 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinEvo: From Isolated Backtests to Ecological Market Games for Multi-Agent Financial Strategy Evolution
Feb 01, 2026Conventional financial strategy evaluation relies on isolated backtests in static environments. Such evaluations assess each policy independently, overlook correlations and interactions, and fail to explain why strategies ultimately persist or vanish in evolving markets. We shift to an ecological perspective, where trading strategies are modeled as adaptive agents that interact and learn within a shared market. Instead of proposing a new strategy, we present FinEvo, an ecological game formalism for studying the evolutionary dynamics of multi-agent financial strategies. At the individual level, heterogeneous ML-based traders-rule-based, deep learning, reinforcement learning, and large language model (LLM) agents-adapt using signals such as historical prices and external news. At the population level, strategy distributions evolve through three designed mechanisms-selection, innovation, and environmental perturbation-capturing the dynamic forces of real markets. Together, these two layers of adaptation link evolutionary game theory with modern learning dynamics, providing a principled environment for studying strategic behavior. Experiments with external shocks and real-world news streams show that FinEvo is both stable for reproducibility and expressive in revealing context-dependent outcomes. Strategies may dominate, collapse, or form coalitions depending on their competitors-patterns invisible to static backtests. By reframing strategy evaluation as an ecological game formalism, FinEvo provides a unified, mechanism-level protocol for analyzing robustness, adaptation, and emergent dynamics in multi-agent financial markets, and may offer a means to explore the potential impact of macroeconomic policies and financial regulations on price evolution and equilibrium.
Phantom Menace: Exploring and Enhancing the Robustness of VLA Models against Physical Sensor Attacks
Nov 13, 2025Vision-Language-Action (VLA) models revolutionize robotic systems by enabling end-to-end perception-to-action pipelines that integrate multiple sensory modalities, such as visual signals processed by cameras and auditory signals captured by microphones. This multi-modality integration allows VLA models to interpret complex, real-world environments using diverse sensor data streams. Given the fact that VLA-based systems heavily rely on the sensory input, the security of VLA models against physical-world sensor attacks remains critically underexplored. To address this gap, we present the first systematic study of physical sensor attacks against VLAs, quantifying the influence of sensor attacks and investigating the defenses for VLA models. We introduce a novel ``Real-Sim-Real'' framework that automatically simulates physics-based sensor attack vectors, including six attacks targeting cameras and two targeting microphones, and validates them on real robotic systems. Through large-scale evaluations across various VLA architectures and tasks under varying attack parameters, we demonstrate significant vulnerabilities, with susceptibility patterns that reveal critical dependencies on task types and model designs. We further develop an adversarial-training-based defense that enhances VLA robustness against out-of-distribution physical perturbations caused by sensor attacks while preserving model performance. Our findings expose an urgent need for standardized robustness benchmarks and mitigation strategies to secure VLA deployments in safety-critical environments.
FinHEAR: Human Expertise and Adaptive Risk-Aware Temporal Reasoning for Financial Decision-Making
Jun 10, 2025Financial decision-making presents unique challenges for language models, demanding temporal reasoning, adaptive risk assessment, and responsiveness to dynamic events. While large language models (LLMs) show strong general reasoning capabilities, they often fail to capture behavioral patterns central to human financial decisions-such as expert reliance under information asymmetry, loss-averse sensitivity, and feedback-driven temporal adjustment. We propose FinHEAR, a multi-agent framework for Human Expertise and Adaptive Risk-aware reasoning. FinHEAR orchestrates specialized LLM-based agents to analyze historical trends, interpret current events, and retrieve expert-informed precedents within an event-centric pipeline. Grounded in behavioral economics, it incorporates expert-guided retrieval, confidence-adjusted position sizing, and outcome-based refinement to enhance interpretability and robustness. Empirical results on curated financial datasets show that FinHEAR consistently outperforms strong baselines across trend prediction and trading tasks, achieving higher accuracy and better risk-adjusted returns.
AI2Agent: An End-to-End Framework for Deploying AI Projects as Autonomous Agents
Mar 31, 2025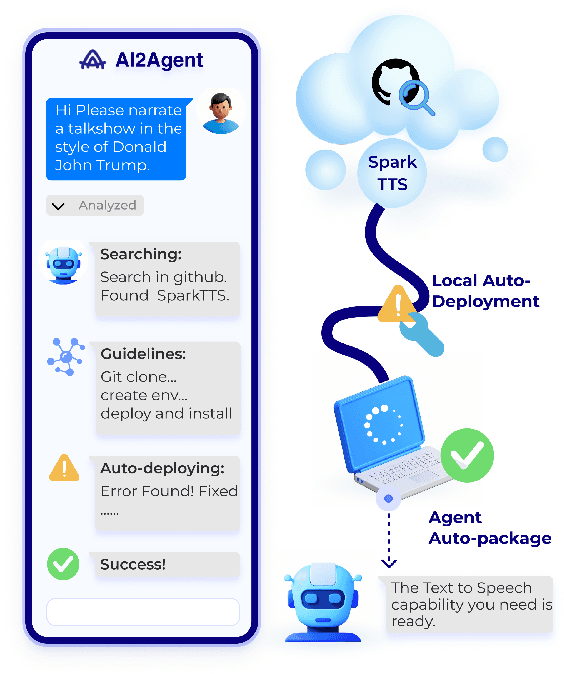
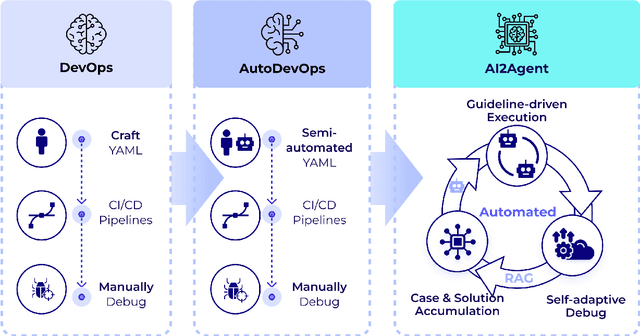
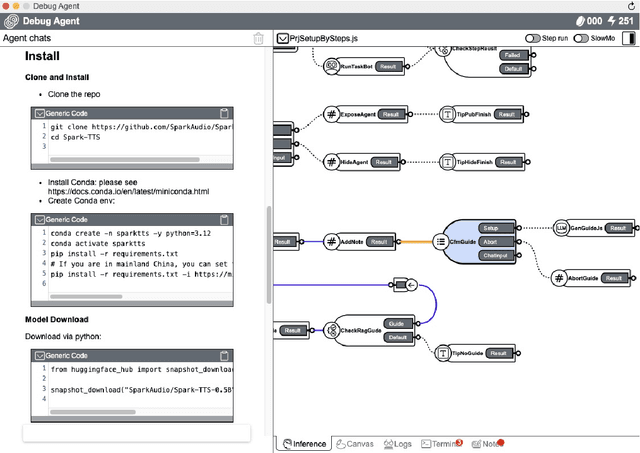
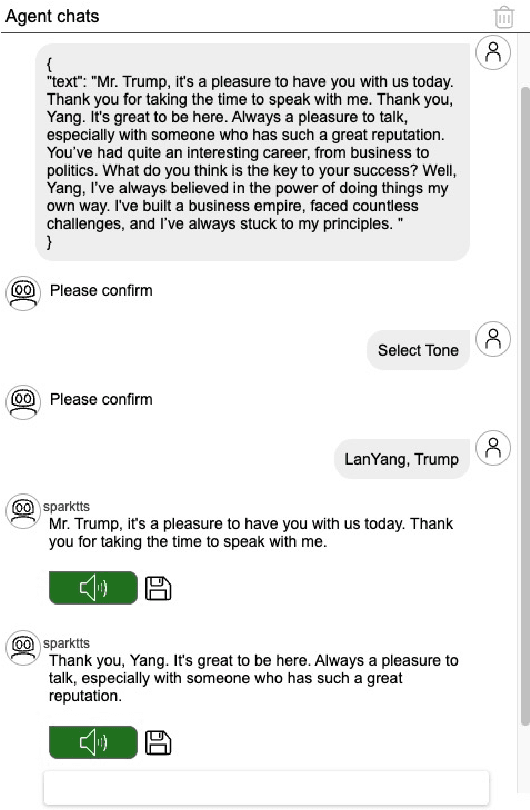
As AI technology advances, it is driving innovation across industries, increasing the demand for scalable AI project deployment. However, deployment remains a critical challenge due to complex environment configurations, dependency conflicts, cross-platform adaptation, and debugging difficulties, which hinder automation and adoption. This paper introduces AI2Agent, an end-to-end framework that automates AI project deployment through guideline-driven execution, self-adaptive debugging, and case \& solution accumulation. AI2Agent dynamically analyzes deployment challenges, learns from past cases, and iteratively refines its approach, significantly reducing human intervention. To evaluate its effectiveness, we conducted experiments on 30 AI deployment cases, covering TTS, text-to-image generation, image editing, and other AI applications. Results show that AI2Agent significantly reduces deployment time and improves success rates. The code and demo video are now publicly accessible.
An Effective Dynamic Gradient Calibration Method for Continual Learning
Jul 30, 2024Continual learning (CL) is a fundamental topic in machine learning, where the goal is to train a model with continuously incoming data and tasks. Due to the memory limit, we cannot store all the historical data, and therefore confront the ``catastrophic forgetting'' problem, i.e., the performance on the previous tasks can substantially decrease because of the missing information in the latter period. Though a number of elegant methods have been proposed, the catastrophic forgetting phenomenon still cannot be well avoided in practice. In this paper, we study the problem from the gradient perspective, where our aim is to develop an effective algorithm to calibrate the gradient in each updating step of the model; namely, our goal is to guide the model to be updated in the right direction under the situation that a large amount of historical data are unavailable. Our idea is partly inspired by the seminal stochastic variance reduction methods (e.g., SVRG and SAGA) for reducing the variance of gradient estimation in stochastic gradient descent algorithms. Another benefit is that our approach can be used as a general tool, which is able to be incorporated with several existing popular CL methods to achieve better performance. We also conduct a set of experiments on several benchmark datasets to evaluate the performance in practice.
AI2Apps: A Visual IDE for Building LLM-based AI Agent Applications
Apr 07, 2024



We introduce AI2Apps, a Visual Integrated Development Environment (Visual IDE) with full-cycle capabilities that accelerates developers to build deployable LLM-based AI agent Applications. This Visual IDE prioritizes both the Integrity of its development tools and the Visuality of its components, ensuring a smooth and efficient building experience.On one hand, AI2Apps integrates a comprehensive development toolkit ranging from a prototyping canvas and AI-assisted code editor to agent debugger, management system, and deployment tools all within a web-based graphical user interface. On the other hand, AI2Apps visualizes reusable front-end and back-end code as intuitive drag-and-drop components. Furthermore, a plugin system named AI2Apps Extension (AAE) is designed for Extensibility, showcasing how a new plugin with 20 components enables web agent to mimic human-like browsing behavior. Our case study demonstrates substantial efficiency improvements, with AI2Apps reducing token consumption and API calls when debugging a specific sophisticated multimodal agent by approximately 90% and 80%, respectively. The AI2Apps, including an online demo, open-source code, and a screencast video, is now publicly accessible.
Coresets for Relational Data and The Applications
Oct 09, 2022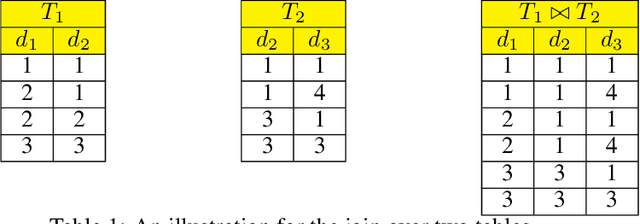
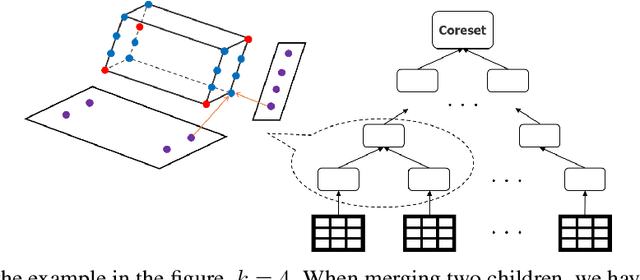
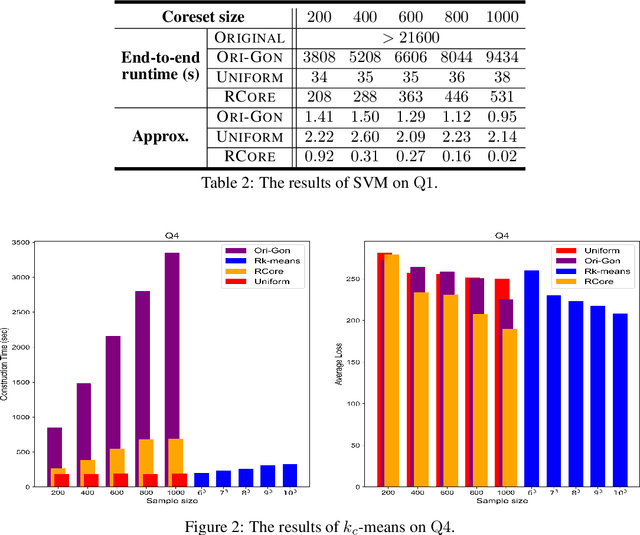
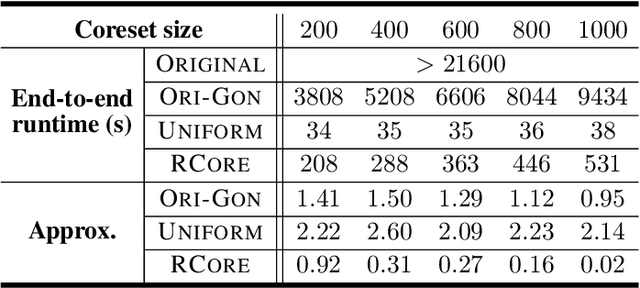
A coreset is a small set that can approximately preserve the structure of the original input data set. Therefore we can run our algorithm on a coreset so as to reduce the total computational complexity. Conventional coreset techniques assume that the input data set is available to process explicitly. However, this assumption may not hold in real-world scenarios. In this paper, we consider the problem of coresets construction over relational data. Namely, the data is decoupled into several relational tables, and it could be very expensive to directly materialize the data matrix by joining the tables. We propose a novel approach called ``aggregation tree with pseudo-cube'' that can build a coreset from bottom to up. Moreover, our approach can neatly circumvent several troublesome issues of relational learning problems [Khamis et al., PODS 2019]. Under some mild assumptions, we show that our coreset approach can be applied for the machine learning tasks, such as clustering, logistic regression and SVM.