 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember the Decision, Not the Description: A Rate-Distortion Framework for Agent Memory
May 11, 2026Long-horizon language agents must operate under limited runtime memory, yet existing memory mechanisms often organize experience around descriptive criteria such as relevance, salience, or summary quality. For an agent, however, memory is valuable not because it faithfully describes the past, but because it preserves the distinctions between histories that must remain separated under a fixed budget to support good decisions. We cast this as a decision-centric rate-distortion problem, measuring memory quality by the loss in achievable decision quality induced by compression. This yields an exact forgetting boundary for what can be safely forgotten, and a memory-distortion frontier characterizing the optimal tradeoff between memory budget and decision quality. Motivated by this decision-centric view of memory, we propose DeMem, an online memory learner that refines its partition only when data certify that a shared state would induce decision conflict, and prove near-minimax regret guarantees. On both controlled synthetic diagnostics and long-horizon conversational benchmarks, DeMem yields consistent gains under the same runtime budget, supporting the principle that memory should preserve the distinctions that matter for decisions, not descriptions.
CoTEvol: Self-Evolving Chain-of-Thoughts for Data Synthesis in Mathematical Reasoning
Apr 16, 2026Large Language Models (LLMs) exhibit strong mathematical reasoning when trained on high-quality Chain-of-Thought (CoT) that articulates intermediate steps, yet costly CoT curation hinders further progress. While existing remedies such as distillation from stronger LLMs and self-synthesis based on test-time search alleviate this issue, they often suffer from diminishing returns or high computing overhead.In this work, we propose CoTEvol, a genetic evolutionary framework that casts CoT generation as a population-based search over reasoning trajectories.Candidate trajectories are iteratively evolved through reflective global crossover at the trajectory level and local mutation guided by uncertainty at the step level, enabling holistic recombination and fine-grained refinement. Lightweight, task-aware fitness functions are designed to guide the evolutionary process toward accurate and diverse reasoning. Empirically, CoTEvol improves correct-CoT synthesis success by over 30% and enhances structural diversity, with markedly improved efficiency. LLMs trained on these evolutionary CoT data achieve an average gain of 6.6% across eight math benchmarks, outperforming previous distillation and self-synthesis approaches. These results underscore the promise of evolutionary CoT synthesis as a scalable and effective method for mathematical reasoning tasks.
Agent^2 RL-Bench: Can LLM Agents Engineer Agentic RL Post-Training?
Apr 12, 2026We introduce Agent^2 RL-Bench, a benchmark for evaluating agentic RL post-training -- whether LLM agents can autonomously design, implement, and run complete RL pipelines that improve foundation models. This capability is important because RL post-training increasingly drives model alignment and specialization, yet existing benchmarks remain largely static: supervised fine-tuning alone yields strong results, leaving interactive RL engineering untested. Agent^2 RL-Bench addresses this with six tasks across three levels -- from static rule-based training to closed-loop online RL with trajectory collection -- each adding a structural requirement that prior levels do not impose. The benchmark provides isolated workspaces with a grading API, runtime instrumentation that records every submission and code revision, and automated post-hoc analysis that generates structured run reports, enabling the first automated diagnostic of agent-driven post-training behavior. Across multiple agent stacks spanning five agent systems and six driver LLMs, we find that agents achieve striking interactive gains -- on ALFWorld, an RL-only agent improves from 5.97 to 93.28 via SFT warm-up and GRPO with online rollouts -- yet make only marginal progress on others (DeepSearchQA: +2.75 within evaluation noise), and that driver choice has a large effect on interactive tasks -- within the same scaffold, switching drivers changes interactive improvement from near-zero to +78pp. More broadly, the benchmark reveals that supervised pipelines dominate agent-driven post-training under fixed budgets, with online RL succeeding as the final best route only on ALFWorld. Code is available at https://github.com/microsoft/RD-Agent/tree/main/rdagent/scenarios/rl/autorl_bench.
FT-Dojo: Towards Autonomous LLM Fine-Tuning with Language Agents
Mar 02, 2026Fine-tuning large language models for vertical domains remains a labor-intensive and expensive process, requiring domain experts to curate data, configure training, and iteratively diagnose model behavior. Despite growing interest in autonomous machine learning, no prior work has tackled end-to-end LLM fine-tuning with agents. Can LLM-based agents automate this complete process? We frame this as a substantially open problem: agents must navigate an open-ended search space spanning data curation from diverse data sources, processing with complex tools, building a training pipeline, and iteratively refining their approach based on evaluation outcomes in rapidly growing logs--an overall scenario far more intricate than existing benchmarks. To study this question, we introduce FT-Dojo, an interactive environment comprising 13 tasks across 5 domains. We further develop FT-Agent, an autonomous system that mirrors human experts by leveraging evaluation-driven feedback to iteratively diagnose failures and refine fine-tuning strategies. Experiments on FT-Dojo demonstrate that purpose-built fine-tuning agents significantly outperform general-purpose alternatives, with FT-Agent achieving the best performance on 10 out of 13 tasks across all five domains. Ablations show that the approach generalizes effectively to 3B models, with additional insights on data scaling trade-offs and backbone sensitivity. Case analyses reveal that agents can recover from failures through cumulative learning from historical experience, while also exposing fundamental limitations in causal reasoning--highlighting both the promise and current boundaries of autonomous LLM fine-tuning.
High-Resolution Underwater Camouflaged Object Detection: GBU-UCOD Dataset and Topology-Aware and Frequency-Decoupled Networks
Feb 03, 2026Underwater Camouflaged Object Detection (UCOD) is a challenging task due to the extreme visual similarity between targets and backgrounds across varying marine depths. Existing methods often struggle with topological fragmentation of slender creatures in the deep sea and the subtle feature extraction of transparent organisms. In this paper, we propose DeepTopo-Net, a novel framework that integrates topology-aware modeling with frequency-decoupled perception. To address physical degradation, we design the Water-Conditioned Adaptive Perceptor (WCAP), which employs Riemannian metric tensors to dynamically deform convolutional sampling fields. Furthermore, the Abyssal-Topology Refinement Module (ATRM) is developed to maintain the structural connectivity of spindly targets through skeletal priors. Specifically, we first introduce GBU-UCOD, the first high-resolution (2K) benchmark tailored for marine vertical zonation, filling the data gap for hadal and abyssal zones. Extensive experiments on MAS3K, RMAS, and our proposed GBU-UCOD datasets demonstrate that DeepTopo-Net achieves state-of-the-art performance, particularly in preserving the morphological integrity of complex underwater patterns. The datasets and codes will be released at https://github.com/Wuwenji18/GBU-UCOD.
Contrastive Spectral Rectification: Test-Time Defense towards Zero-shot Adversarial Robustness of CLIP
Jan 27, 2026Vision-language models (VLMs) such as CLIP have demonstrated remarkable zero-shot generalization, yet remain highly vulnerable to adversarial examples (AEs). While test-time defenses are promising, existing methods fail to provide sufficient robustness against strong attacks and are often hampered by high inference latency and task-specific applicability. To address these limitations, we start by investigating the intrinsic properties of AEs, which reveals that AEs exhibit severe feature inconsistency under progressive frequency attenuation. We further attribute this to the model's inherent spectral bias. Leveraging this insight, we propose an efficient test-time defense named Contrastive Spectral Rectification (CSR). CSR optimizes a rectification perturbation to realign the input with the natural manifold under a spectral-guided contrastive objective, which is applied input-adaptively. Extensive experiments across 16 classification benchmarks demonstrate that CSR outperforms the SOTA by an average of 18.1% against strong AutoAttack with modest inference overhead. Furthermore, CSR exhibits broad applicability across diverse visual tasks. Code is available at https://github.com/Summu77/CSR.
LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
Dec 30, 2025The transition from static Large Language Models (LLMs) to self-improving agents is hindered by the lack of structured reasoning in traditional evolutionary approaches. Existing methods often struggle with premature convergence and inefficient exploration in high-dimensional code spaces. To address these challenges, we introduce LoongFlow, a self-evolving agent framework that achieves state-of-the-art solution quality with significantly reduced computational costs. Unlike "blind" mutation operators, LoongFlow integrates LLMs into a cognitive "Plan-Execute-Summarize" (PES) paradigm, effectively mapping the evolutionary search to a reasoning-heavy process. To sustain long-term architectural coherence, we incorporate a hybrid evolutionary memory system. By synergizing Multi-Island models with MAP-Elites and adaptive Boltzmann selection, this system theoretically balances the exploration-exploitation trade-off, maintaining diverse behavioral niches to prevent optimization stagnation. We instantiate LoongFlow with a General Agent for algorithmic discovery and an ML Agent for pipeline optimization. Extensive evaluations on the AlphaEvolve benchmark and Kaggle competitions demonstrate that LoongFlow outperforms leading baselines (e.g., OpenEvolve, ShinkaEvolve) by up to 60% in evolutionary efficiency while discovering superior solutions. LoongFlow marks a substantial step forward in autonomous scientific discovery, enabling the generation of expert-level solutions with reduced computational overhead.
RobustSora: De-Watermarked Benchmark for Robust AI-Generated Video Detection
Dec 11, 2025The proliferation of AI-generated video technologies poses challenges to information integrity. While recent benchmarks advance AIGC video detection, they overlook a critical factor: many state-of-the-art generative models embed digital watermarks in outputs, and detectors may partially rely on these patterns. To evaluate this influence, we present RobustSora, the benchmark designed to assess watermark robustness in AIGC video detection. We systematically construct a dataset of 6,500 videos comprising four types: Authentic-Clean (A-C), Authentic-Spoofed with fake watermarks (A-S), Generated-Watermarked (G-W), and Generated-DeWatermarked (G-DeW). Our benchmark introduces two evaluation tasks: Task-I tests performance on watermark-removed AI videos, while Task-II assesses false alarm rates on authentic videos with fake watermarks. Experiments with ten models spanning specialized AIGC detectors, transformer architectures, and MLLM approaches reveal performance variations of 2-8pp under watermark manipulation. Transformer-based models show consistent moderate dependency (6-8pp), while MLLMs exhibit diverse patterns (2-8pp). These findings indicate partial watermark dependency and highlight the need for watermark-aware training strategies. RobustSora provides essential tools to advance robust AIGC detection research.
Iterative Distortion Cancellation Algorithms for Single-Sideband Systems
Aug 12, 2025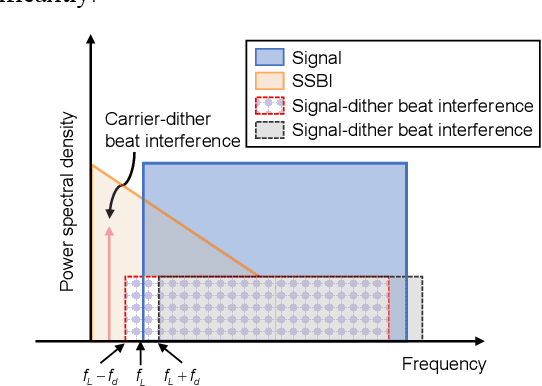
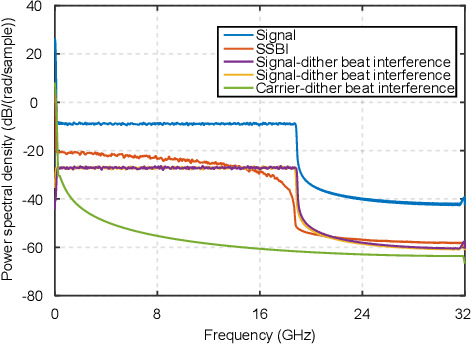
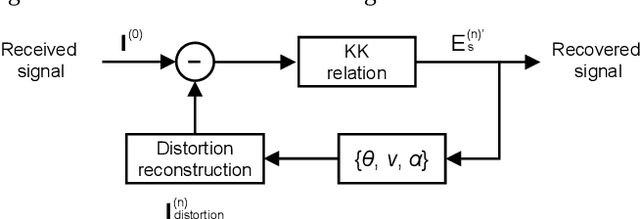
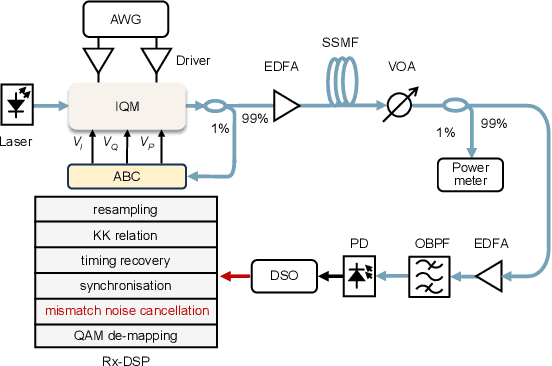
We propose an iterative distortion cancellation algorithm to digitally mitigate the impact of double-sideband dither signal amplitude from the automatic bias control module on Kramers-Kronig receivers without modifying physical layer structures. The algorithm utilizes the KK relation for initial signal decisions and reconstructs the distortion caused by dither signals. Experimental tests in back-to-back showed it improved tolerance to dither amplitudes up to 10% V{\pi}. For 80-km fiber transmission, the algorithm increased the receiver sensitivity by more than 1 dB, confirming the effectiveness of the proposed distortion cancellation method.
Test-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.