 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPDocBench-Parse: Benchmarking Practical Multi-page Document Parsing
May 21, 2026Document parsing converts visually rich documents into machine-readable structured representations, forming a crucial foundation for information systems. Although many benchmarks have been proposed for document parsing, they remain inadequate for realistic scenarios. Existing benchmarks either focus on specific tasks or assess only single-page, text-centric settings, making them insufficient for practical multi-page parsing. Moreover, they lack fine-grained evaluation of semantic continuity, hierarchical structure recovery, and visual content preservation. To address these gaps, we propose MPDocBench-Parse, a benchmark for multi-page document parsing in real-world applications. It contains 433 manually annotated documents with 3,246 pages, covering 15 document types in English and Chinese, with diverse layout styles, and supports document-level end-to-end evaluation. We further design a comprehensive protocol for content fidelity and logical structure, covering text, table, and formula recognition, truncated text and table merging, figure extraction, reading order, and heading hierarchy recovery. Experiments show that, while existing models perform well on basic text extraction, they still suffer clear limitations in semantic continuity integration, visual content parsing, and hierarchical structure recovery. MPDocBench-Parse provides a unified foundation for advancing document parsing toward more realistic scenarios.
A Comparative Evaluation of AI Agent Security Guardrails
Apr 27, 2026This report presents a comparative evaluation of DKnownAI Guard in AI agent security scenarios, benchmarked against three competing products: AWS Bedrock Guardrails, Azure Content Safety, and Lakera Guard. Using human annotation as the ground truth, we assess each guardrail's ability to detect two categories of risks: threats to the agent itself (e.g., instruction override, indirect injection, tool abuse) and requests intended to elicit harmful content (e.g., hate speech, pornography, violence). Evaluation results demonstrate that DKnownAI Guard achieves the highest recall rate at 96.5\% and ranks first in true negative rate (TNR) at 90.4\%, delivering the best overall performance among all evaluated guardrails.
Test-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
A Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions
Dec 12, 2024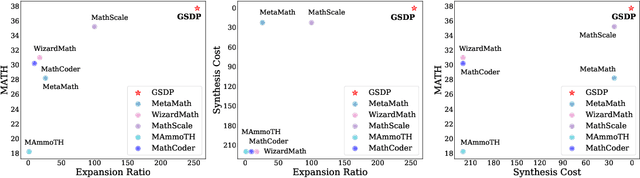
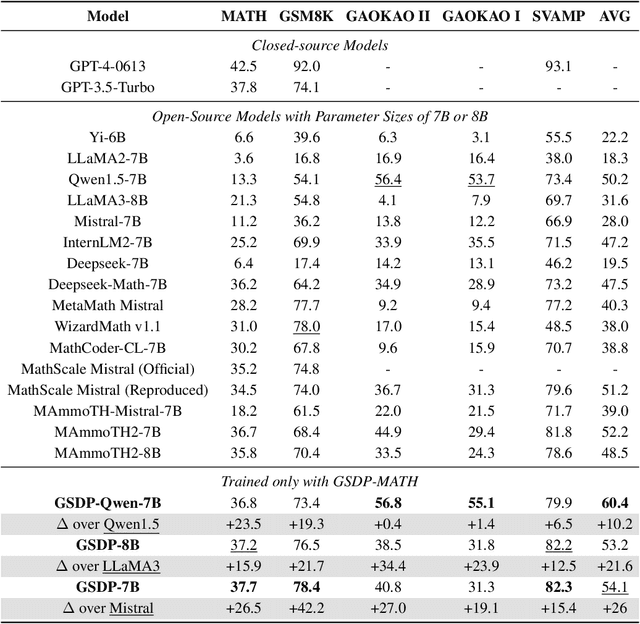
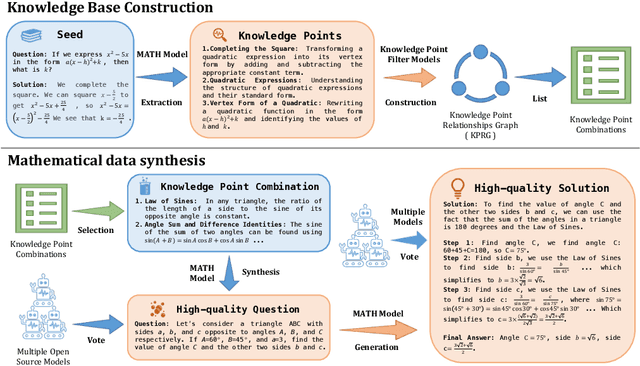
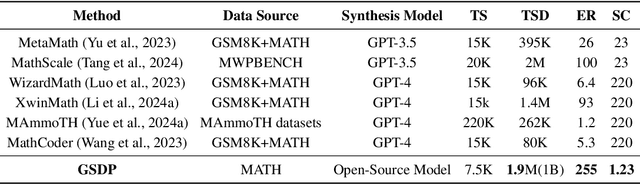
Synthesizing high-quality reasoning data for continual training has been proven to be effective in enhancing the performance of Large Language Models (LLMs). However, previous synthetic approaches struggle to easily scale up data and incur high costs in the pursuit of high quality. In this paper, we propose the Graph-based Synthetic Data Pipeline (GSDP), an economical and scalable framework for high-quality reasoning data synthesis. Inspired by knowledge graphs, we extracted knowledge points from seed data and constructed a knowledge point relationships graph to explore their interconnections. By exploring the implicit relationships among knowledge, our method achieves $\times$255 data expansion. Furthermore, GSDP led by open-source models, achieves synthesis quality comparable to GPT-4-0613 while maintaining $\times$100 lower costs. To tackle the most challenging mathematical reasoning task, we present the GSDP-MATH dataset comprising over 1.91 million pairs of math problems and answers. After fine-tuning on GSDP-MATH, GSDP-7B based on Mistral-7B achieves 37.7% accuracy on MATH and 78.4% on GSM8K, demonstrating the effectiveness of our method. The dataset and models trained in this paper will be available.
Self-Supervised Pre-training with Symmetric Superimposition Modeling for Scene Text Recognition
May 11, 2024



In text recognition, self-supervised pre-training emerges as a good solution to reduce dependence on expansive annotated real data. Previous studies primarily focus on local visual representation by leveraging mask image modeling or sequence contrastive learning. However, they omit modeling the linguistic information in text images, which is crucial for recognizing text. To simultaneously capture local character features and linguistic information in visual space, we propose Symmetric Superimposition Modeling (SSM). The objective of SSM is to reconstruct the direction-specific pixel and feature signals from the symmetrically superimposed input. Specifically, we add the original image with its inverted views to create the symmetrically superimposed inputs. At the pixel level, we reconstruct the original and inverted images to capture character shapes and texture-level linguistic context. At the feature level, we reconstruct the feature of the same original image and inverted image with different augmentations to model the semantic-level linguistic context and the local character discrimination. In our design, we disrupt the character shape and linguistic rules. Consequently, the dual-level reconstruction facilitates understanding character shapes and linguistic information from the perspective of visual texture and feature semantics. Experiments on various text recognition benchmarks demonstrate the effectiveness and generality of SSM, with 4.1% average performance gains and 86.6% new state-of-the-art average word accuracy on Union14M benchmarks. The code is available at https://github.com/FaltingsA/SSM.
Symmetrical Linguistic Feature Distillation with CLIP for Scene Text Recognition
Oct 10, 2023In this paper, we explore the potential of the Contrastive Language-Image Pretraining (CLIP) model in scene text recognition (STR), and establish a novel Symmetrical Linguistic Feature Distillation framework (named CLIP-OCR) to leverage both visual and linguistic knowledge in CLIP. Different from previous CLIP-based methods mainly considering feature generalization on visual encoding, we propose a symmetrical distillation strategy (SDS) that further captures the linguistic knowledge in the CLIP text encoder. By cascading the CLIP image encoder with the reversed CLIP text encoder, a symmetrical structure is built with an image-to-text feature flow that covers not only visual but also linguistic information for distillation.Benefiting from the natural alignment in CLIP, such guidance flow provides a progressive optimization objective from vision to language, which can supervise the STR feature forwarding process layer-by-layer.Besides, a new Linguistic Consistency Loss (LCL) is proposed to enhance the linguistic capability by considering second-order statistics during the optimization. Overall, CLIP-OCR is the first to design a smooth transition between image and text for the STR task.Extensive experiments demonstrate the effectiveness of CLIP-OCR with 93.8% average accuracy on six popular STR benchmarks.Code will be available at https://github.com/wzx99/CLIPOCR.
VisKoP: Visual Knowledge oriented Programming for Interactive Knowledge Base Question Answering
Jul 06, 2023We present Visual Knowledge oriented Programming platform (VisKoP), a knowledge base question answering (KBQA) system that integrates human into the loop to edit and debug the knowledge base (KB) queries. VisKoP not only provides a neural program induction module, which converts natural language questions into knowledge oriented program language (KoPL), but also maps KoPL programs into graphical elements. KoPL programs can be edited with simple graphical operators, such as dragging to add knowledge operators and slot filling to designate operator arguments. Moreover, VisKoP provides auto-completion for its knowledge base schema and users can easily debug the KoPL program by checking its intermediate results. To facilitate the practical KBQA on a million-entity-level KB, we design a highly efficient KoPL execution engine for the back-end. Experiment results show that VisKoP is highly efficient and user interaction can fix a large portion of wrong KoPL programs to acquire the correct answer. The VisKoP online demo https://demoviskop.xlore.cn (Stable release of this paper) and https://viskop.xlore.cn (Beta release with new features), highly efficient KoPL engine https://pypi.org/project/kopl-engine, and screencast video https://youtu.be/zAbJtxFPTXo are now publicly available.
Functional sufficient dimension reduction through information maximization with application to classification
May 18, 2023Considering the case where the response variable is a categorical variable and the predictor is a random function, two novel functional sufficient dimensional reduction (FSDR) methods are proposed based on mutual information and square loss mutual information. Compared to the classical FSDR methods, such as functional sliced inverse regression and functional sliced average variance estimation, the proposed methods are appealing because they are capable of estimating multiple effective dimension reduction directions in the case of a relatively small number of categories, especially for the binary response. Moreover, the proposed methods do not require the restrictive linear conditional mean assumption and the constant covariance assumption. They avoid the inverse problem of the covariance operator which is often encountered in the functional sufficient dimension reduction. The functional principal component analysis with truncation be used as a regularization mechanism. Under some mild conditions, the statistical consistency of the proposed methods is established. It is demonstrated that the two methods are competitive compared with some existing FSDR methods by simulations and real data analyses.
Linguistic More: Taking a Further Step toward Efficient and Accurate Scene Text Recognition
May 10, 2023Vision model have gained increasing attention due to their simplicity and efficiency in Scene Text Recognition (STR) task. However, due to lacking the perception of linguistic knowledge and information, recent vision models suffer from two problems: (1) the pure vision-based query results in attention drift, which usually causes poor recognition and is summarized as linguistic insensitive drift (LID) problem in this paper. (2) the visual feature is suboptimal for the recognition in some vision-missing cases (e.g. occlusion, etc.). To address these issues, we propose a $\textbf{L}$inguistic $\textbf{P}$erception $\textbf{V}$ision model (LPV), which explores the linguistic capability of vision model for accurate text recognition. To alleviate the LID problem, we introduce a Cascade Position Attention (CPA) mechanism that obtains high-quality and accurate attention maps through step-wise optimization and linguistic information mining. Furthermore, a Global Linguistic Reconstruction Module (GLRM) is proposed to improve the representation of visual features by perceiving the linguistic information in the visual space, which gradually converts visual features into semantically rich ones during the cascade process. Different from previous methods, our method obtains SOTA results while keeping low complexity (92.4% accuracy with only 8.11M parameters). Code is available at https://github.com/CyrilSterling/LPV.
Federated Covariate Shift Adaptation for Missing Target Output Values
Feb 28, 2023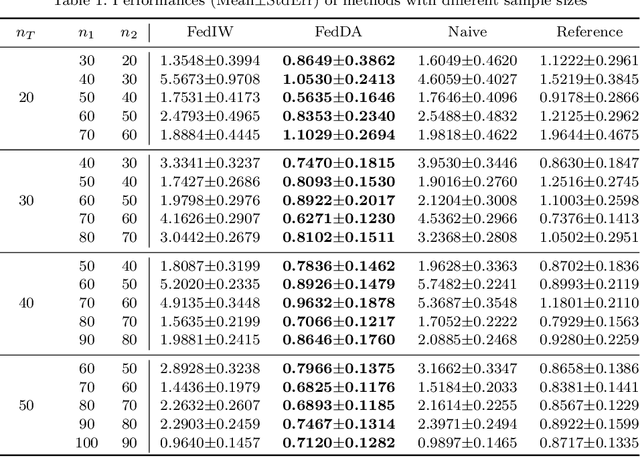
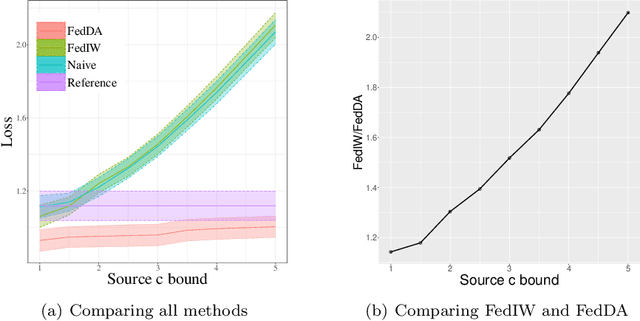
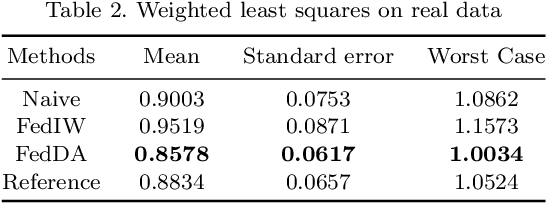
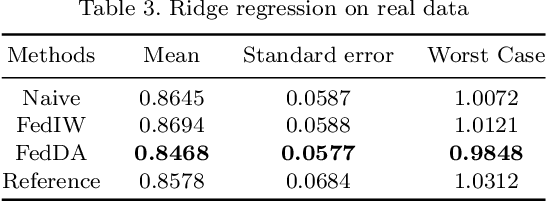
The most recent multi-source covariate shift algorithm is an efficient hyperparameter optimization algorithm for missing target output. In this paper, we extend this algorithm to the framework of federated learning. For data islands in federated learning and covariate shift adaptation, we propose the federated domain adaptation estimate of the target risk which is asymptotically unbiased with a desirable asymptotic variance property. We construct a weighted model for the target task and propose the federated covariate shift adaptation algorithm which works preferably in our setting. The efficacy of our method is justified both theoretically and empirically.