance (PA). In contrast to optical flow, our PA focuses more on distilling the motion information at boundaries. Also, it is more efficient by only accumulating pixel-wise differences in feature space, instead of using exhaustive patch-wise search of all the possible motion vectors. Our PA is over 1000x faster (8196fps vs. 8fps) than conventional optical flow in terms of motion modeling speed. To further aggregate the short-term dynamics in PA to long-term dynamics, we also devise a global temporal fusion strategy called Various-timescale Aggregation Pooling (VAP) that can adaptively model long-range temporal relationships across various timescales. We finally incorporate the proposed PA and VAP to form a unified framework called Persistent Appearance Network (PAN) with strong temporal modeling ability. Extensive experiments on six challenging action recognition benchmarks verify that our PAN outperforms recent state-of-the-art methods at low FLOPs. Codes and models are available at: https://github.com/zhang-can/PAN-PyTorch.