 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: Towards Fast Action Recognition via Learning Persistence of Appearance
Paper and Code
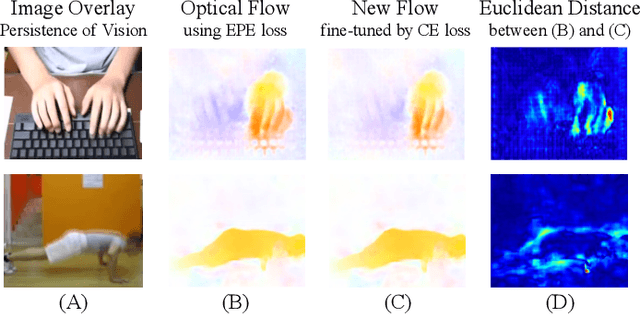
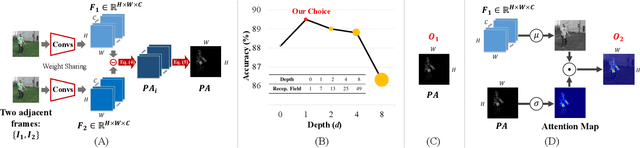
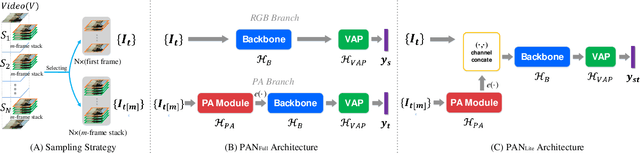
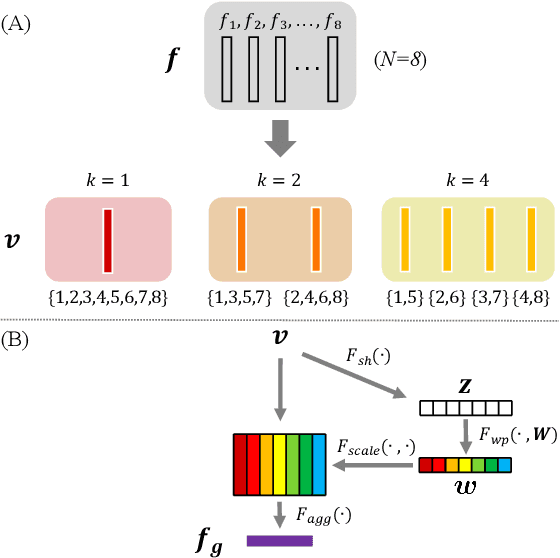
Efficiently modeling dynamic motion information in videos is crucial for action recognition task. Most state-of-the-art methods heavily rely on dense optical flow as motion representation. Although combining optical flow with RGB frames as input can achieve excellent recognition performance, the optical flow extraction is very time-consuming. This undoubtably will count against real-time action recognition. In this paper, we shed light on fast action recognition by lifting the reliance on optical flow. Our motivation lies in the observation that small displacements of motion boundaries are the most critical ingredients for distinguishing actions, so we design a novel motion cue called Persistence of Appearance (PA). In contrast to optical flow, our PA focuses more on distilling the motion information at boundaries. Also, it is more efficient by only accumulating pixel-wise differences in feature space, instead of using exhaustive patch-wise search of all the possible motion vectors. Our PA is over 1000x faster (8196fps vs. 8fps) than conventional optical flow in terms of motion modeling speed. To further aggregate the short-term dynamics in PA to long-term dynamics, we also devise a global temporal fusion strategy called Various-timescale Aggregation Pooling (VAP) that can adaptively model long-range temporal relationships across various timescales. We finally incorporate the proposed PA and VAP to form a unified framework called Persistent Appearance Network (PAN) with strong temporal modeling ability. Extensive experiments on six challenging action recognition benchmarks verify that our PAN outperforms recent state-of-the-art methods at low FLOPs. Codes and models are available at: https://github.com/zhang-can/PAN-PyTorch.