 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Dec 29, 2025Real-time video generation via diffusion is essential for building general-purpose multimodal interactive AI systems. However, the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models prevents real-time interaction. While existing distillation methods can make the model autoregressive and reduce sampling steps to mitigate this, they focus primarily on text-to-video generation, leaving the human-AI interaction unnatural and less efficient. This paper targets real-time interactive video diffusion conditioned on a multimodal context, including text, image, and audio, to bridge the gap. Given the observation that the leading on-policy distillation approach Self Forcing encounters challenges (visual artifacts like flickering, black frames, and quality degradation) with multimodal conditioning, we investigate an improved distillation recipe with emphasis on the quality of condition inputs as well as the initialization and schedule for the on-policy optimization. On benchmarks for multimodal-conditioned (audio, image, and text) avatar video generation including HDTF, AVSpeech, and CelebV-HQ, our distilled model matches the visual quality of the full-step, bidirectional baselines of similar or larger size with 20x less inference cost and latency. Further, we integrate our model with audio language models and long-form video inference technique Anchor-Heavy Identity Sinks to build LiveTalk, a real-time multimodal interactive avatar system. System-level evaluation on our curated multi-turn interaction benchmark shows LiveTalk outperforms state-of-the-art models (Sora2, Veo3) in multi-turn video coherence and content quality, while reducing response latency from 1 to 2 minutes to real-time generation, enabling seamless human-AI multimodal interaction.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
Thinking with Generated Images
May 28, 2025We present Thinking with Generated Images, a novel paradigm that fundamentally transforms how large multimodal models (LMMs) engage with visual reasoning by enabling them to natively think across text and vision modalities through spontaneous generation of intermediate visual thinking steps. Current visual reasoning with LMMs is constrained to either processing fixed user-provided images or reasoning solely through text-based chain-of-thought (CoT). Thinking with Generated Images unlocks a new dimension of cognitive capability where models can actively construct intermediate visual thoughts, critique their own visual hypotheses, and refine them as integral components of their reasoning process. We demonstrate the effectiveness of our approach through two complementary mechanisms: (1) vision generation with intermediate visual subgoals, where models decompose complex visual tasks into manageable components that are generated and integrated progressively, and (2) vision generation with self-critique, where models generate an initial visual hypothesis, analyze its shortcomings through textual reasoning, and produce refined outputs based on their own critiques. Our experiments on vision generation benchmarks show substantial improvements over baseline approaches, with our models achieving up to 50% (from 38% to 57%) relative improvement in handling complex multi-object scenarios. From biochemists exploring novel protein structures, and architects iterating on spatial designs, to forensic analysts reconstructing crime scenes, and basketball players envisioning strategic plays, our approach enables AI models to engage in the kind of visual imagination and iterative refinement that characterizes human creative, analytical, and strategic thinking. We release our open-source suite at https://github.com/GAIR-NLP/thinking-with-generated-images.
PC Agent: While You Sleep, AI Works -- A Cognitive Journey into Digital World
Dec 23, 2024



Imagine a world where AI can handle your work while you sleep - organizing your research materials, drafting a report, or creating a presentation you need for tomorrow. However, while current digital agents can perform simple tasks, they are far from capable of handling the complex real-world work that humans routinely perform. We present PC Agent, an AI system that demonstrates a crucial step toward this vision through human cognition transfer. Our key insight is that the path from executing simple "tasks" to handling complex "work" lies in efficiently capturing and learning from human cognitive processes during computer use. To validate this hypothesis, we introduce three key innovations: (1) PC Tracker, a lightweight infrastructure that efficiently collects high-quality human-computer interaction trajectories with complete cognitive context; (2) a two-stage cognition completion pipeline that transforms raw interaction data into rich cognitive trajectories by completing action semantics and thought processes; and (3) a multi-agent system combining a planning agent for decision-making with a grounding agent for robust visual grounding. Our preliminary experiments in PowerPoint presentation creation reveal that complex digital work capabilities can be achieved with a small amount of high-quality cognitive data - PC Agent, trained on just 133 cognitive trajectories, can handle sophisticated work scenarios involving up to 50 steps across multiple applications. This demonstrates the data efficiency of our approach, highlighting that the key to training capable digital agents lies in collecting human cognitive data. By open-sourcing our complete framework, including the data collection infrastructure and cognition completion methods, we aim to lower the barriers for the research community to develop truly capable digital agents.
ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
Jul 08, 2024Previous open-source large multimodal models (LMMs) have faced several limitations: (1) they often lack native integration, requiring adapters to align visual representations with pre-trained large language models (LLMs); (2) many are restricted to single-modal generation; (3) while some support multimodal generation, they rely on separate diffusion models for visual modeling and generation. To mitigate these limitations, we present Anole, an open, autoregressive, native large multimodal model for interleaved image-text generation. We build Anole from Meta AI's Chameleon, adopting an innovative fine-tuning strategy that is both data-efficient and parameter-efficient. Anole demonstrates high-quality, coherent multimodal generation capabilities. We have open-sourced our model, training framework, and instruction tuning data.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024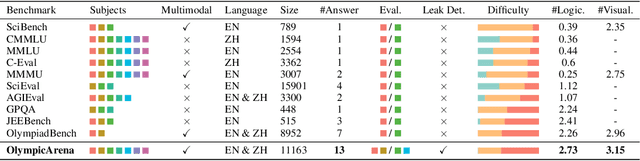
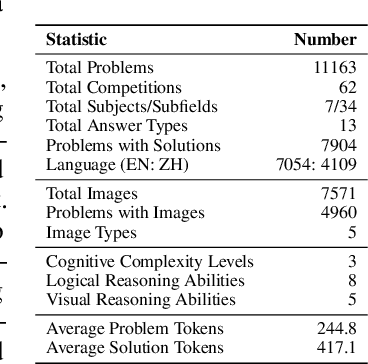
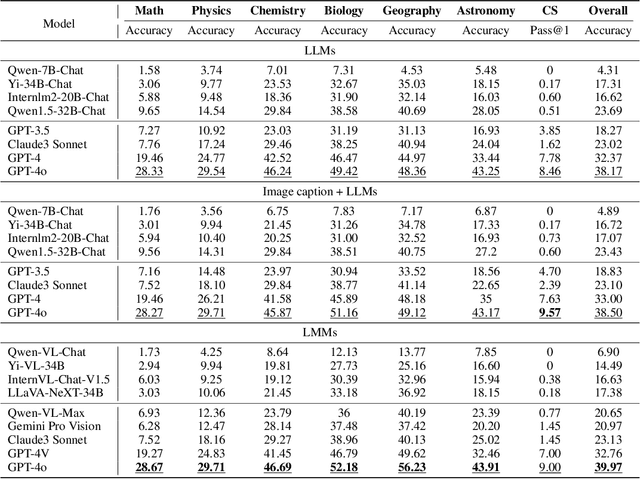
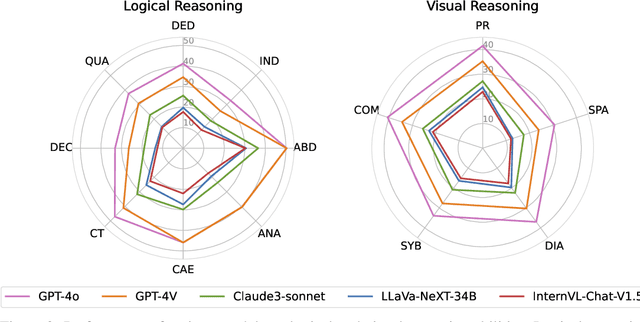
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.