 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions
Paper and Code
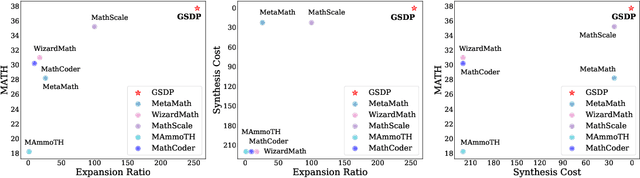
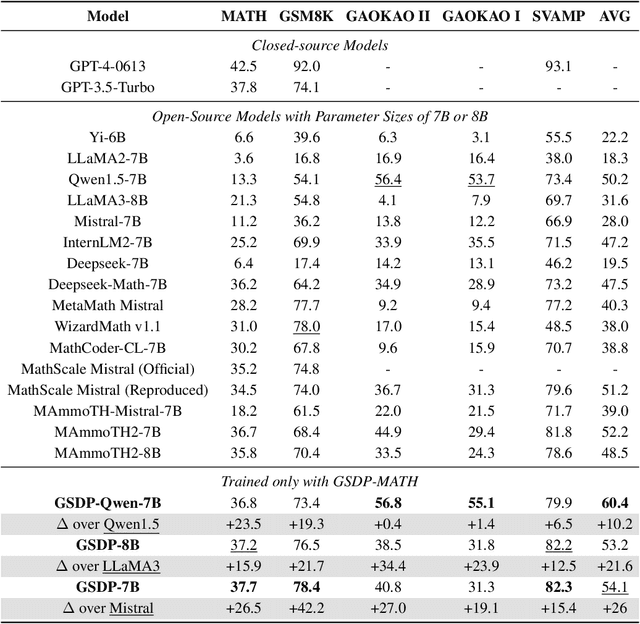
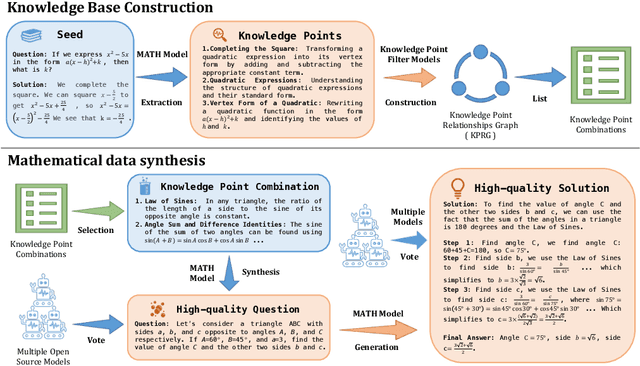
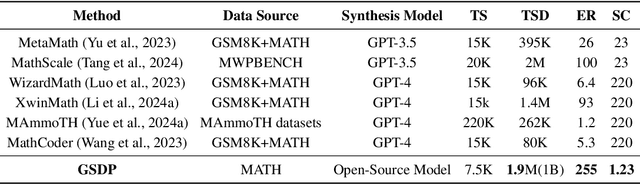
Synthesizing high-quality reasoning data for continual training has been proven to be effective in enhancing the performance of Large Language Models (LLMs). However, previous synthetic approaches struggle to easily scale up data and incur high costs in the pursuit of high quality. In this paper, we propose the Graph-based Synthetic Data Pipeline (GSDP), an economical and scalable framework for high-quality reasoning data synthesis. Inspired by knowledge graphs, we extracted knowledge points from seed data and constructed a knowledge point relationships graph to explore their interconnections. By exploring the implicit relationships among knowledge, our method achieves $\times$255 data expansion. Furthermore, GSDP led by open-source models, achieves synthesis quality comparable to GPT-4-0613 while maintaining $\times$100 lower costs. To tackle the most challenging mathematical reasoning task, we present the GSDP-MATH dataset comprising over 1.91 million pairs of math problems and answers. After fine-tuning on GSDP-MATH, GSDP-7B based on Mistral-7B achieves 37.7% accuracy on MATH and 78.4% on GSM8K, demonstrating the effectiveness of our method. The dataset and models trained in this paper will be available.