 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Language-Action Model for Unified World Modeling, Language Reasoning, and Action Synthesis
Jun 04, 2026We propose world-language-action (WLA) models as a new class of embodied foundation models. WLA takes textual instructions, images, and robot states as inputs to jointly predict textual subtasks, subgoal images, and robot actions, conjoining the \emph{world modeling interface} to learn from extensive egocentric videos as in the world-action model (WAM) and the \emph{language reasoning} capacities to solve complex long-horizon tasks as in vision-language-action (VLA) models. At the core of WLA lies an \emph{autoregressive (AR)} Transformer backbone, instead of a bidirectional diffusion Transformer as in WAMs, to predict the \emph{next state}, comprising the \emph{semantic-level} textual intention and complementary \emph{fine-grained} physical dynamics. The physical dynamics are supervised by the world modeling objective based on a dedicated World Expert, and are leveraged to ease the characterization of the state-action correlation for the Action Expert. WLA leverages meta-queries to make the world prediction \emph{implicitly} impact the action generation so that the former can be disabled during inference. The world prediction can also be activated to enable test-time scaling for improved robot control. Our WLA-0 prototype, with 2B active parameters, achieves 40 ms per inference on an NVIDIA RTX 5090. Evaluations across simulated and real-world environments demonstrate that WLA-0 achieves state-of-the-art multi-task and long-horizon learning abilities, e.g., 92.94\% success rate on RoboTwin2.0 Clean and 56.5\% success rate on RMBench. WLA-0 also holds the promise to learn novel tasks directly from \emph{cross-embodiment robot videos} without action annotations.
ProductWebGen: Benchmarking Multimodal Product Webpage Generation
May 31, 2026Crafting a product display webpage from a source product image, along with layout and visual content instructions, holds significant practical value for domains such as marketing, advertising, and E-commerce. Intuitively, this task demands strict visual consistency across product displays and high-fidelity instruction following to jointly generate renderable HTML code. These requirements on controllability and instruction-following are closely aligned with the core features of advanced multimodal generative models, such as image editing models and unified models. To this end, this paper introduces ProductWebGen to systematically benchmark the product webpage generation capacities of these models. We organize ProductWebGen with 500 test samples covering 13 product categories; each sample consists of a source image, a visual content instruction, and a webpage instruction. The task is to generate a product showcase webpage including multiple consistent images in accordance with the source image and instructions. Given the mixed-modality input-output nature of the task, we design and systematically compare two workflows for evaluation -- one uses large language models and image editing models to separately generate HTML code and images (editing-based), while the other relies on a single UM to generate both, with image generation conditioned on the preceding multimodal context (UM-based). Empirical results show that editing-based approaches achieve leading results in webpage instruction following and content appeal, while UM-based ones may display more advantages in fulfilling visual content instructions. We also construct a supervised fine-tuning dataset, ProductWebGen-1k, with 1,000 groups of real product images and LLM-generated HTML code. We verify its effectiveness on the open-source UM BAGEL. The data and code are available at https://github.com/SJTU-DENG-Lab/ProductWebGen.
Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders
Jan 15, 2026Recent progress in text-to-image (T2I) diffusion models (DMs) has enabled high-quality visual synthesis from diverse textual prompts. Yet, most existing T2I DMs, even those equipped with large language model (LLM)-based text encoders, remain text-pixel mappers -- they employ LLMs merely as text encoders, without leveraging their inherent reasoning capabilities to infer what should be visually depicted given the textual prompt. To move beyond such literal generation, we propose the think-then-generate (T2G) paradigm, where the LLM-based text encoder is encouraged to reason about and rewrite raw user prompts; the states of the rewritten prompts then serve as diffusion conditioning. To achieve this, we first activate the think-then-rewrite pattern of the LLM encoder with a lightweight supervised fine-tuning process. Subsequently, the LLM encoder and diffusion backbone are co-optimized to ensure faithful reasoning about the context and accurate rendering of the semantics via Dual-GRPO. In particular, the text encoder is reinforced using image-grounded rewards to infer and recall world knowledge, while the diffusion backbone is pushed to produce semantically consistent and visually coherent images. Experiments show substantial improvements in factual consistency, semantic alignment, and visual realism across reasoning-based image generation and editing benchmarks, achieving 0.79 on WISE score, nearly on par with GPT-4. Our results constitute a promising step toward next-generation unified models with reasoning, expression, and demonstration capacities.
Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
Thinking with Generated Images
May 28, 2025We present Thinking with Generated Images, a novel paradigm that fundamentally transforms how large multimodal models (LMMs) engage with visual reasoning by enabling them to natively think across text and vision modalities through spontaneous generation of intermediate visual thinking steps. Current visual reasoning with LMMs is constrained to either processing fixed user-provided images or reasoning solely through text-based chain-of-thought (CoT). Thinking with Generated Images unlocks a new dimension of cognitive capability where models can actively construct intermediate visual thoughts, critique their own visual hypotheses, and refine them as integral components of their reasoning process. We demonstrate the effectiveness of our approach through two complementary mechanisms: (1) vision generation with intermediate visual subgoals, where models decompose complex visual tasks into manageable components that are generated and integrated progressively, and (2) vision generation with self-critique, where models generate an initial visual hypothesis, analyze its shortcomings through textual reasoning, and produce refined outputs based on their own critiques. Our experiments on vision generation benchmarks show substantial improvements over baseline approaches, with our models achieving up to 50% (from 38% to 57%) relative improvement in handling complex multi-object scenarios. From biochemists exploring novel protein structures, and architects iterating on spatial designs, to forensic analysts reconstructing crime scenes, and basketball players envisioning strategic plays, our approach enables AI models to engage in the kind of visual imagination and iterative refinement that characterizes human creative, analytical, and strategic thinking. We release our open-source suite at https://github.com/GAIR-NLP/thinking-with-generated-images.
Which Data Attributes Stimulate Math and Code Reasoning? An Investigation via Influence Functions
May 26, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities in math and coding, often bolstered by post-training on the chain-of-thoughts (CoTs) generated by stronger models. However, existing strategies for curating such training data predominantly rely on heuristics, limiting generalizability and failing to capture subtleties underlying in data. To address these limitations, we leverage influence functions to systematically attribute LLMs' reasoning ability on math and coding to individual training examples, sequences, and tokens, enabling deeper insights into effective data characteristics. Our Influence-based Reasoning Attribution (Infra) uncovers nontrivial cross-domain effects across math and coding tasks: high-difficulty math examples improve both math and code reasoning, while low-difficulty code tasks most effectively benefit code reasoning. Based on these findings, we introduce a simple yet effective dataset reweighting strategy by flipping task difficulty, which doubles AIME24 accuracy from 10\% to 20\% and boosts LiveCodeBench accuracy from 33.8\% to 35.3\% for Qwen2.5-7B-Instruct. Moreover, our fine-grained attribution reveals that the sequence-level exploratory behaviors enhance reasoning performance in both math and code, and the token-level influence patterns are distinct for math and code reasoning: the former prefers natural language logic connectors and the latter emphasizes structural syntax.
Orthus: Autoregressive Interleaved Image-Text Generation with Modality-Specific Heads
Nov 28, 2024
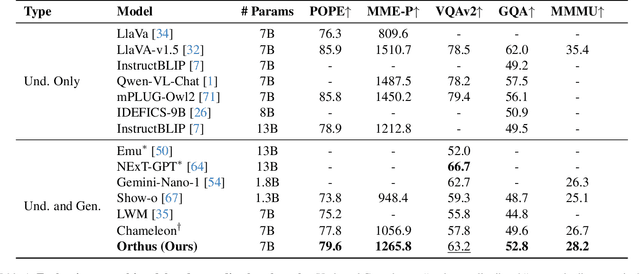
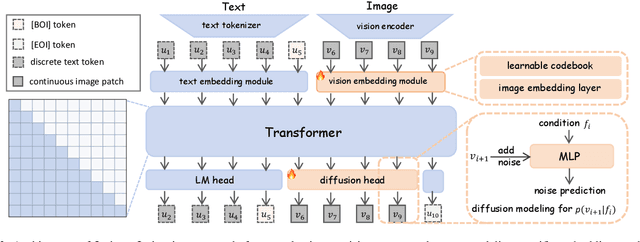
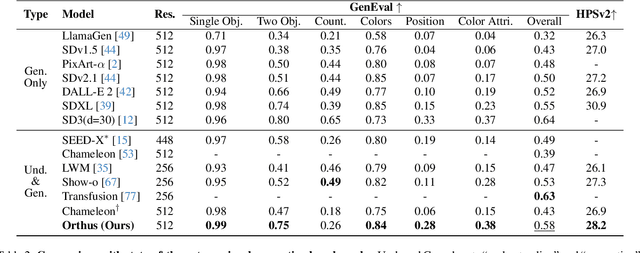
We introduce Orthus, an autoregressive (AR) transformer that excels in generating images given textual prompts, answering questions based on visual inputs, and even crafting lengthy image-text interleaved contents. Unlike prior arts on unified multimodal modeling, Orthus simultaneously copes with discrete text tokens and continuous image features under the AR modeling principle. The continuous treatment of visual signals minimizes the information loss for both image understanding and generation while the fully AR formulation renders the characterization of the correlation between modalities straightforward. The key mechanism enabling Orthus to leverage these advantages lies in its modality-specific heads -- one regular language modeling (LM) head predicts discrete text tokens and one diffusion head generates continuous image features conditioning on the output of the backbone. We devise an efficient strategy for building Orthus -- by substituting the Vector Quantization (VQ) operation in the existing unified AR model with a soft alternative, introducing a diffusion head, and tuning the added modules to reconstruct images, we can create an Orthus-base model effortlessly (e.g., within mere 72 A100 GPU hours). Orthus-base can further embrace post-training to better model interleaved images and texts. Empirically, Orthus surpasses competing baselines including Show-o and Chameleon across standard benchmarks, achieving a GenEval score of 0.58 and an MME-P score of 1265.8 using 7B parameters. Orthus also shows exceptional mixed-modality generation capabilities, reflecting the potential for handling intricate practical generation tasks.
MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection
Oct 16, 2024



KV cache has become a de facto technique for the inference of large language models (LLMs), where tensors of shape (layer number, head number, sequence length, feature dimension) are introduced to cache historical information for self-attention. As the size of the model and data grows, the KV cache can quickly become a bottleneck within the system in both storage and memory transfer. To address this, prior studies usually focus on the first three axes of the cache tensors for compression. This paper supplements them, focusing on the feature dimension axis, by utilizing low-rank projection matrices to transform the cache features into spaces with reduced dimensions. We begin by investigating the canonical orthogonal projection method for data compression through principal component analysis (PCA). We observe the issue with PCA projection where significant performance degradation is observed at low compression rates. To bridge the gap, we propose to directly tune the orthogonal projection matrices with a distillation objective using an elaborate Matryoshka training strategy. After training, we adaptively search for the optimal compression rates for various layers and heads given varying compression budgets. Compared to previous works, our method can easily embrace pre-trained LLMs and hold a smooth tradeoff between performance and compression rate. We empirically witness the high data efficiency of our training procedure and find that our method can sustain over 90% performance with an average KV cache compression rate of 60% (and up to 75% in certain extreme scenarios) for popular LLMs like LLaMA2-7B-base and Mistral-7B-v0.3-base.
CLLMs: Consistency Large Language Models
Mar 08, 2024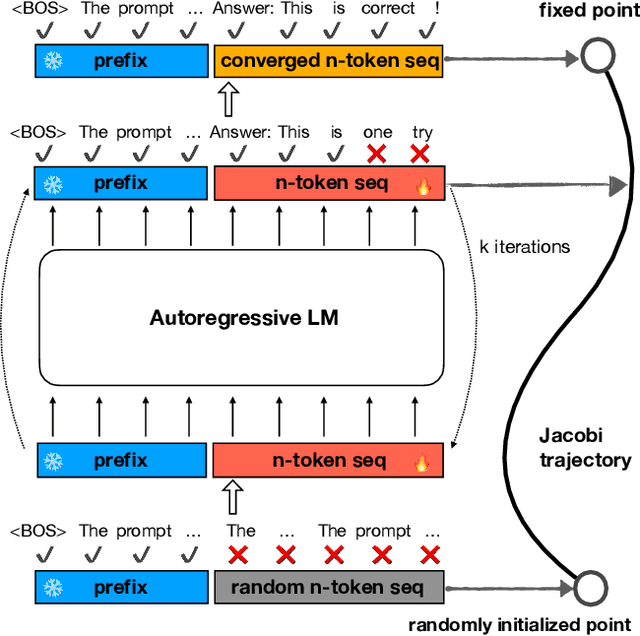
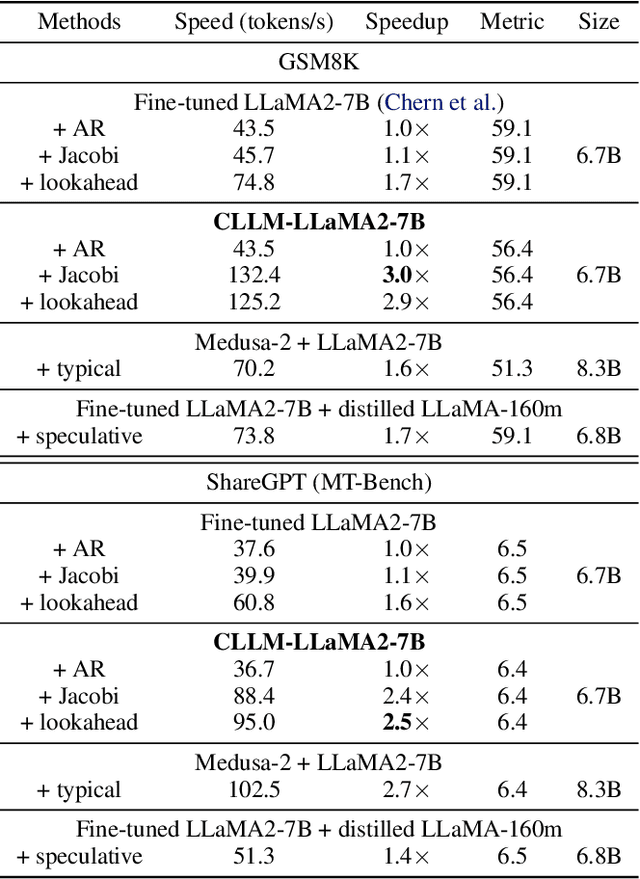

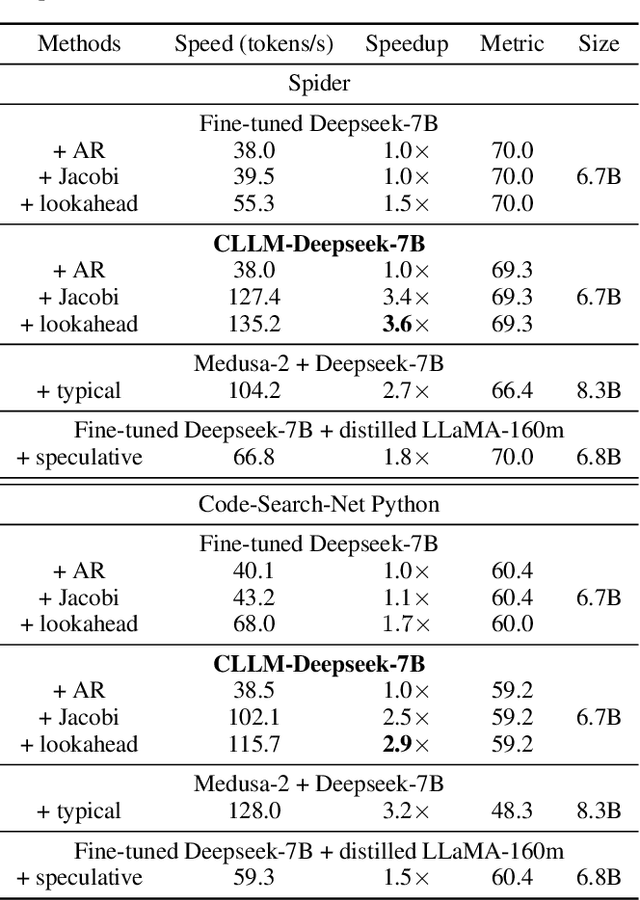
Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$\times$ to 3.4$\times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.
BayesDiff: Estimating Pixel-wise Uncertainty in Diffusion via Bayesian Inference
Oct 17, 2023



Diffusion models have impressive image generation capability, but low-quality generations still exist, and their identification remains challenging due to the lack of a proper sample-wise metric. To address this, we propose BayesDiff, a pixel-wise uncertainty estimator for generations from diffusion models based on Bayesian inference. In particular, we derive a novel uncertainty iteration principle to characterize the uncertainty dynamics in diffusion, and leverage the last-layer Laplace approximation for efficient Bayesian inference. The estimated pixel-wise uncertainty can not only be aggregated into a sample-wise metric to filter out low-fidelity images but also aids in augmenting successful generations and rectifying artifacts in failed generations in text-to-image tasks. Extensive experiments demonstrate the efficacy of BayesDiff and its promise for practical applications.