 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
Apr 01, 2026Traditional scientific discovery relies on an iterative hypothesise-experiment-refine cycle that has driven progress for centuries, but its intuitive, ad-hoc implementation often wastes resources, yields inefficient designs, and misses critical insights. This tutorial presents Bayesian Optimisation (BO), a principled probability-driven framework that formalises and automates this core scientific cycle. BO uses surrogate models (e.g., Gaussian processes) to model empirical observations as evolving hypotheses, and acquisition functions to guide experiment selection, balancing exploitation of known knowledge and exploration of uncharted domains to eliminate guesswork and manual trial-and-error. We first frame scientific discovery as an optimisation problem, then unpack BO's core components, end-to-end workflows, and real-world efficacy via case studies in catalysis, materials science, organic synthesis, and molecule discovery. We also cover critical technical extensions for scientific applications, including batched experimentation, heteroscedasticity, contextual optimisation, and human-in-the-loop integration. Tailored for a broad audience, this tutorial bridges AI advances in BO with practical natural science applications, offering tiered content to empower cross-disciplinary researchers to design more efficient experiments and accelerate principled scientific discovery.
SpaceVLLM: Endowing Multimodal Large Language Model with Spatio-Temporal Video Grounding Capability
Mar 18, 2025

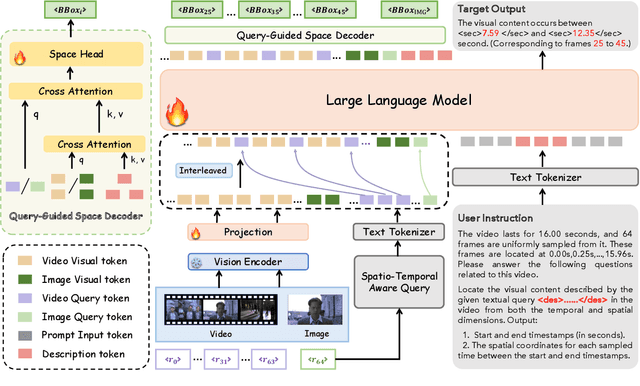
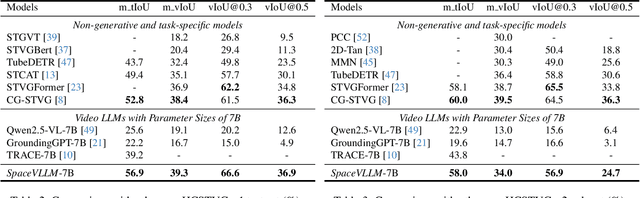
Multimodal large language models (MLLMs) have made remarkable progress in either temporal or spatial localization. However, they struggle to perform spatio-temporal video grounding. This limitation stems from two major challenges. Firstly, it is difficult to extract accurate spatio-temporal information of each frame in the video. Secondly, the substantial number of visual tokens makes it challenging to precisely map visual tokens of each frame to their corresponding spatial coordinates. To address these issues, we introduce SpaceVLLM, a MLLM endowed with spatio-temporal video grounding capability. Specifically, we adopt a set of interleaved Spatio-Temporal Aware Queries to capture temporal perception and dynamic spatial information. Moreover, we propose a Query-Guided Space Decoder to establish a corresponding connection between the queries and spatial coordinates. Additionally, due to the lack of spatio-temporal datasets, we construct the Unified Spatio-Temporal Grounding (Uni-STG) dataset, comprising 480K instances across three tasks. This dataset fully exploits the potential of MLLM to simultaneously facilitate localization in both temporal and spatial dimensions. Extensive experiments demonstrate that SpaceVLLM achieves the state-of-the-art performance across 11 benchmarks covering temporal, spatial, spatio-temporal and video understanding tasks, highlighting the effectiveness of our approach. Our code, datasets and model will be released.
A Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions
Dec 12, 2024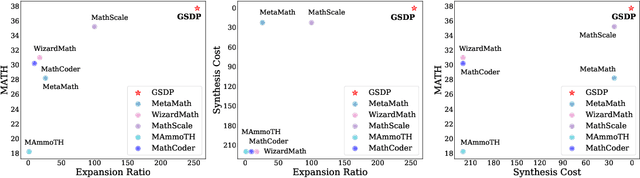
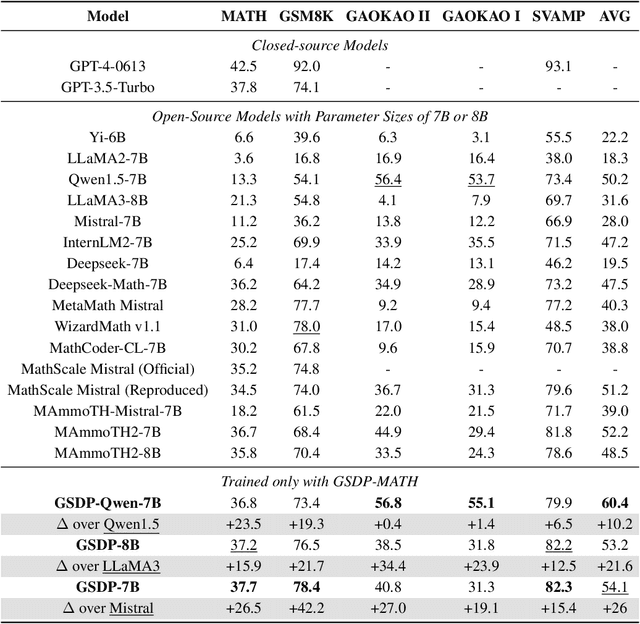
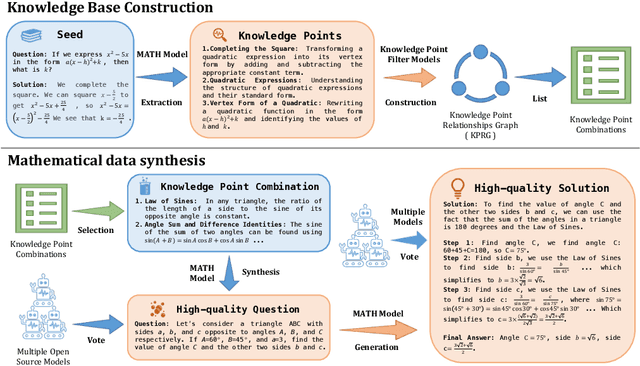
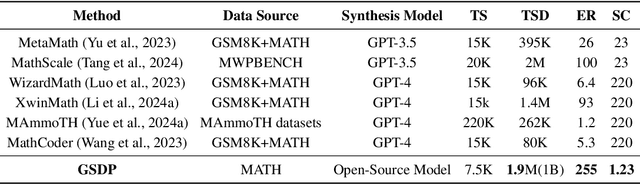
Synthesizing high-quality reasoning data for continual training has been proven to be effective in enhancing the performance of Large Language Models (LLMs). However, previous synthetic approaches struggle to easily scale up data and incur high costs in the pursuit of high quality. In this paper, we propose the Graph-based Synthetic Data Pipeline (GSDP), an economical and scalable framework for high-quality reasoning data synthesis. Inspired by knowledge graphs, we extracted knowledge points from seed data and constructed a knowledge point relationships graph to explore their interconnections. By exploring the implicit relationships among knowledge, our method achieves $\times$255 data expansion. Furthermore, GSDP led by open-source models, achieves synthesis quality comparable to GPT-4-0613 while maintaining $\times$100 lower costs. To tackle the most challenging mathematical reasoning task, we present the GSDP-MATH dataset comprising over 1.91 million pairs of math problems and answers. After fine-tuning on GSDP-MATH, GSDP-7B based on Mistral-7B achieves 37.7% accuracy on MATH and 78.4% on GSM8K, demonstrating the effectiveness of our method. The dataset and models trained in this paper will be available.