 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
A Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions
Dec 12, 2024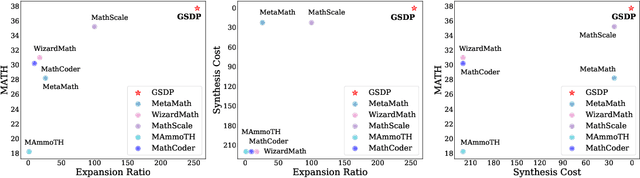
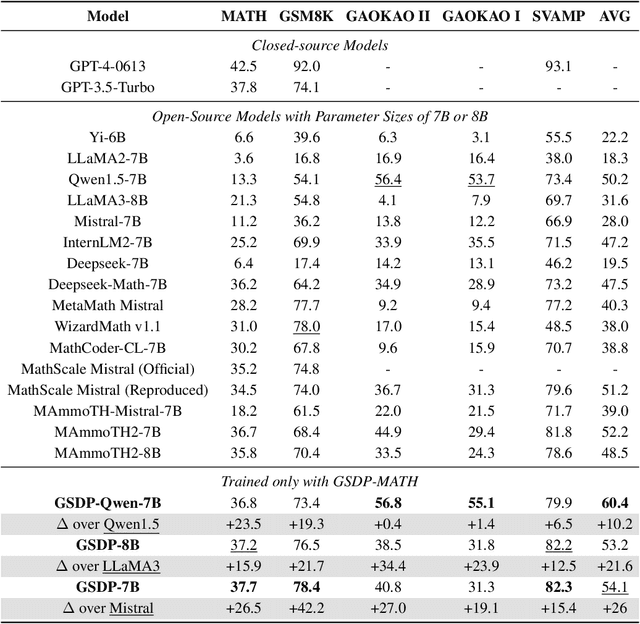
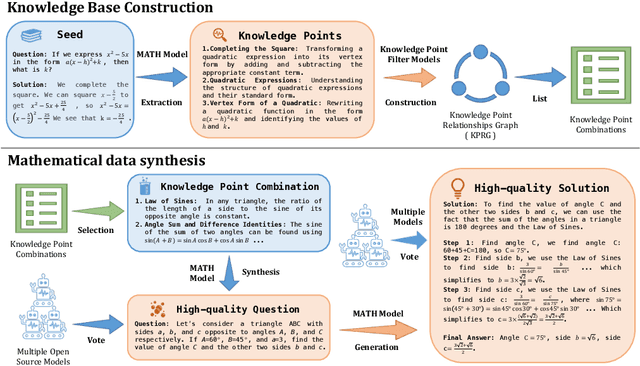
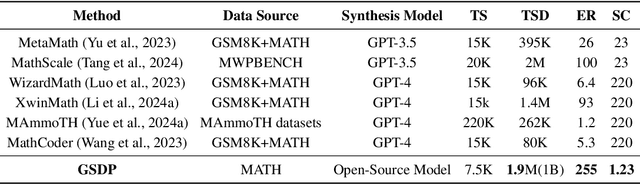
Synthesizing high-quality reasoning data for continual training has been proven to be effective in enhancing the performance of Large Language Models (LLMs). However, previous synthetic approaches struggle to easily scale up data and incur high costs in the pursuit of high quality. In this paper, we propose the Graph-based Synthetic Data Pipeline (GSDP), an economical and scalable framework for high-quality reasoning data synthesis. Inspired by knowledge graphs, we extracted knowledge points from seed data and constructed a knowledge point relationships graph to explore their interconnections. By exploring the implicit relationships among knowledge, our method achieves $\times$255 data expansion. Furthermore, GSDP led by open-source models, achieves synthesis quality comparable to GPT-4-0613 while maintaining $\times$100 lower costs. To tackle the most challenging mathematical reasoning task, we present the GSDP-MATH dataset comprising over 1.91 million pairs of math problems and answers. After fine-tuning on GSDP-MATH, GSDP-7B based on Mistral-7B achieves 37.7% accuracy on MATH and 78.4% on GSM8K, demonstrating the effectiveness of our method. The dataset and models trained in this paper will be available.
ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection
Apr 10, 2020

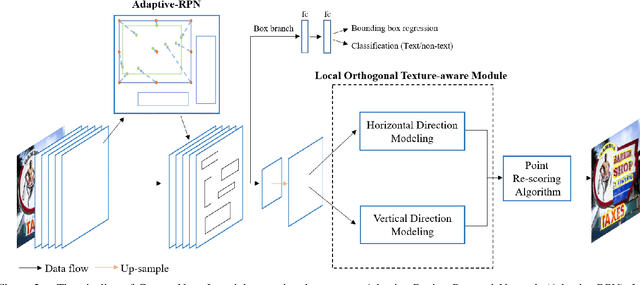
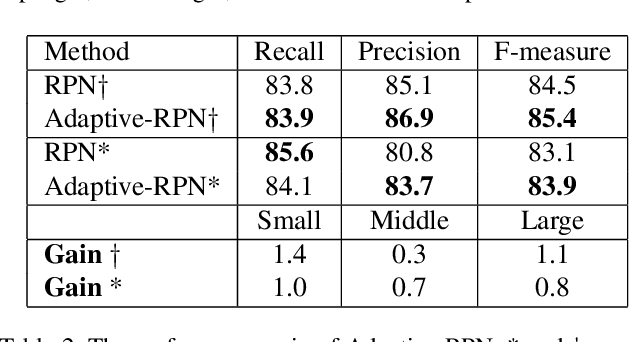
Scene text detection has witnessed rapid development in recent years. However, there still exists two main challenges: 1) many methods suffer from false positives in their text representations; 2) the large scale variance of scene texts makes it hard for network to learn samples. In this paper, we propose the ContourNet, which effectively handles these two problems taking a further step toward accurate arbitrary-shaped text detection. At first, a scale-insensitive Adaptive Region Proposal Network (Adaptive-RPN) is proposed to generate text proposals by only focusing on the Intersection over Union (IoU) values between predicted and ground-truth bounding boxes. Then a novel Local Orthogonal Texture-aware Module (LOTM) models the local texture information of proposal features in two orthogonal directions and represents text region with a set of contour points. Considering that the strong unidirectional or weakly orthogonal activation is usually caused by the monotonous texture characteristic of false-positive patterns (e.g. streaks.), our method effectively suppresses these false positives by only outputting predictions with high response value in both orthogonal directions. This gives more accurate description of text regions. Extensive experiments on three challenging datasets (Total-Text, CTW1500 and ICDAR2015) verify that our method achieves the state-of-the-art performance. Code is available at https://github.com/wangyuxin87/ContourNet.