 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLLMs: Consistency Large Language Models
Paper and Code
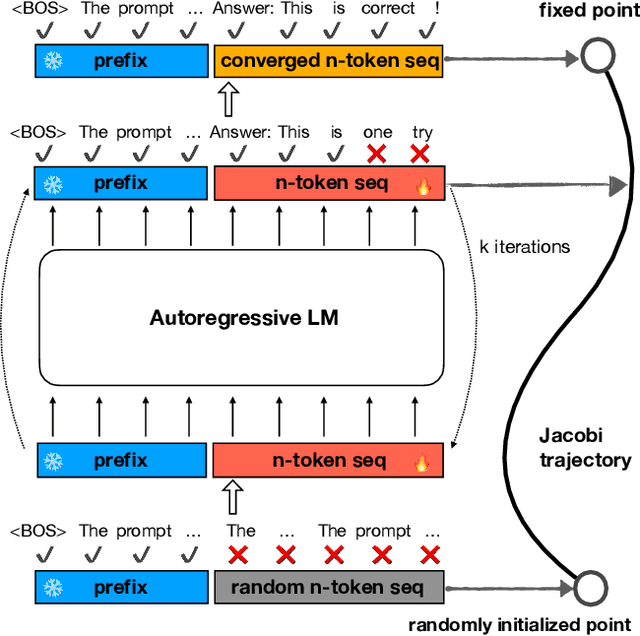
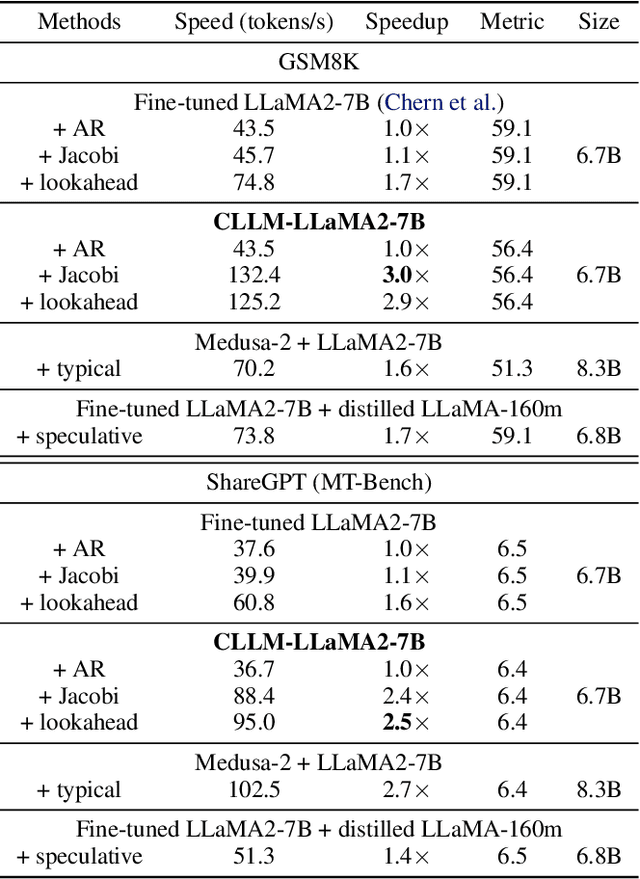

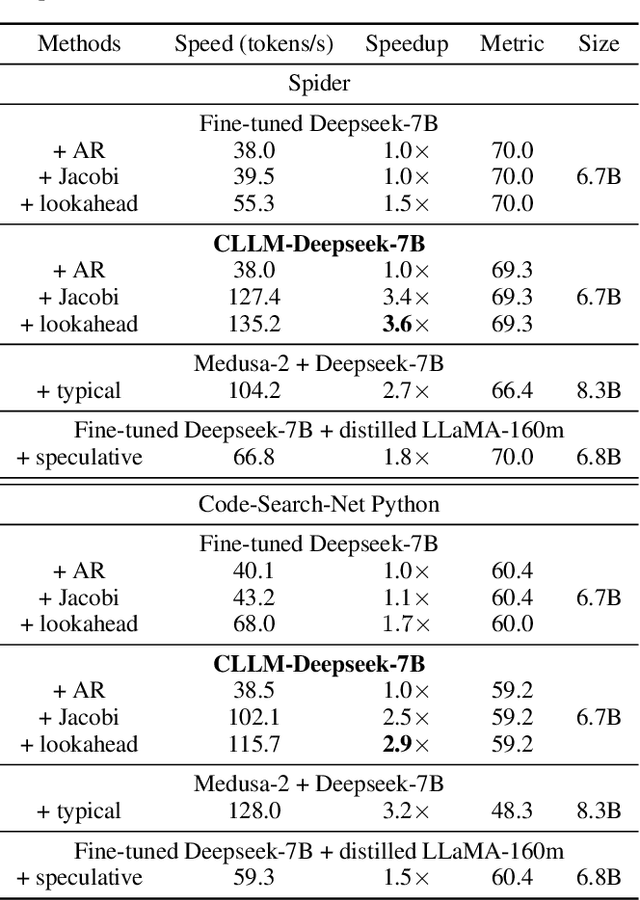
Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$\times$ to 3.4$\times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.